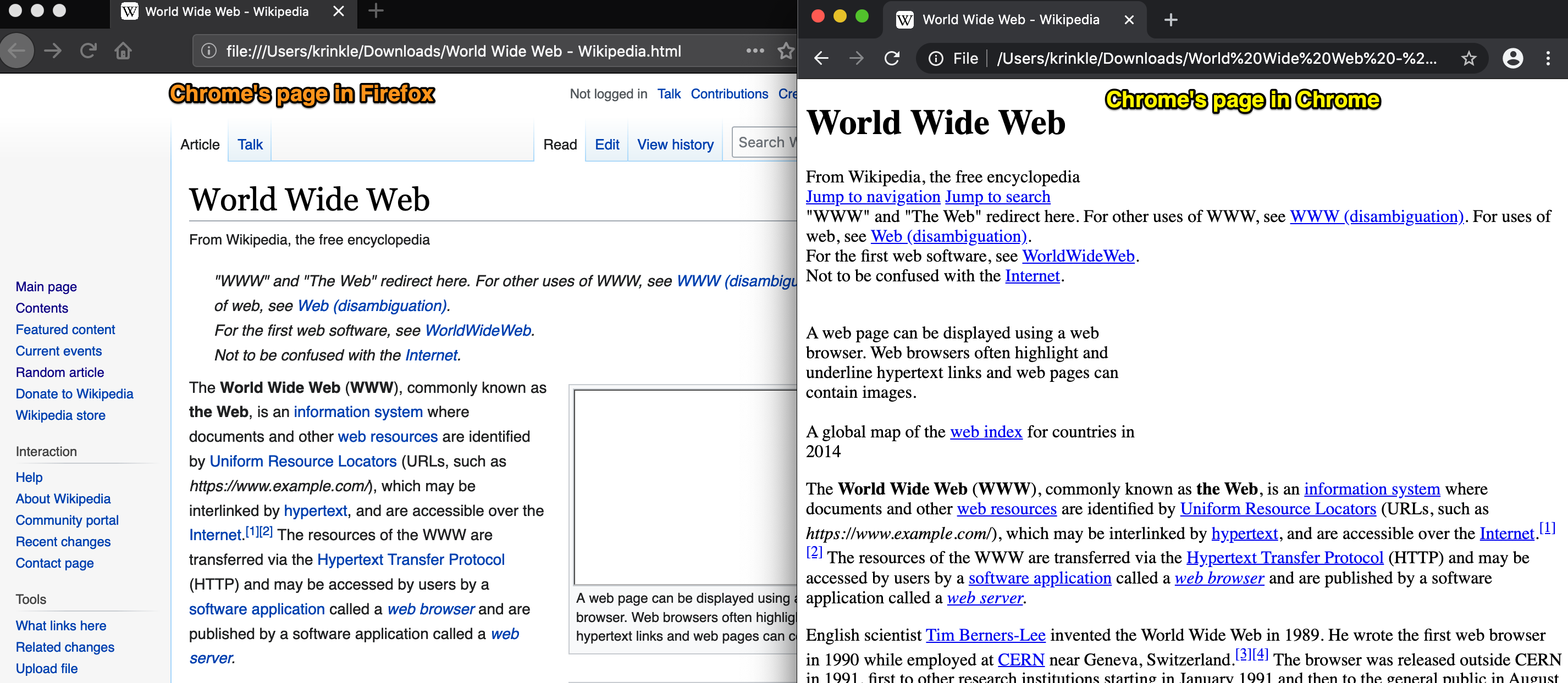
If you open a Wikipedia page in Chrome, and choose Save as... / Web Page, Complete from the right-click menu, then try to open to saved page, it will be barely readable (almost all CSS will break). This is due to ResourceLoader serving all CSS with a load.php filename - Chrome will save it as such, and then presumably use the file extension to guess content-type, and thus fail to interpret it as CSS. Given our focus on offline usage, breaking the most intuitive way of saving a page for offline usage in the most popular browser seems like a bad thing, and it seems reasonably easy to fix - just use URLs with the appropriate extension, ie. load.php/foo.css and load.php/bar.js (with a feature flag to disable in case the server does not support PATH_INFO).
(Via StackOverflow.)