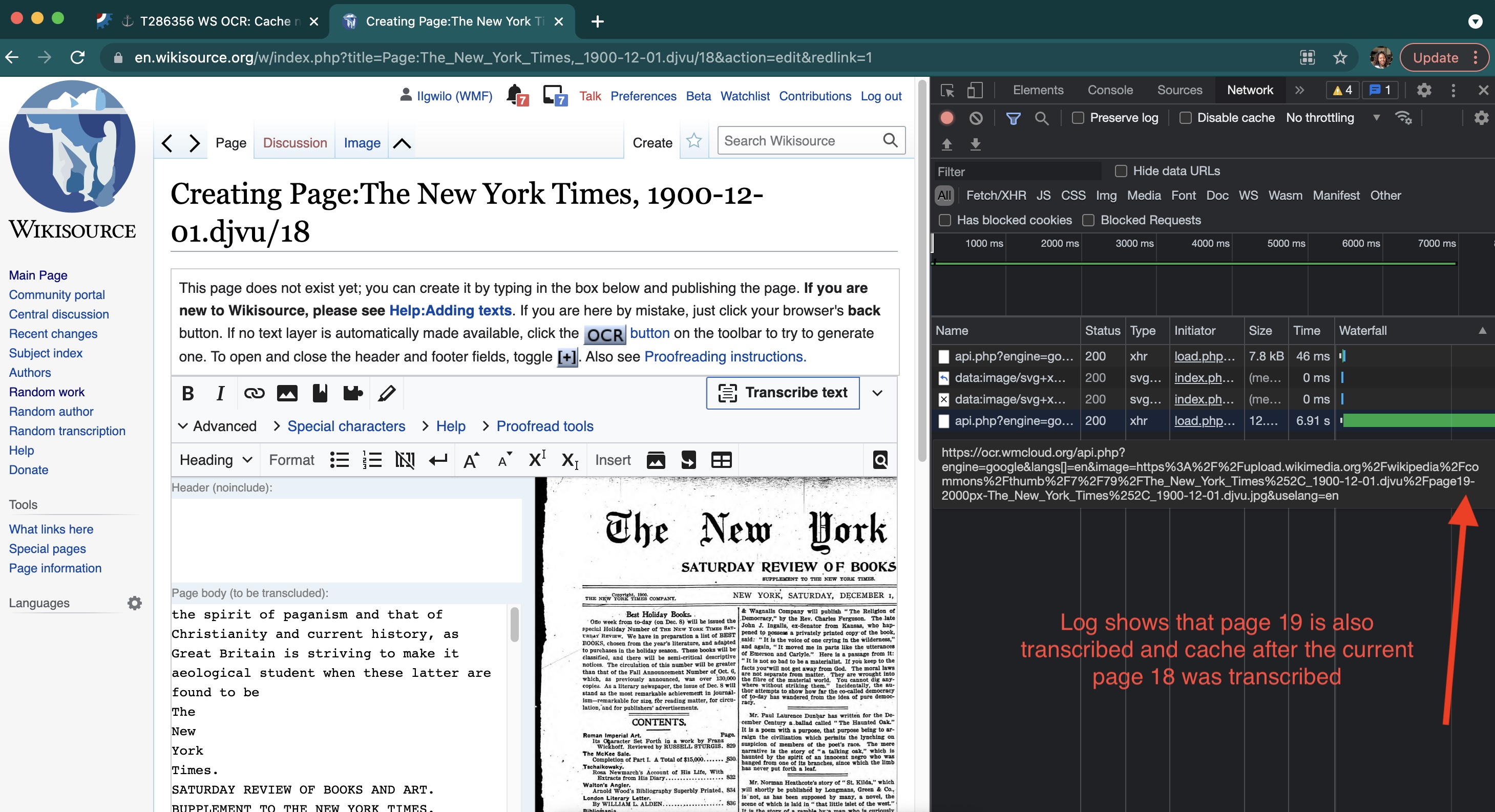
The Polish Wikisource preloads the next page's image while one is proofreading one page, which speeds up the load time significantly especially if you have lower bandwidth. It's implemented with a local gadget (not enabled by default for now).
https://wikisource.org/wiki/MediaWiki:Gadget-preload-prp-page-image.js
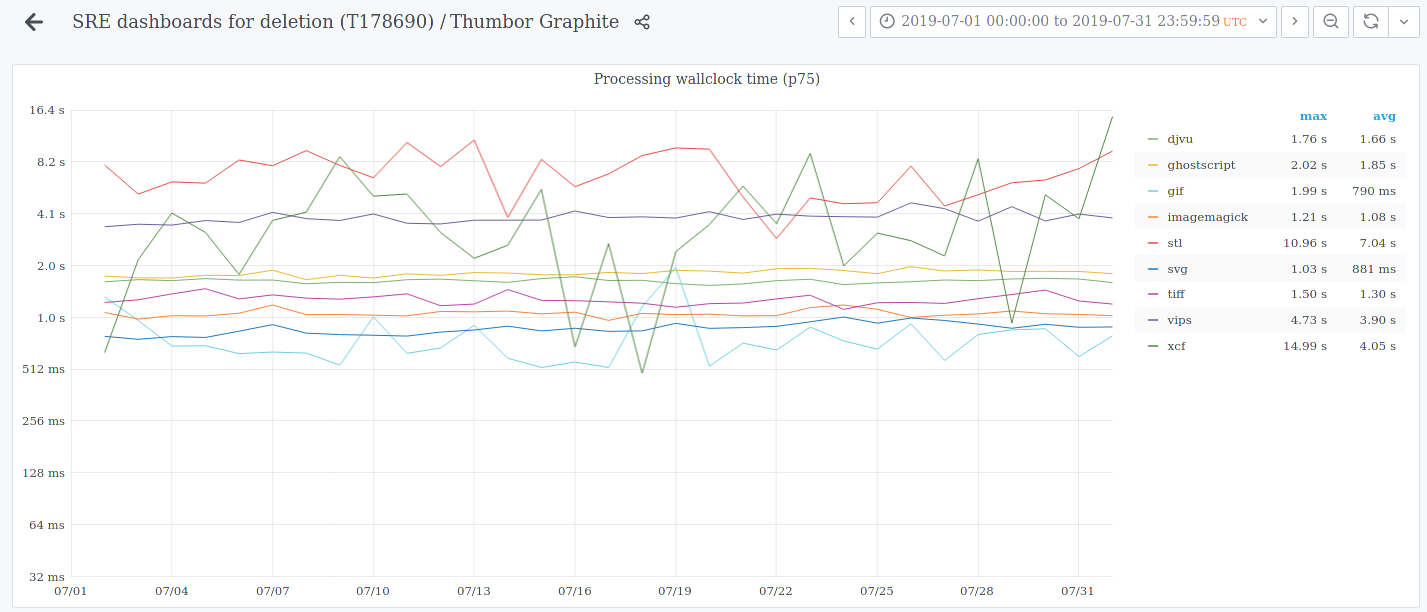
You could call it over-eager loading or prefetching. Otherwise, if indeed the thumbnail generation is the biggest part of the waiting time, especially for larger PDF/DjVu files and in some periods of the day when the imagescalers might be busier, it could be enough to request/generate the thumbnail server-side without loading it on the client, so it's ready on the cache.
Wikisource users at https://wikimania.wikimedia.org/wiki/2019:Transcription/Wrap-up and https://wikisource.org/wiki/Wikisource:Best_Practices have agreed this would be a feature worth implementing by default.