Project Name: integration
Type of quota increase requested: cpu/ram/instances
Amount of quota increase: more! (to be discussed)
Reason:
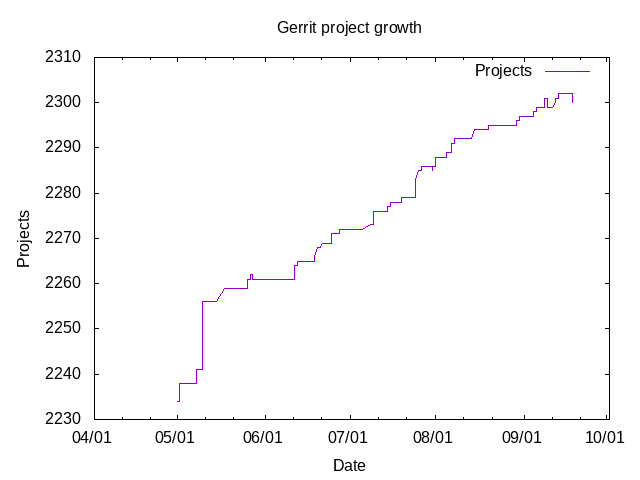
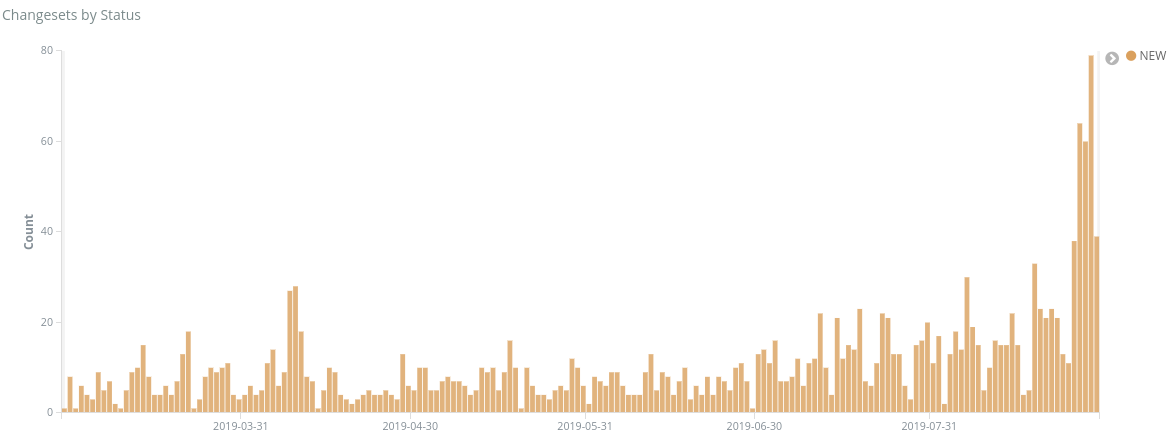
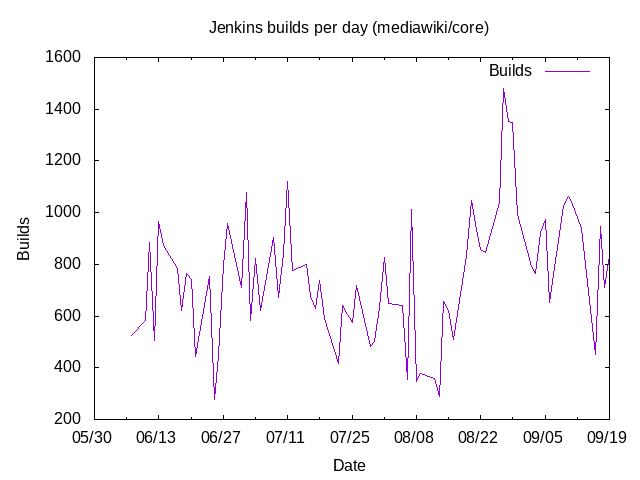
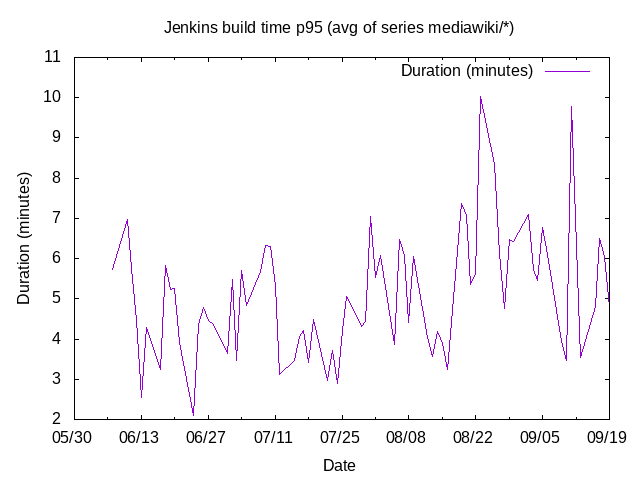
The integration WMCS projects hosts instances that run CI jobs. It has a large consumption and would typically spike on CPU usage during busy hours (european evening/west coast morning). But you all know about that already.
We could use a slight quota increase to have more executors available and thus be able to run more jobs in parallel. I have been holding that request until:
- we dropped php7.0/php7.1 support for mediawiki master branches since they consumed a lot of resources.
- I started rebuilding the fleet to use instances with less ram (from 32G to 24G) T226233
We also had some small dedicated instances added which go against the quota, though they are not always busy:
- integration-trigger is a workaround due to Zuul limitations and just runs idling jobs that trigger actual jobs on other instances. It is just 1 cpu/2G RAM
- integration-agent-puppet-docker-10018 vCPUs / 24G RAM which only run jobs for operations/puppet repository
The bulk of the instances are mediumram flavor:
| vCPUs | 8 |
| RAM | 24G |
| Disk | 80G |
They each can run up to four jobs concurrently each could potentially use more than 1 CPU (eg a mediawiki run would need cpu for chrome / mysql / mediawiki).
If there is any capacity available on WMCS, it would be great to raise the quota to allow some more mediumram instances. Given they will be heavily used at some period of the day and might end up putting to much stress on the WMCS infrastructure. I am willing to receive as much quota increase as possible, but do not want WMCS infra to die as a result.
So I guess the easiest is to chat about it?