The Incident
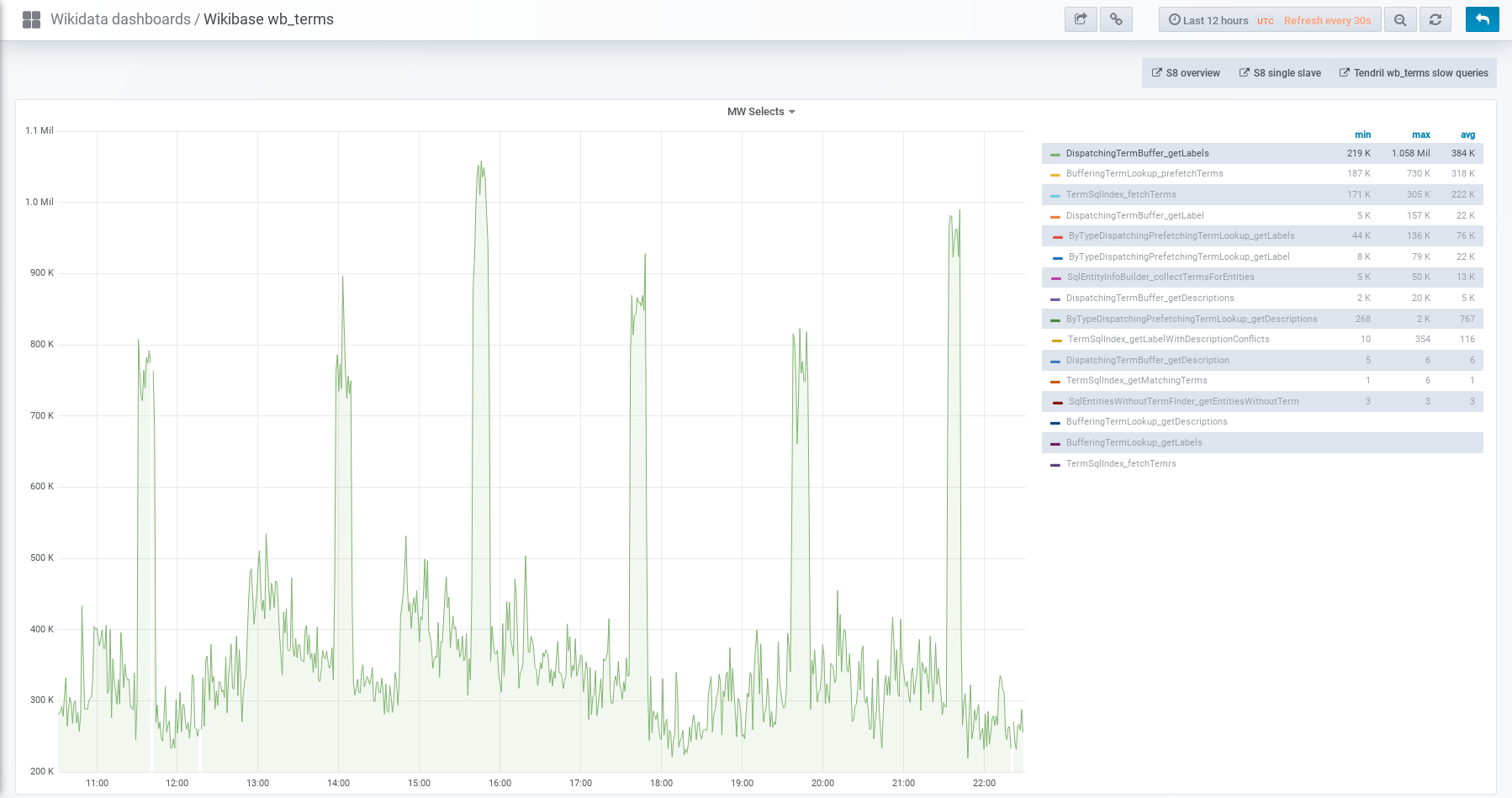
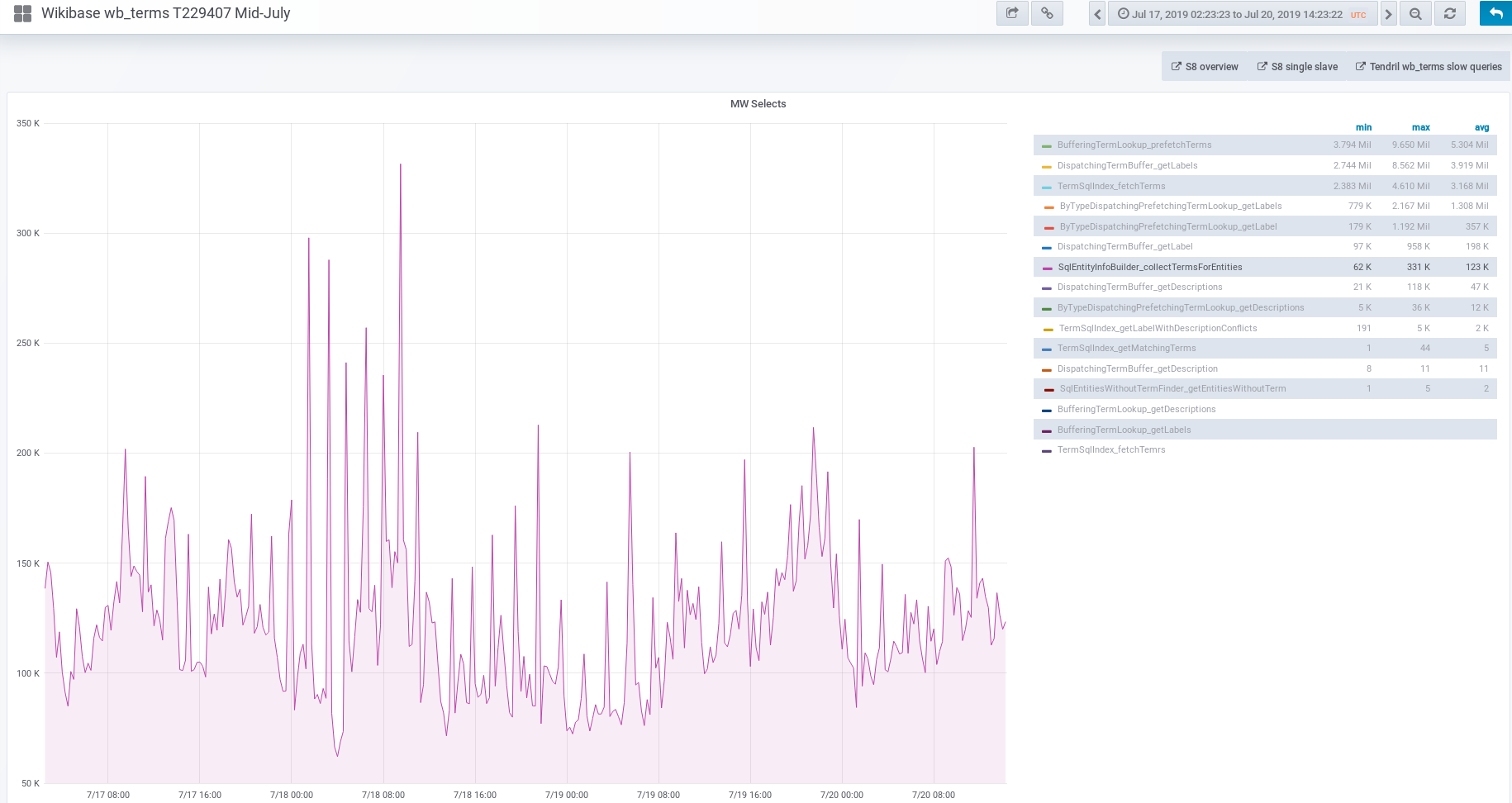
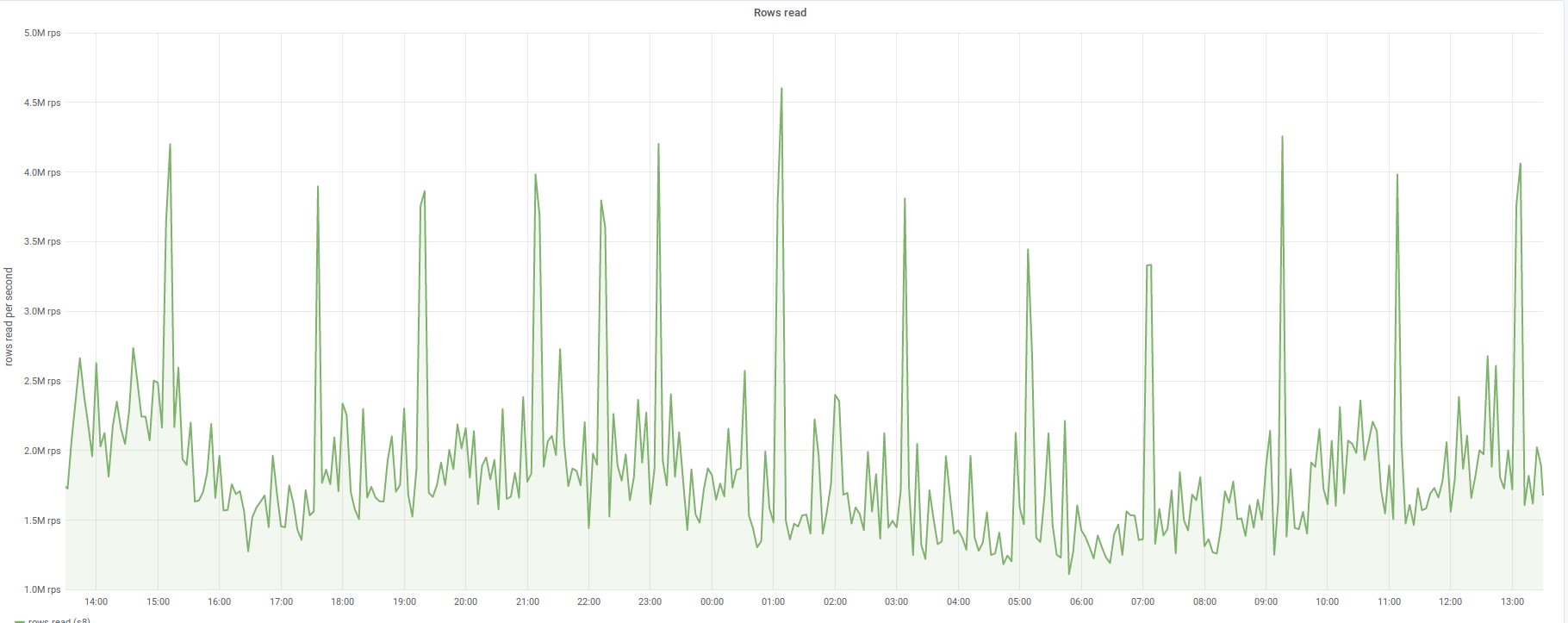
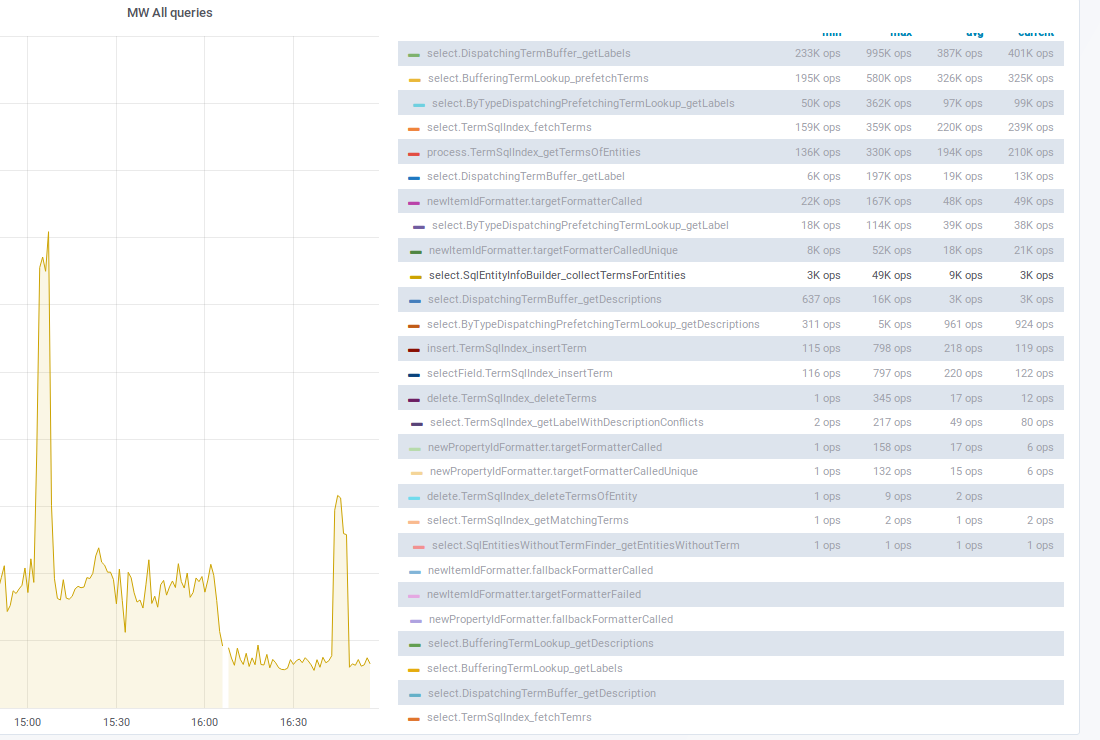
