During the 2019-20 fiscal year the Language team plans to support Section translation ( check the General concept and the initial design ideas) as part of the Translation Boost initiative. That is, supporting users to expand existing articles by translating a new section from another language. For example, we want to make it easy to expand the "Ukulele" article in Tagalog by translating the "history" section from English.
This ticket provides an overview of current and future research work that could help in this context. The areas below describe the support needed, in which ways such support would help, and fallback approaches that can be applied while the necessary capabilities are not yet available.
Section mappings
Sections of an article represent relevant aspects of a topic. We want to present for a given article and a language pair which are the sections that are present and missing on each version. In this way, users can select which aspects to expand by translating from another language. The example below shows that "history" is a section present in English but missing in Tagalog for the Ukulele article:
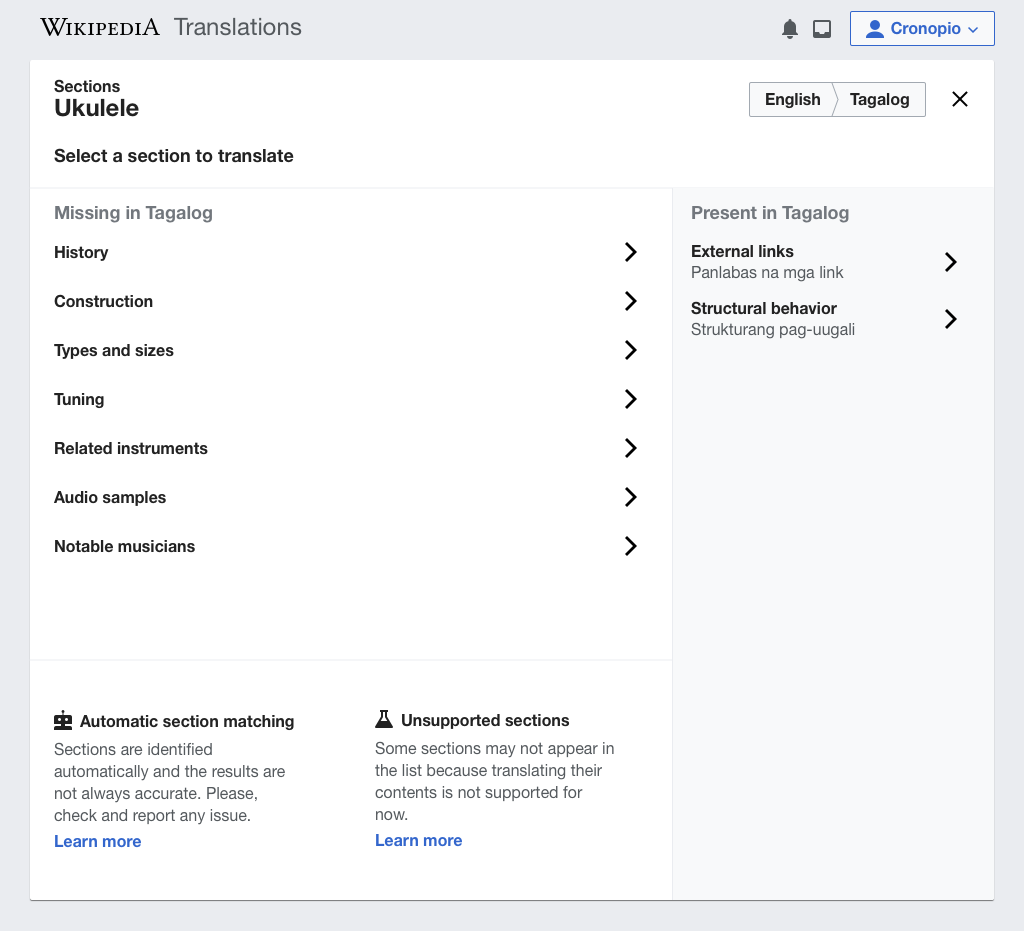
Status and fallbacks
There has been work already from research to identify relevant missing sections that users can add to an article based on those present in other languages. Initial discussions suggest, that this work can be repurposed to identify sections that exist in one given language and are missing in another one.
Until this approach is available, simpler (although limiting) approaches can be used to prevent this work to be blocker:
- Focus on target articles with no sections at all, to make sure that any section present in another language is not there.
- Focus on articles that were created with Content translation where no additional sections were added after they were published. In this way the section mapping is already available.
- Let the users check (and report) if the page contains a given section.
