Description
The Growth team has been working on a landing page for new users in our target wikis (Arabic, Czech, Korean and Vietnamese) over the past year. The landing page is Special:Homepage and it is described in detail here. This quarter, we have been working on a suggested edits module for the Special:Homepage. We are interested in a performance review specifically of the Suggested Edits module, which is the least performant of the modules that exist on Special:Homepage. Review of the Suggested Edits module might lead to broader points about the Special:Homepage module loading/rendering framework, so feedback is welcome there too.
High level summary of Suggested Edits:
- Each wiki has a configuration page (MediaWiki/NewcomerTasks.json, e.g. cs.wikipedia.org/wiki/MediaWiki:NewcomerTasks.json) which defines "task types" and the maintenance templates that are associated with these task types
- When a user visits Special:Homepage, on the client side we make an API query to ApiQueryGrowthTasks and ask for a set "tasks" (articles to edit) where those tasks have a task type that the user has selected (copyediting, adding links, etc). We use ApiQueryGrowthTasks as a generator, and also request information from the info, revisions, and pageimages modules (sample query: https://test.wikipedia.org/w/api.php?action=query&format=json&prop=info%7Crevisions%7Cpageimages&inprop=protection%7Curl&rvprop=ids&pithumbsize=260&generator=growthtasks&ggtlimit=250&ggttasktypes=references&formatversion=2&uselang=en
- The API module takes the request, loads the configuration from the MediaWiki/NewcomerTasks.json file, and queries ElasticSearch using hastemplate:{pipe-delimited-list-of-templates-for-that-tasktype. It returns page IDs associated with the search.
- Back on the client-side, our front-end code gets some more data from two more sources. From RESTBase it gets the text extract to display with the "Edit card" shown to the end-user and from Pageviews API it gets information about page views for that article.
Preview environment
- https://en.wikipedia.beta.wmflabs.org/wiki/Special:Homepage
- https://cs.wikipedia.beta.wmflabs.org/wiki/Special:Homepage
- https://test.wikipedia.org/wiki/Special:Homepage
In your user preferences, navigate to the bottom where it says "Newcomer homepage" and check the box for "Display newcomer homepage", and optionally "Default to newcomer homepage from username link in personal tools". Then either navigate to Special:Homepage or click your username (if you enabled "Default to newcomer homepage from username link in personal tools").
Which code to review
For front-end code:
- modules/homepage/*.js
- modules/homepage/suggestededits/*.js
For back-end code:
- includes/HomepageModules/SuggestedEdits.php
- includes/Specials/SpecialHomepage.php
- includes/NewcomerTasks/*.php
- includes/Api/ApiQueryGrowthTasks.php
Performance assessment
Please initiate the performance assessment by answering the below:
- What work has been done to ensure the best possible performance of the feature?
We recently merged code to execute search and load the configuration within process rather than making an external HTTP request (T235717). This is not yet in production but it will be with wmf.10
- What are likely to be the weak areas (e.g. bottlenecks) of the code in terms of performance?
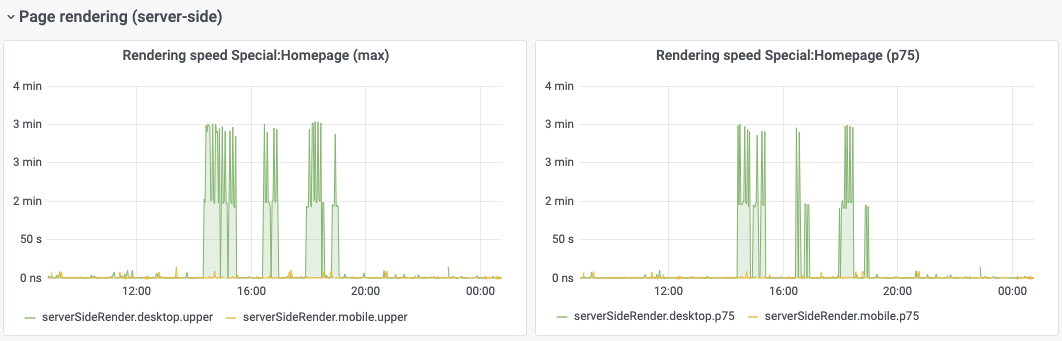
There is no server-side rendering of the first card that a user sees (T236738). So there is a second or two where the user sees an empty box in suggested edits while 3 API queries are executed (T238171). The slowest one is for ApiQueryGrowthTasks; suggestions on optimizing that would be appreciated. For now we plan to do {T238231: Newcomer tasks: show skeleton screen while loading} but it would be nicer to just have the module load faster.
- Are there potential optimisations that haven't been performed yet?
Server-side rendering of the initial card.
Would it make sense to have a single API query that's slower but already contains pageview and RESTBase text extract data? Or maybe that data should be put into the ElasticSearch index so that on the client-side we only need a single query to ApiQueryGrowthTasks to be able to construct the cards?
- Please list which performance measurements are in place for the feature and/or what you've measured ad-hoc so far. If you are unsure what to measure, ask the Performance Team for advice: performance-team@wikimedia.org.
I looked at a profile on test.wikipedia.org and nothing jumped out. Once the in-process config is live T235717 things will probably look better.