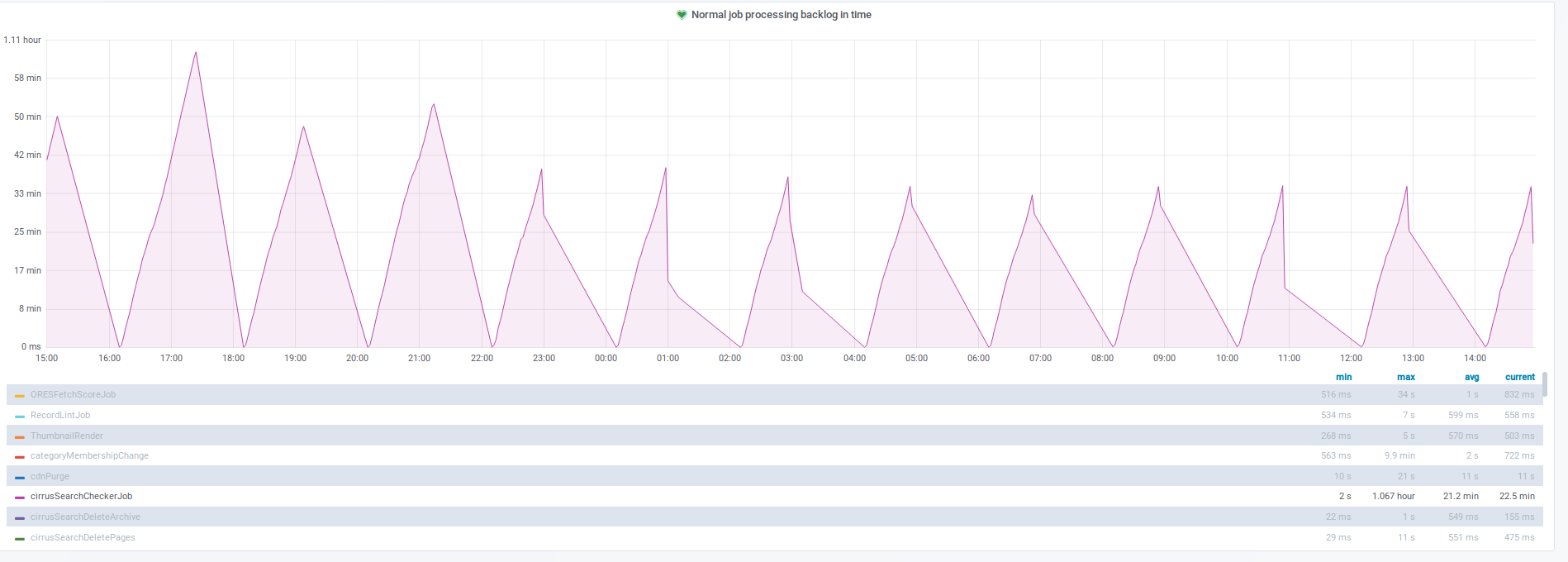
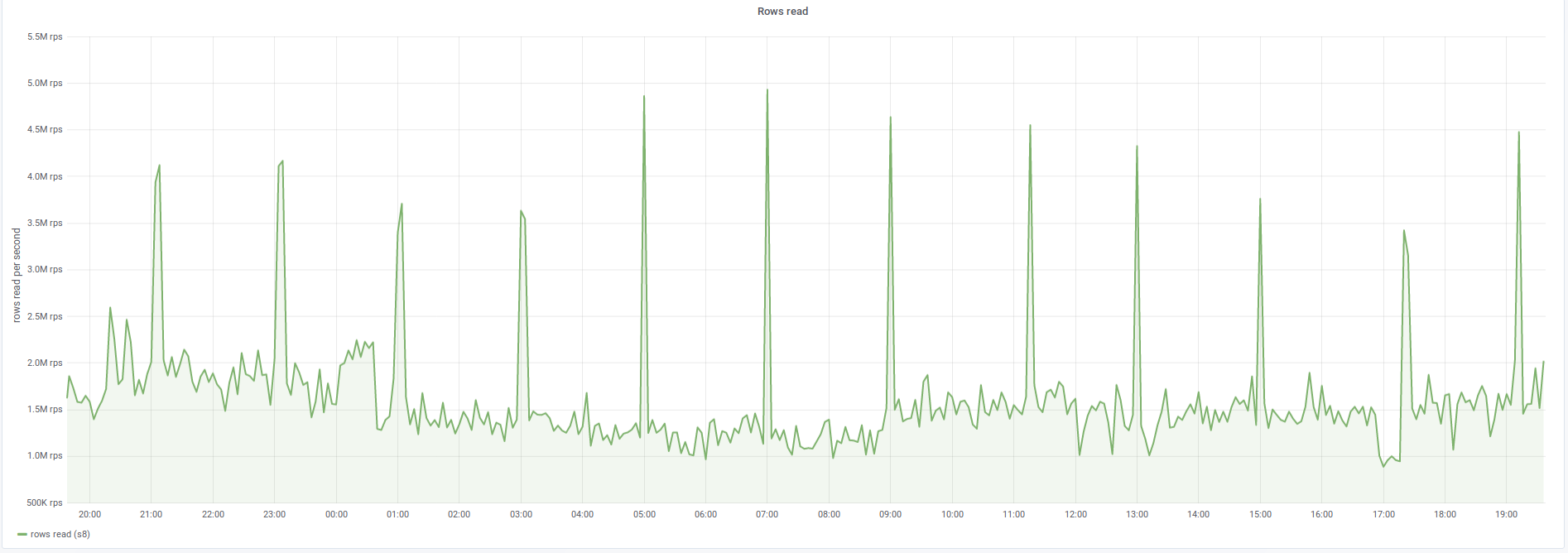
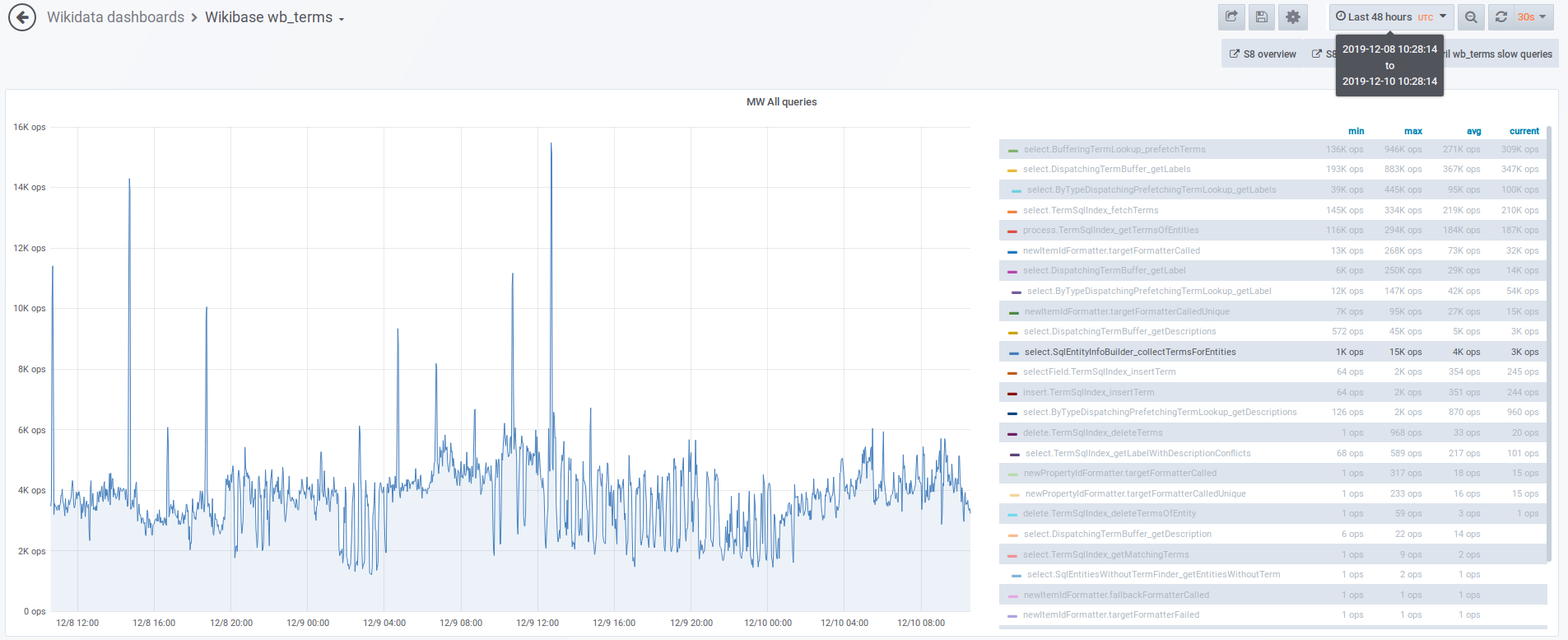
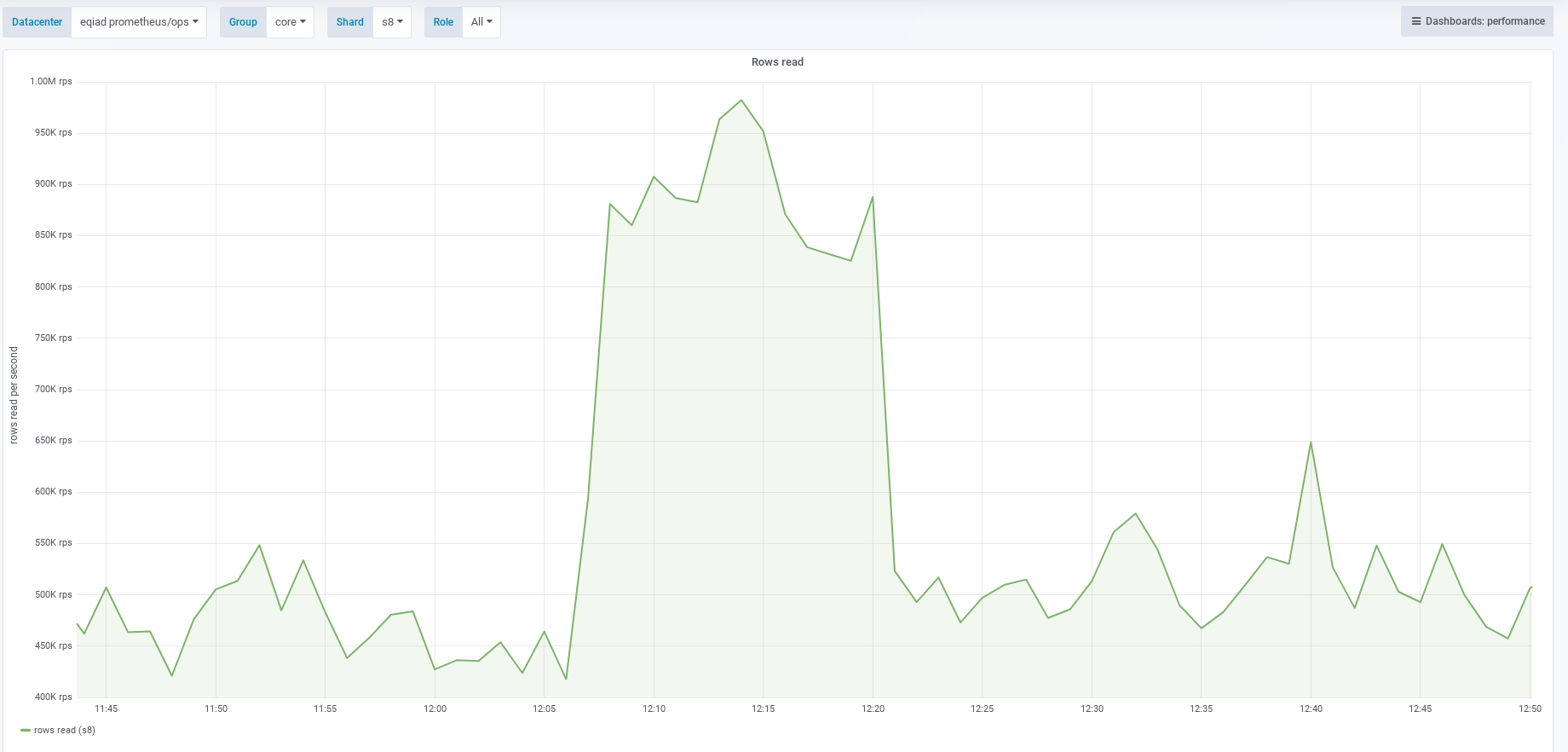