Suggestions for sections
In addition to letting users picking a specific article to expand with a new section, we want to surface suggestions that users can translate. That is, we want to surface the opportunity to translate the history section of the Ukulele article in the same way we are currently surfacing opportunities to translate new articles in content translation. The idea is illustrated below (note how the suggestions list include two parts: "new pages" and "expand with new sections" ):
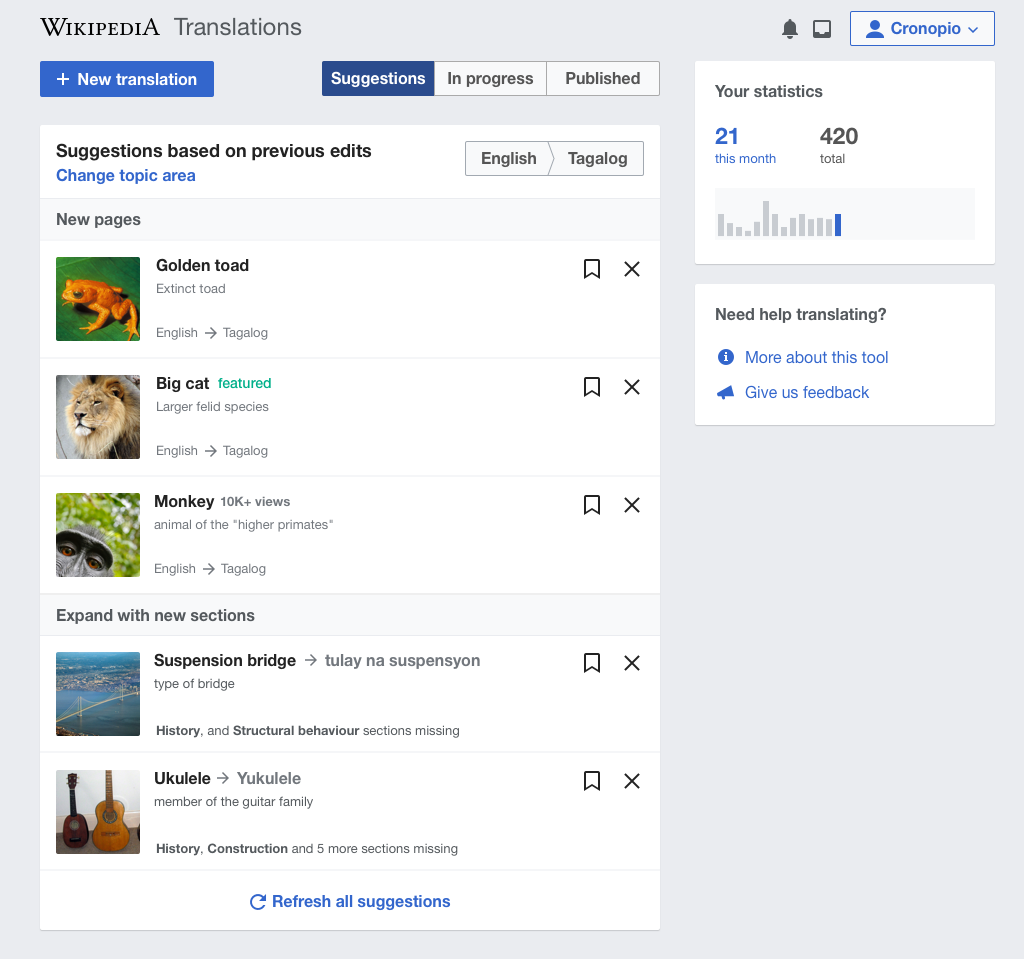
Status and fallbacks
Currently, only articles missing in the target language are surfaced in the recommendation system.
A possible fallback would be to suggest missing sections for:
- translations that the user has created previously (more targeted to encourage the user to continue the work rather than help discover new topics)
- articles featured in the source language that are present in the target language as non-featured (as an indicator of the potential for expansion)
Other related aspects
There are two additional aspects that may intersect with the work above and Research can help with:
- Section relevance. How we determine which sections are relevant for being translated. This can inform how we present sections to translate, suggest them or notify users that a new section has been created that is worth translating.
- Custom suggestions. We are exploring how the current suggestions can focus on a particular topic area. That is, exposing a catalog of topics (Geography, Mats, etc.) for users to select. This is something that could be supported in the current recommendation system by using a seed article, but a similar need would arise for suggested sections.