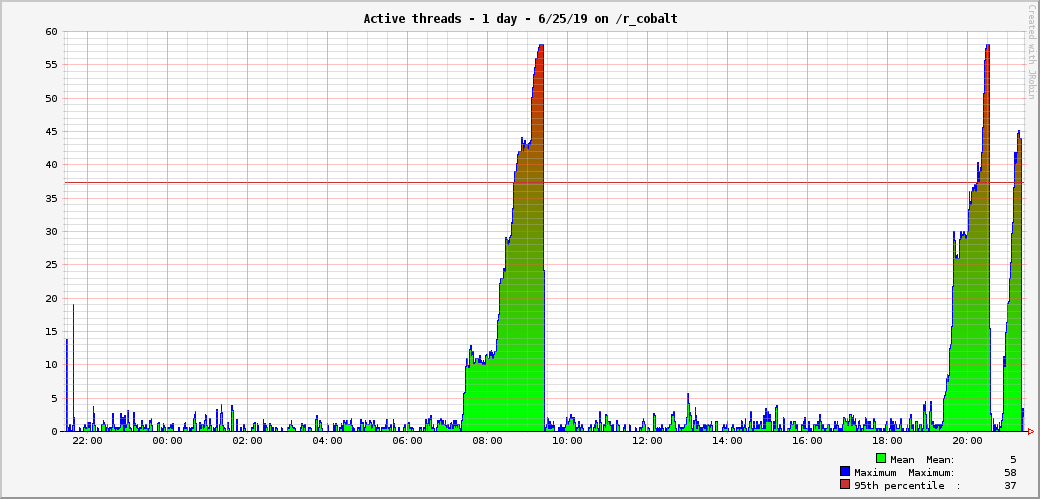
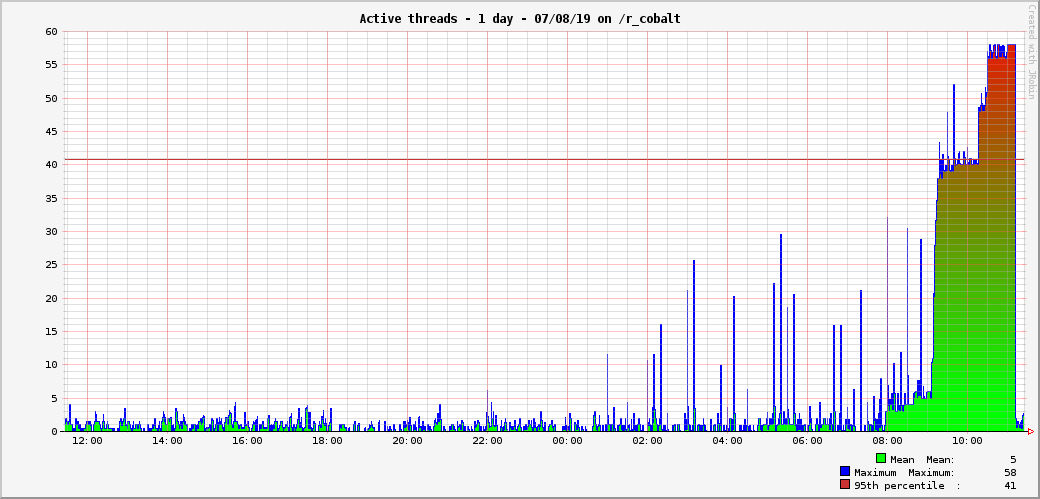
Symptoms:
- Gerrit is not responsive
- Thread count skyrocketted
- Monitoring probe Gerrit Health Check on gerrit.wikimedia.org is CRITICAL
Most probably indicate that HTTP threads are all deadlocked waiting for a lock that is never release. An obvious symptom is a SendEmail task being stuck (from ssh -p 29418 gerrit.wikimedia.org gerrit show-queue -w -q.
