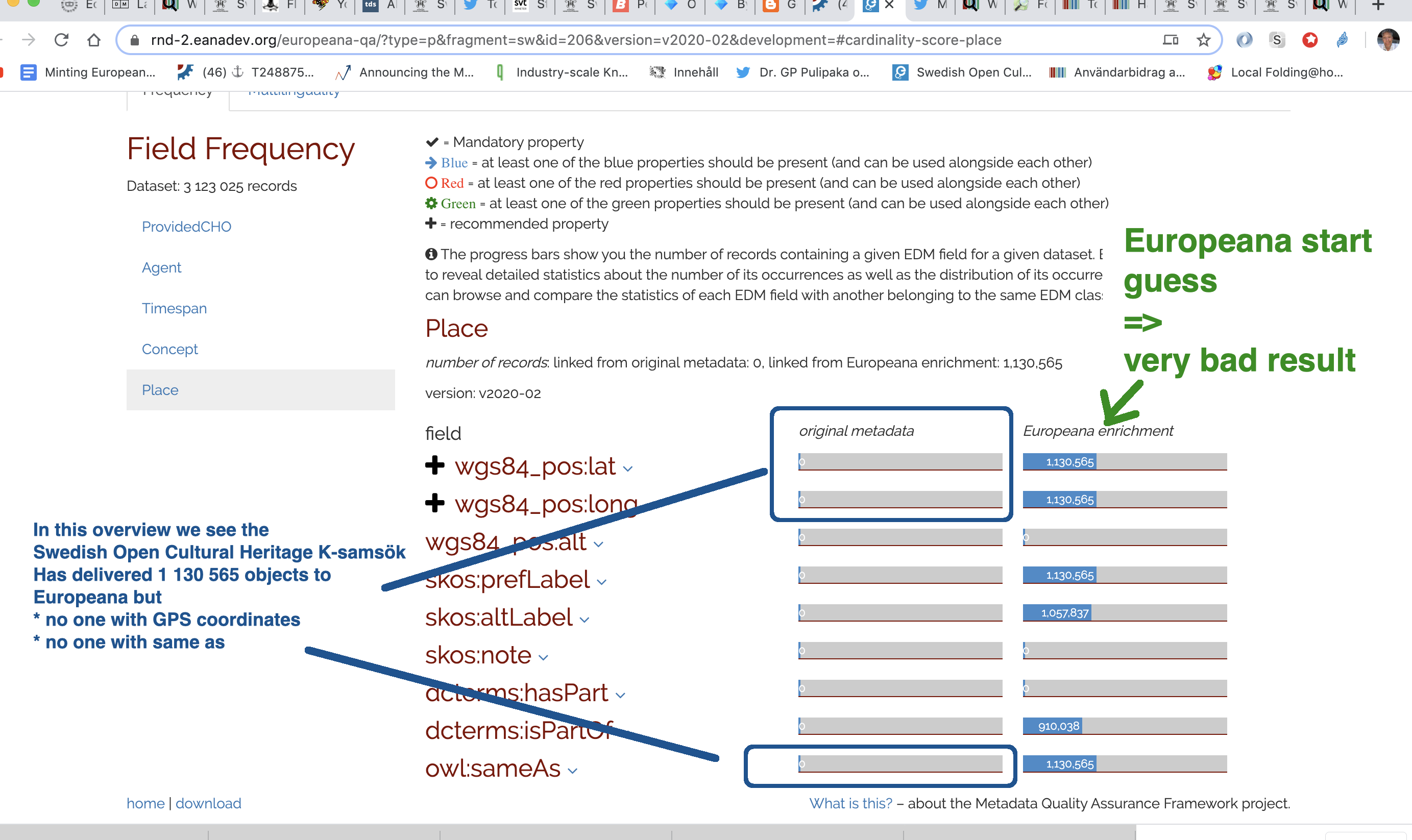
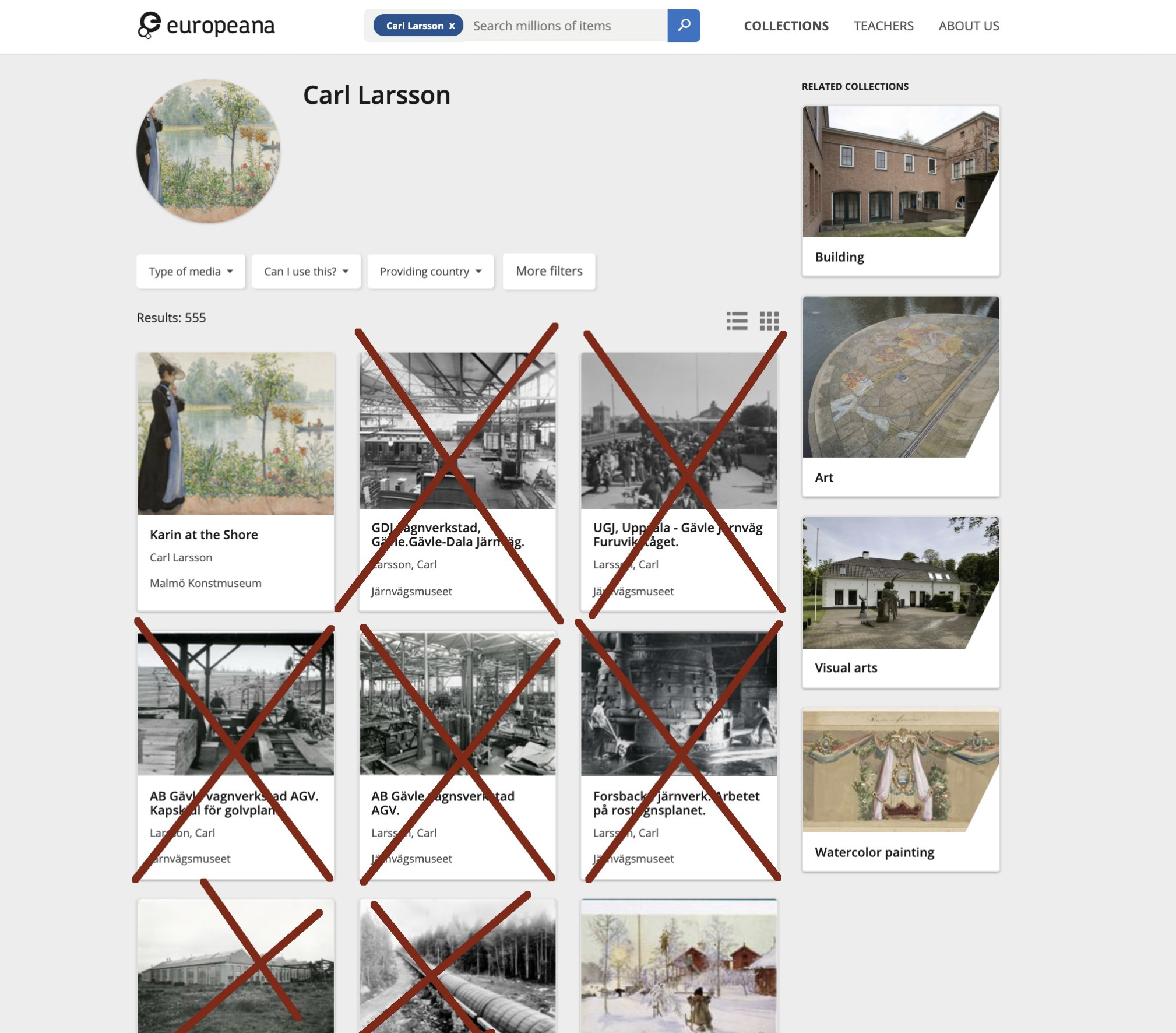
Create a structured dataset of past documented GLAM-Wiki collaborations in the Wikimedia movement.
This data will help to understand the diversity as well as the needs of GLAM-Wiki collaborations. This data is currently spread across various sources such as the GLAM Newsletter, Grant reports, Affiliate reports, Meta-Wiki etc.