See the network log from Firefox (also reproducible on other browsers):
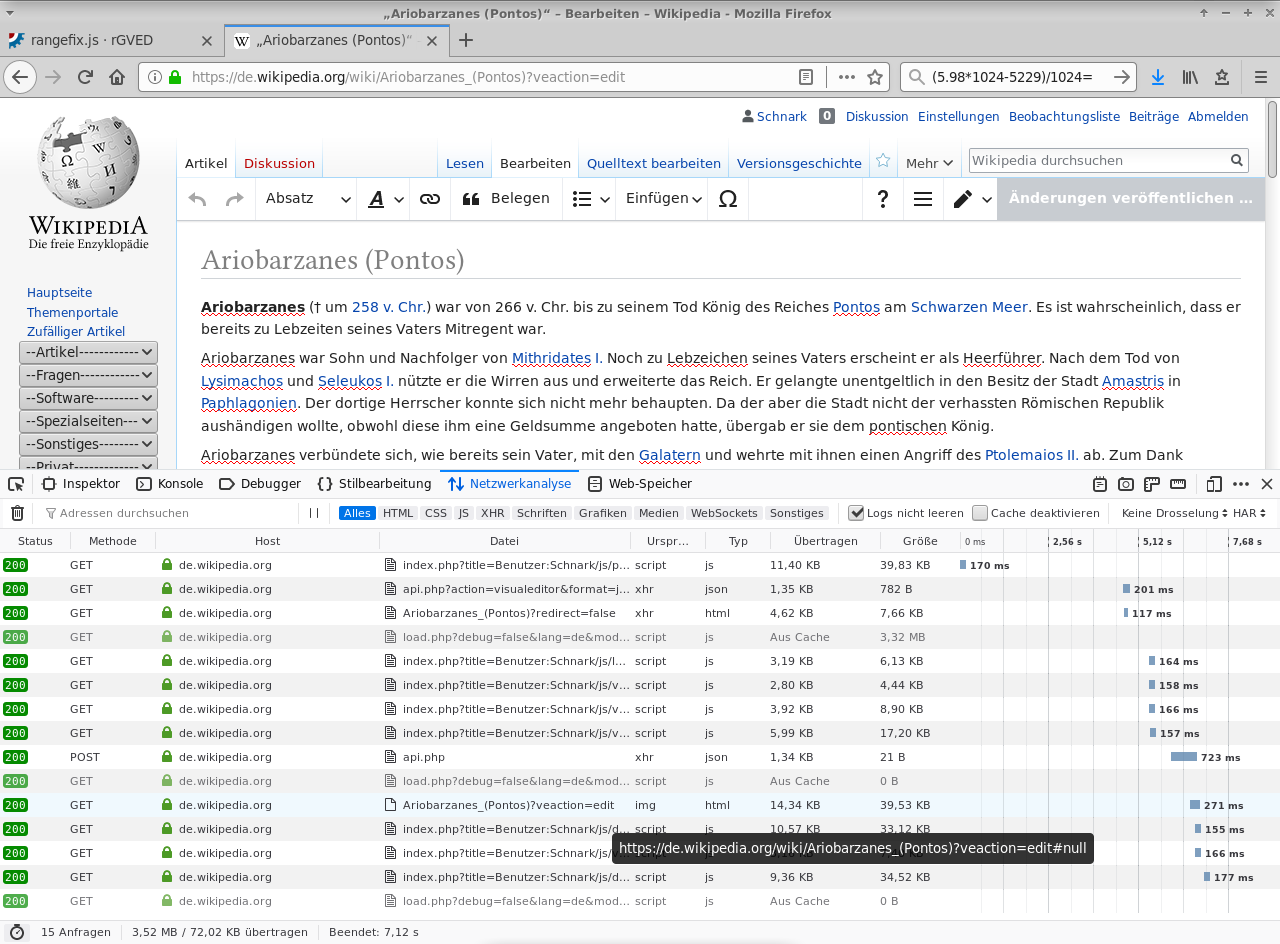
There is an entry with source "img", type "text/html", and URL "#null", which indicates downloading of a large amount HTML. At that point that HTML is already loaded, and additionally this second load tries to interpret the HTML as image.
This is caused by the rangeFix library, which creates an image with URL "#null" (https://phabricator.wikimedia.org/diffusion/GVED/browse/master/lib/rangefix/rangefix.js$54).
I don't know what the library is trying to do with that image, but it certainly should do it in a way that doesn't force the client to download that HTML again.