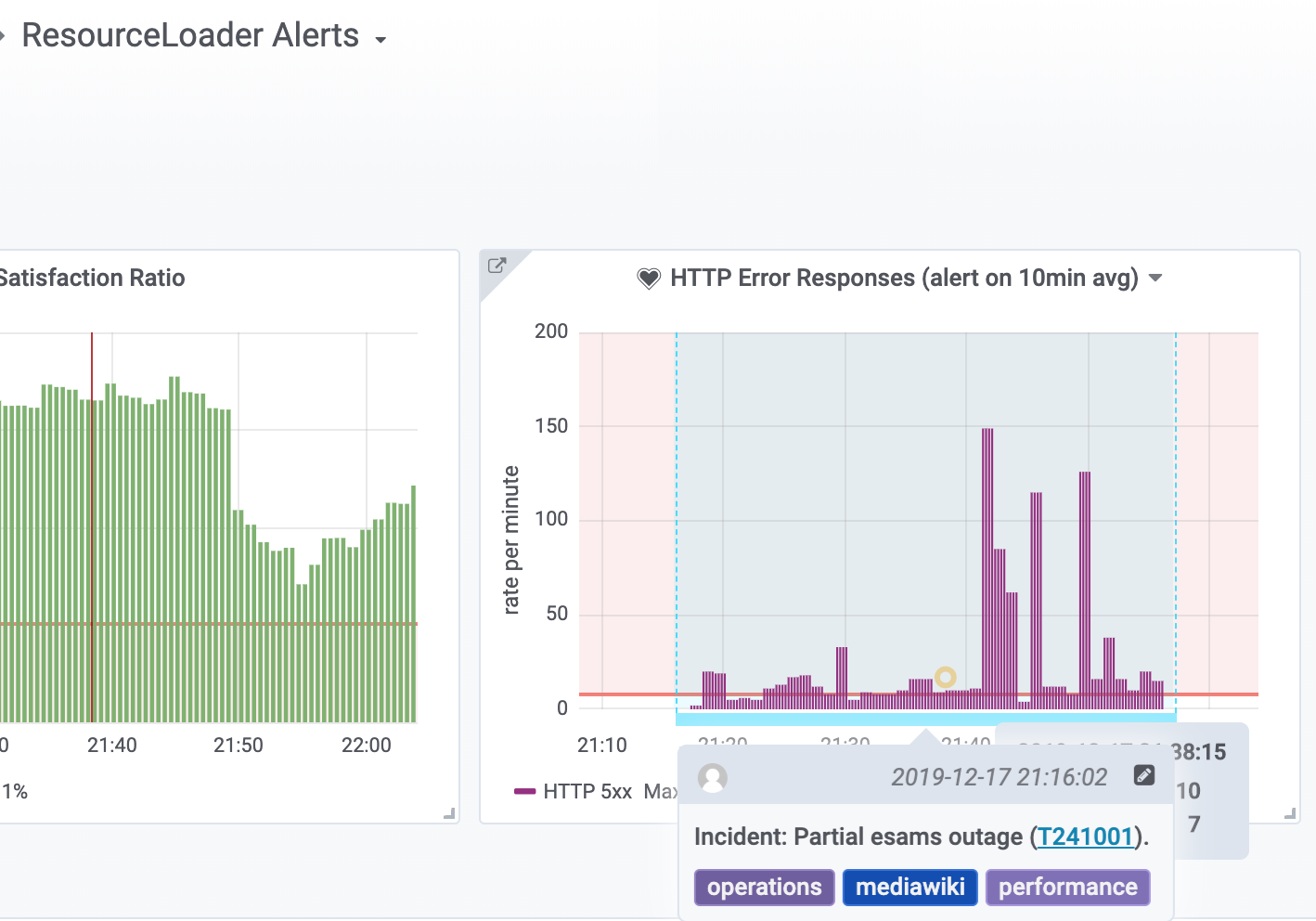
We were serving about 60rps of 503 from esams: https://grafana.wikimedia.org/d/000000479/frontend-traffic?orgId=1&from=1576615825607&to=1576621811000&var-site=esams&var-cache_type=text&var-cache_type=upload&var-status_type=5
logstash https://logstash.wikimedia.org/goto/b6a2987ff6b4be14f1f8fa2305aef56c
Tracked this down to just cp3050 having some sort of backend-ATS stomachache (pop open the "CPU per host" section): https://grafana.wikimedia.org/d/000000607/cluster-overview?orgId=1&var-datasource=esams%20prometheus%2Fops&var-cluster=cache_text&var-instance=All&from=1576615825607&to=1576621811000
There were also a bunch of extra inuse sockets (about 2x): https://grafana.wikimedia.org/d/000000377/host-overview?orgId=1&refresh=5m&var-server=cp3050&var-datasource=esams%20prometheus%2Fops&var-cluster=cache_text&from=1576615825607&to=1576621811000
I gathered some atslog-backend output in an NDA'd paste: P9920
and then I depooled the host.