When we tried to enable reading property terms from new store T225053: Switch `tmpPropertyTermsMigrationStage` to MIGRATION_WRITE_NEW on production, the reading from the database increased dramatically, as seen here https://grafana.wikimedia.org/dashboard/snapshot/2kuWt7nhGDUdV3rAzYMPFYHMJ3poKf5C?panelId=8&fullscreen&orgId=1
The root cause
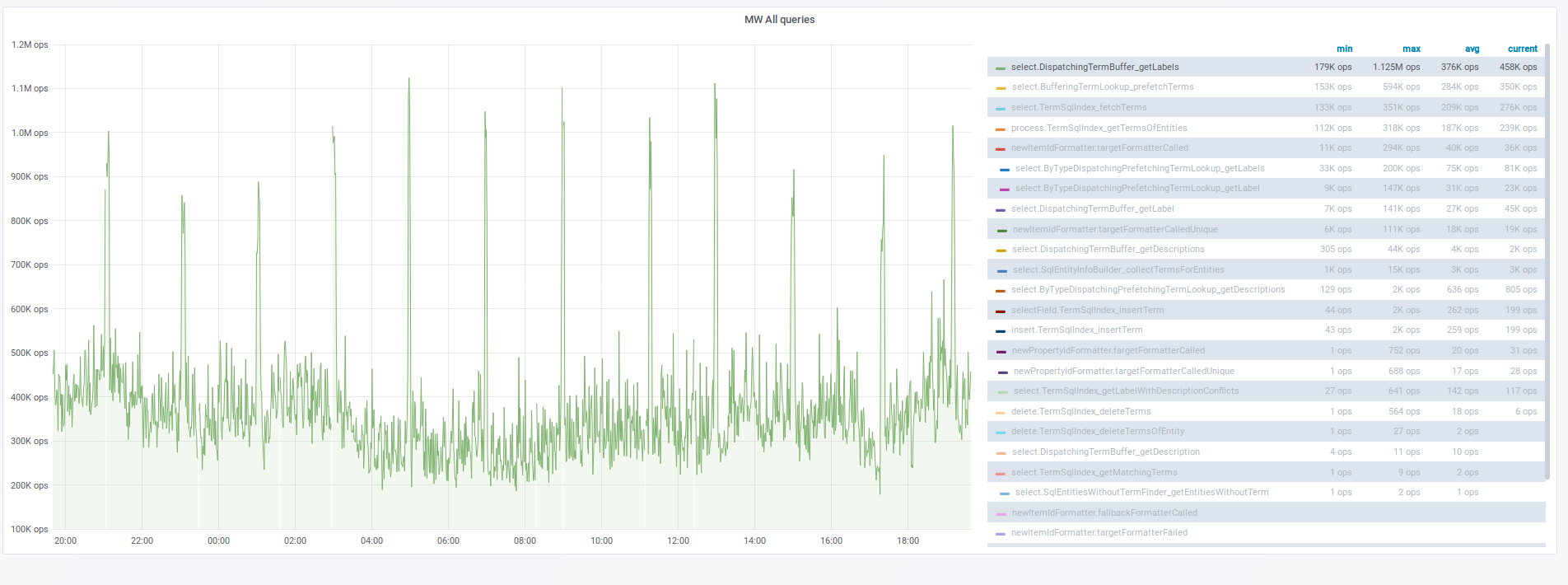
Our new PrefetchingPropertyTermLookup and PrefetchingItemTermLookup that are responsible for looking up Item/Property terms (main use case is rendering property/item labels in repo) do not use caching as their equivalent BufferingTermLookup for old store did.
Suggested solution
We have to wrap a cache around PrefetchingPropertyTermLookup and PrefetchingItemTermLookup.
We will use the same that was used for old term index for now MapCacheLRU with same buffer size and test to see if that reduces the increase in rows read per second.