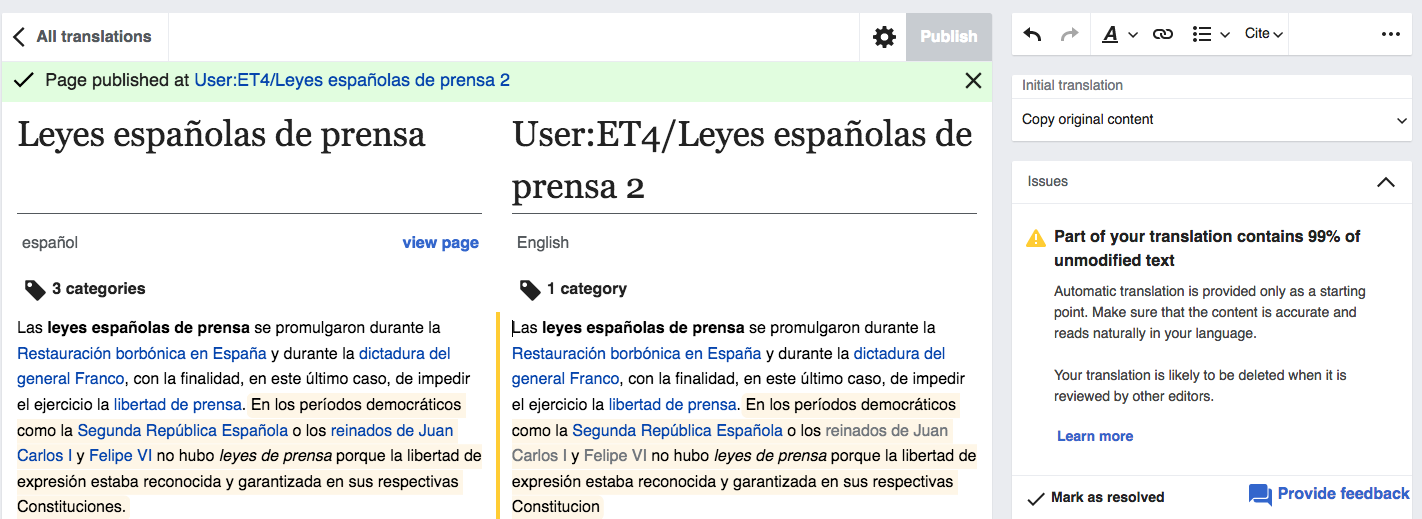
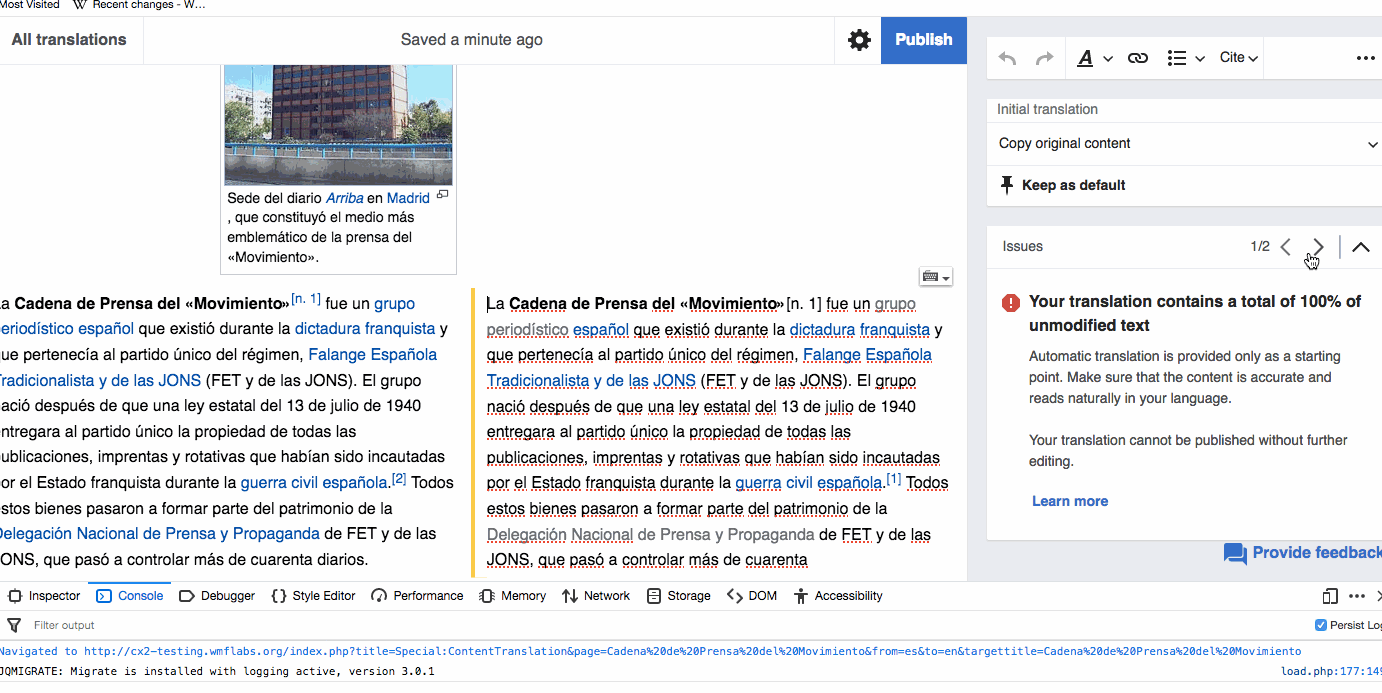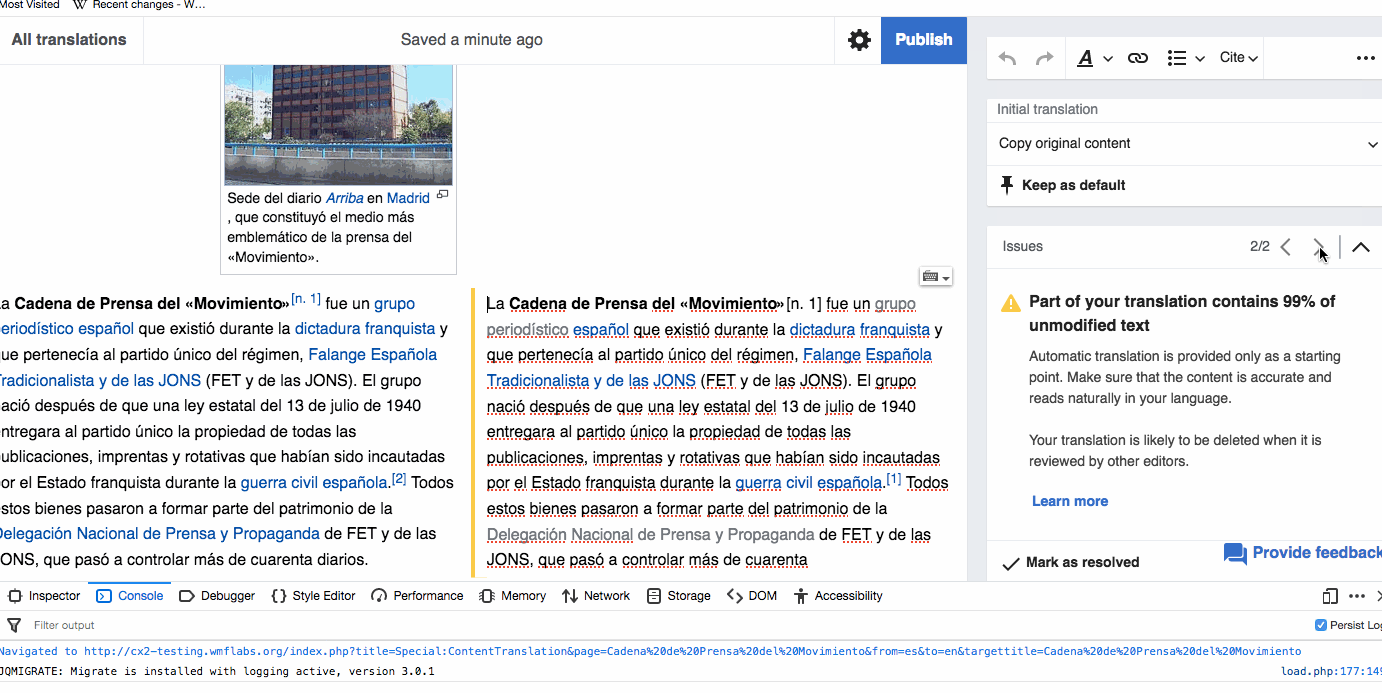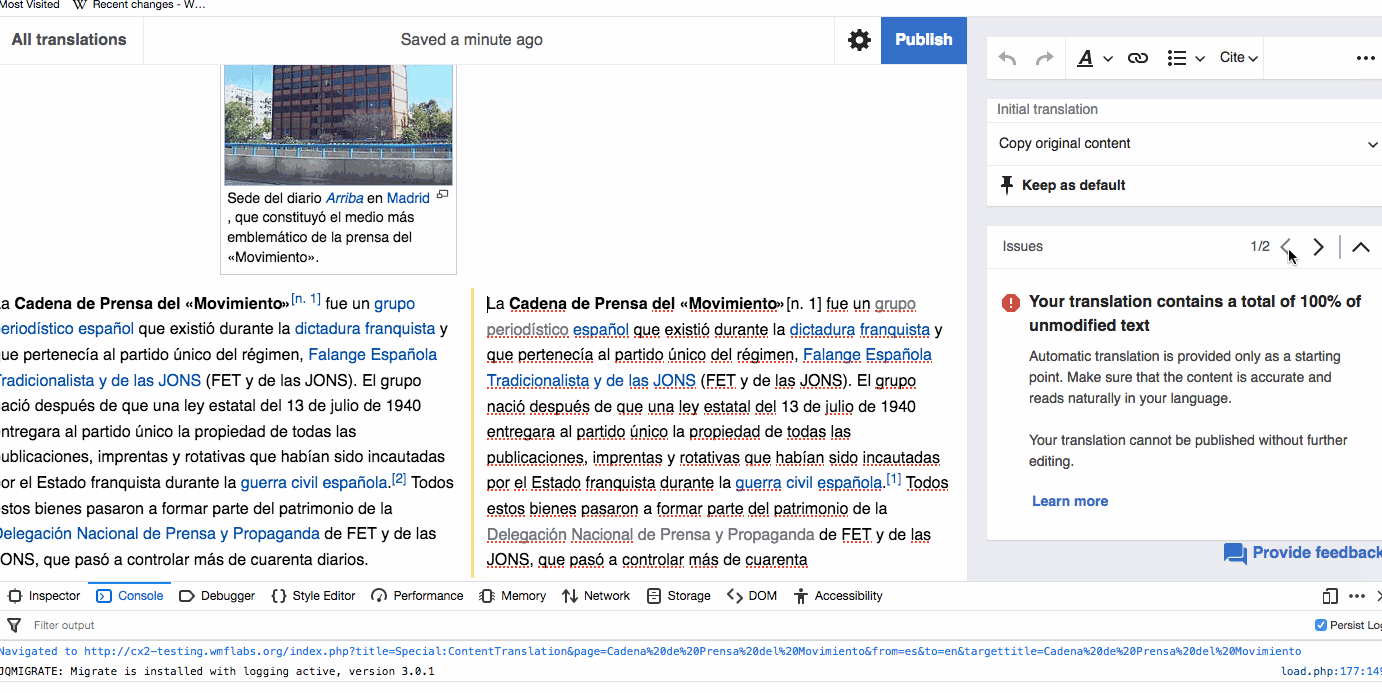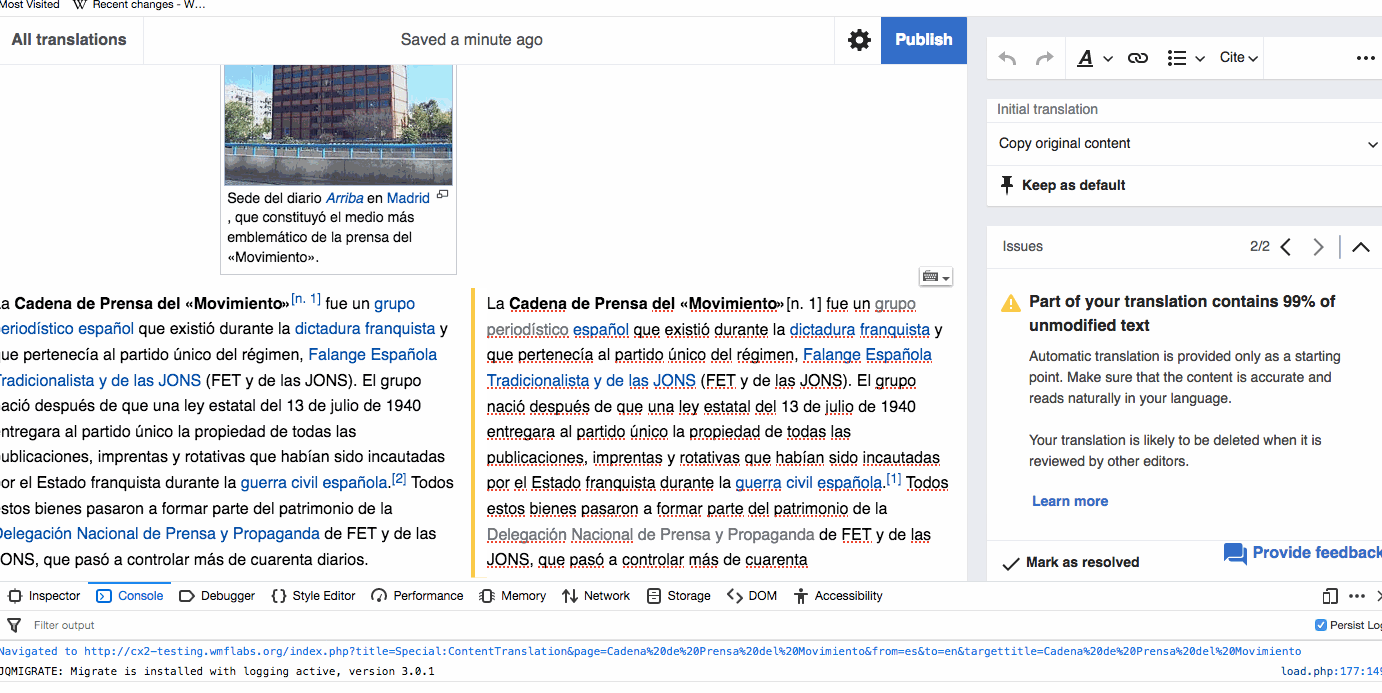
Translations that are published with paragraphs containing too much unmodified content (80% of Machine translation or 60% of source content) are published in a tracking category for the community to review (T211763, T190798). We want the tracking category to be useful: not too broad to include too many false positives, not too narrow or including holes for problematic articles to be skipped. Based on feedback and casual observations, further adjustments seem to be needed.
The problem
The tracking category on French Wikipedia seems to accumulates articles that were apparently published without issues.