Upstream tasks:
- Gerrit lock and Caffeine migration:
- Guava (com.google.common.cache): https://github.com/google/guava/issues/3602
Workaround:
Restart Gerrit :-\
ssh cobalt.wikimedia.org sudo systemctl restart gerrit
And log:
!log Restarting Gerrit T224448
Gerrit threads have been getting stuck behind a single thread SendEmail
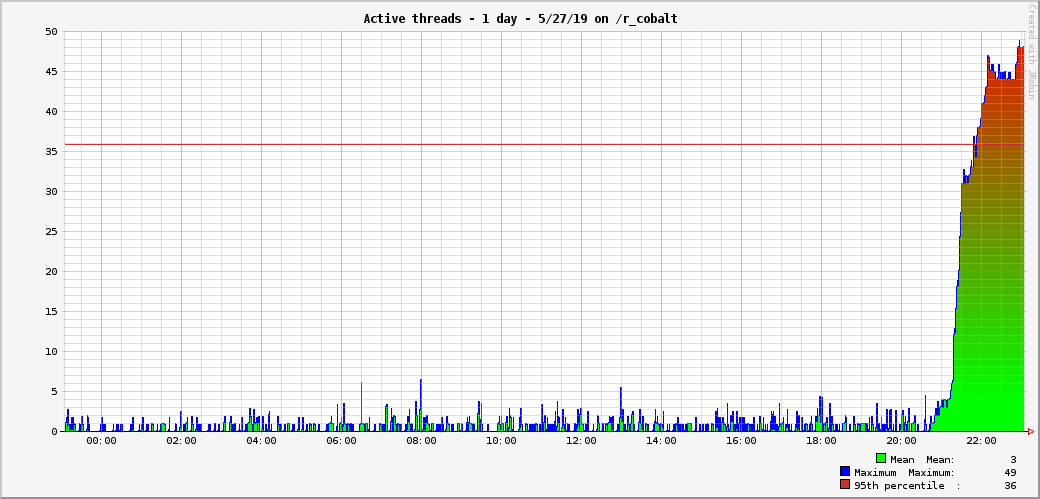
(see the threaddump: https://fastthread.io/my-thread-report.jsp?p=c2hhcmVkLzIwMTkvMDUvMjcvLS1qc3RhY2stMTktMDUtMjctMjItNTItNTIuZHVtcC0tMjItNTMtMjA=)
The only way to resolve this issue is to restart Gerrit.
This issue is superficially similar to T131189; however:
- send-email doesn't show up in gerrit show-queue -w --by-queue (tried using various flags)
- lsof for the gerrit process at the time of these problems didn't show any smtp connections
I've tried killing the offending thread via the JavaMelody interface to no avail.
Ongoing upstream discussion: https://groups.google.com/forum/#!msg/repo-discuss/pBMh09-XJsw/vuhDiuTWAAAJ
Summary by @hashar
- parking to wait for <0x00000006d75ed7e0> (a java.util.concurrent.locks.ReentrantLock$NonfairSync) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175) at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836) at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireQueued(AbstractQueuedSynchronizer.java:870) at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:1199) at java.util.concurrent.locks.ReentrantLock$NonfairSync.lock(ReentrantLock.java:209) at java.util.concurrent.locks.ReentrantLock.lock(ReentrantLock.java:285) at com.google.common.cache.LocalCache$Segment.lockedGetOrLoad(LocalCache.java:2089) at com.google.common.cache.LocalCache$Segment.get(LocalCache.java:2046) at com.google.common.cache.LocalCache.get(LocalCache.java:3943) at com.google.common.cache.LocalCache.getOrLoad(LocalCache.java:3967) at com.google.common.cache.LocalCache$LocalLoadingCache.get(LocalCache.java:4952) at com.google.gerrit.server.account.AccountCacheImpl.get(AccountCacheImpl.java:85) at com.google.gerrit.server.account.InternalAccountDirectory.fillAccountInfo(InternalAccountDirectory.java:69) at com.google.gerrit.server.account.AccountLoader.fill(AccountLoader.java:91) at com.google.gerrit.server.change.ChangeJson.formatQueryResults(ChangeJson.java:
That is still in the local account cache, it might well just be a nasty deadlock bug in com.google.common.cache / Guava. Or the SendEmail thread has some bug and sometime fails to release the local account cache lock :-\ Which bring us back to Upstream bug https://bugs.chromium.org/p/gerrit/issues/detail?id=7645
it had a patch https://gerrit-review.googlesource.com/c/gerrit/+/154130/ but that got reverted https://gerrit-review.googlesource.com/c/gerrit/+/162870/ :-\