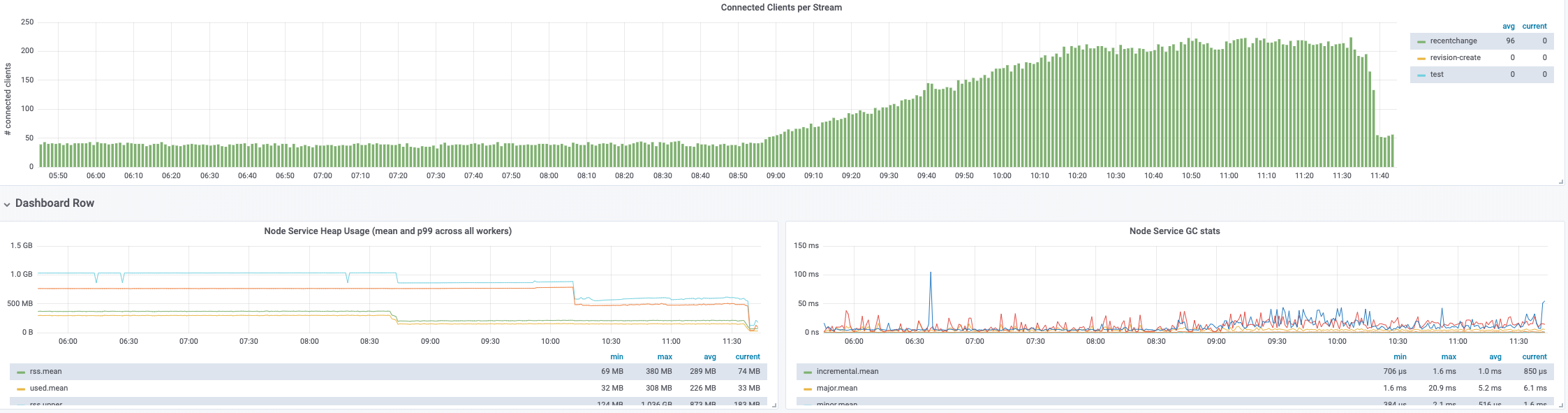
Hello everybody,
I noticed some SERVICE_UNKNOWN icinga alerts for all the eventstreams daemons on scb2*, and when I jumped on the hosts I found that:
- curl http://localhost:8092/v2/stream/recentchange timed out
- port 8092 didn't seem to be bound by any service
The issue seems to have started at 2019-06-27 at around 15:30 UTC. The logs around that time report:
{"name":"eventstreams","hostname":"scb2001","pid":28944,"level":40,"message":"Heap memory limit temporarily exceeded","limit":786432000,"memoryUsage":{"rss":905519104,"heapTotal":821465088,"h
eapUsed":787728896,"external":375775},"levelPath":"warn/service-runner/heap","msg":"Heap memory limit temporarily exceeded","time":"2019-06-27T15:20:49.081Z","v":0}
{"name":"eventstreams","hostname":"scb2001","pid":4628,"id":"3eabf172-98ef-11e9-af9e-f32d23fced49","level":30,"msg":"Creating new KafkaSSE instance 3eabf172-98ef-11e9-af9e-f32d23fced49.","tim
e":"2019-06-27T15:21:32.757Z","v":0}
{"name":"eventstreams","hostname":"scb2001","pid":28944,"level":40,"message":"Heap memory limit temporarily exceeded","limit":786432000,"memoryUsage":{"rss":906203136,"heapTotal":821465088,"h
eapUsed":788269760,"external":399475},"levelPath":"warn/service-runner/heap","msg":"Heap memory limit temporarily exceeded","time":"2019-06-27T15:21:49.083Z","v":0}
{"name":"eventstreams","hostname":"scb2001","pid":4628,"id":"3eabf172-98ef-11e9-af9e-f32d23fced49","level":50,"err":{"message":"broker transport failure","name":"Error","stack":"Error: Local:
Broker transport failure\n at Function.createLibrdkafkaError [as create] (/srv/deployment/eventstreams/deploy-cache/revs/07033d4d18f06cbe06dc69d8ebb9725bba16185f/node_modules/node-rdkafka
/lib/error.js:260:10)\n at /srv/deployment/eventstreams/deploy-cache/revs/07033d4d18f06cbe06dc69d8ebb9725bba16185f/node_modules/node-rdkafka/lib/client.js:339:28","code":-195},"msg":"broke
r transport failure","time":"2019-06-27T15:22:02.862Z","v":0}
{"name":"eventstreams","hostname":"scb2001","pid":4628,"id":"3eabf172-98ef-11e9-af9e-f32d23fced49","level":30,"msg":"Disconnecting.","time":"2019-06-27T15:22:02.862Z","v":0}
{"name":"eventstreams","hostname":"scb2001","pid":4628,"id":"3eabf172-98ef-11e9-af9e-f32d23fced49","level":30,"msg":"Closed HTTP request.","time":"2019-06-27T15:22:02.863Z","v":0}
