We would like to test the performances of the GPU on stat1005 with an end-to-end training task for image classification.
Inspired by @Gilles' idea in T215413, I will try to build a classifier that distinguishes photos from graphics (diagrams, maps, etc)
- Collect data from graphics and photo Commons categories -- important to time this as we have to estimate how much of a bottleneck this stage is (see T215250)
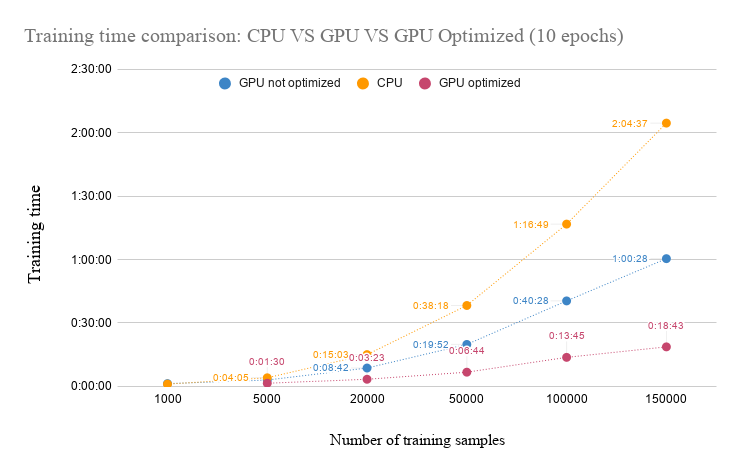
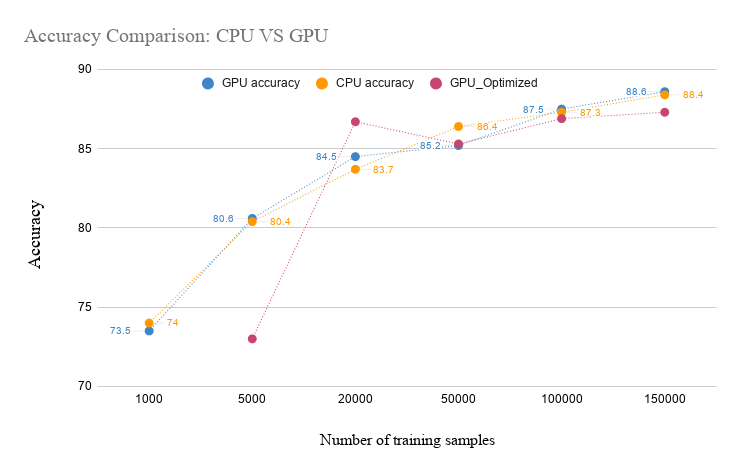
- Train the model on stat1005 with GPU (using simple architecture for now)
- Evaluate the model in terms of accuracy and computation time
- Repeat the training using CPU only and compare time/accuracy performances
- [optional] repeat everything using with a pre-trained model, and compre time/accuracy performances