For languages with no MT, many unreviewed articles in the category do not seem to contain significant portions of text in the source language (this may have been fixed by T215591). Feedback from an editor in the Arabic community (T211571#4996154) suggested further adjustments may be needed to make the category more relevant.
Proposed solutions
We want to try the following adjustments:
- Consider a less strict threshold for paragraphs that users marked as resolved. For paragraphs where the unmodified content warning was shown but the user marked it as resolved, we can apply a less strict threshold (95% of Machine translation or 75% of source content). This will provide a way to accommodate cases where the automatic translation was exceptionally good, but still avoid potential abuse of the feature (i.e., not following blindly the user confirmation).
- Consider more than one problematic paragraph for adding to the category. Currently a translation is added to the tracking category with just one problematic paragraph. We may want to consider more than one paragraph to make the approach a bit less sensitive to false positives.
(Additional adjustments can be considered to the thresholds or how they are applied based on further discussions and evaluation)
Evaluation
We want to evaluate the improvements of each approach in a rigorous way. One possible approach could be to Inspect articles in the tracking category to identify two groups: (a) false positives (articles that are perfectly fine but were included in the tracking category), and (b) truly problematic (articles that were not reviewed enough).
Once an approach (or a combination) is tested we can re-evaluate the articles from the defined groups to identify which is the approach that minimizes false positives while keeping the truly problematic translations in the tracking category.
When inspecting the articles we need to pay special attention, identify which are the paragraphs that were exceeding the thresholds in Content translation. This will help identify new possible strategies to consider (e.g., excluding certain kinds of content). We may also need input from native speakers to make sure the article classification is accurate.
Related: T209868: Extend translations graph to show also published translations that need review