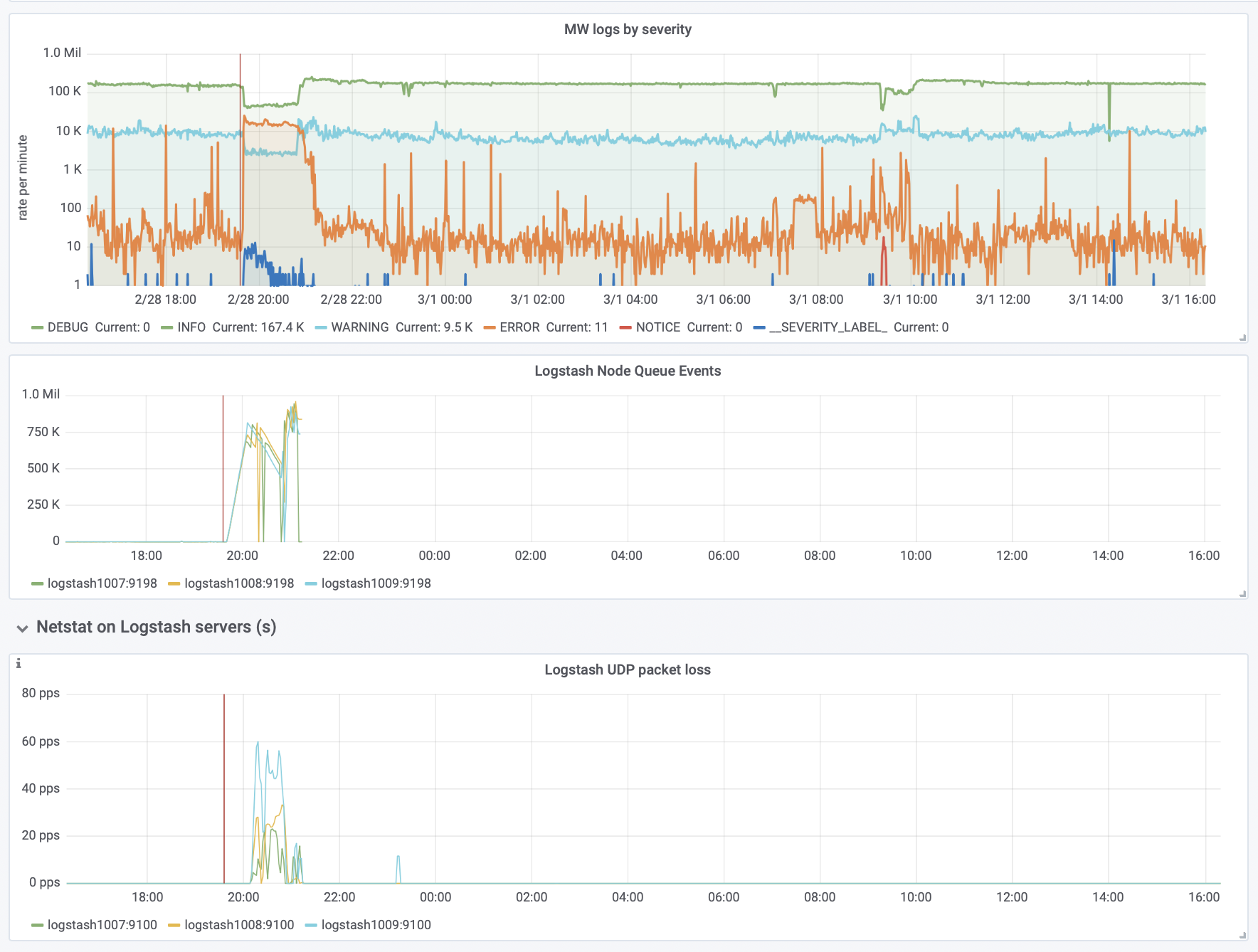
Today db1114 went down (T214720) and even though the LB worked great (T180918 - thanks!!) MW still logged millions of errors (https://logstash.wikimedia.org/goto/0121ecd09eca77276c4af8bcde8dc2a2)
It caused logstash to lag behind and had packet loss whilst the issue lasted:
Dashboard: https://grafana.wikimedia.org/d/000000561/logstash?orgId=1&from=1549625552953&to=1549632990689&var-input=kafka%2Frsyslog-udp-localhost
Packet loss: https://grafana.wikimedia.org/d/000000561/logstash?orgId=1&from=1549622528006&to=1549633328006&var-input=kafka%2Frsyslog-udp-localhost
Input increase: https://grafana.wikimedia.org/d/000000561/logstash?orgId=1&from=1549622564189&to=1549633364189&var-input=kafka%2Frsyslog-udp-localhost
We should probably do something about this and try to rate limit the amount of verbosity or logging for MW for a given event or something.
This task aims to start a discussion about how this can be better handled in the future as unfortunately hardware can always fail and this scenario will happen sooner or later.