{"name":"eventstreams","hostname":"scb2001","pid":23206,"id":"5d5ef44a-98ef-11e9-8a7a-3b80333ebd17","level":30,"msg":"Creating new KafkaSSE instance 5d5ef44a-98ef-11e9-8a7a-3b80333ebd17.","ti
me":"2019-06-27T15:22:24.262Z","v":0}
{"name":"eventstreams","hostname":"scb2001","pid":28944,"level":60,"message":"Heap memory limit exceeded","limit":786432000,"memoryUsage":{"rss":905822208,"heapTotal":823562240,"heapUsed":787
789352,"external":388893},"levelPath":"fatal/service-runner/heap","msg":"Heap memory limit exceeded","time":"2019-06-27T15:22:49.083Z","v":0}
{"name":"eventstreams","hostname":"scb2001","pid":23206,"id":"5d5ef44a-98ef-11e9-8a7a-3b80333ebd17","level":50,"err":{"message":"broker transport failure","name":"Error","stack":"Error: Local
: Broker transport failure\n at Function.createLibrdkafkaError [as create] (/srv/deployment/eventstreams/deploy-cache/revs/07033d4d18f06cbe06dc69d8ebb9725bba16185f/node_modules/node-rdkafk
a/lib/error.js:260:10)\n at /srv/deployment/eventstreams/deploy-cache/revs/07033d4d18f06cbe06dc69d8ebb9725bba16185f/node_modules/node-rdkafka/lib/client.js:339:28","code":-195},"msg":"brok
er transport failure","time":"2019-06-27T15:22:54.366Z","v":0}And then a lot of:
{"name":"eventstreams","hostname":"scb2001","pid":27327,"id":"b8dd28d2-98f2-11e9-b7b8-5fe9ebb59a43","level":50,"err":{"message":"broker transport failure","name":"Error","stack":"Error: Local: Broker transport failure\n at Function.createLibrdkafkaError [as create] (/srv/deployment/eventstreams/deploy-cache/revs/07033d4d18f06cbe06dc69d8ebb9725bba16185f/node_modules/node-rdkafka/lib/error.js:260:10)\n at /srv/deployment/eventstreams/deploy-cache/revs/07033d4d18f06cbe06dc69d8ebb9725bba16185f/node_modules/node-rdkafka/lib/client.js:339:28","code":-195},"msg":"broker transport failure","time":"2019-06-27T15:46:56.378Z","v":0}After a rolling restart everything restarted working as before. If I am not mistaken the service is running active/active, so it wasn't really great that all codfw was down for several hours :(
The only relevant action that I noticed on the SAL around that time was:
https://tools.wmflabs.org/sal/log/AWuZZBG4OwpQ-3PktaQH (kafka2001 -> kafka-main2001 swap)