During the investigation of T238494 we've discovered that connection reuse against origin servers could and should be improved. This would benefit specially esams and eqsin, due to the higher latency between them and eqiad/codfw
Description
Description
Details
Details
Customize query in gerrit
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Resolved | • ema | T238494 15% response start regression as of 2019-11-11 (Varnish->ATS) | |||
| Open | None | T241145 Improve ATS backend connection reuse against origin servers |
Event Timeline
Comment Actions
Change 559478 had a related patch set uploaded (by Vgutierrez; owner: Vgutierrez):
[operations/puppet@production] ATS: Enable SO_KEEPALIVE and TCP_FASTOPEN for outgoing connections on ats-be
Comment Actions
Change 570612 had a related patch set uploaded (by Ema; owner: Ema):
[operations/puppet@production] tlsproxy::localssl: allow setting keepalive_requests
Comment Actions
Change 570613 had a related patch set uploaded (by Ema; owner: Ema):
[operations/puppet@production] profile::mediawiki::webserver: increase nginx keepalive_requests
Comment Actions
Change 570612 merged by Ema:
[operations/puppet@production] tlsproxy::localssl: allow setting keepalive_requests
Comment Actions
Change 570613 merged by Ema:
[operations/puppet@production] profile::mediawiki::webserver: increase canary keepalive_requests
Comment Actions
Change 570640 had a related patch set uploaded (by Ema; owner: Ema):
[operations/puppet@production] profile::mediawiki::webserver: increase keepalive_requests
Comment Actions
Change 570655 had a related patch set uploaded (by Ema; owner: Ema):
[operations/puppet@production] profile::mediawiki::webserver: revert api canary keepalive_requests
Comment Actions
Change 570655 merged by Ema:
[operations/puppet@production] profile::mediawiki::webserver: revert api canary keepalive_requests
Comment Actions
Mentioned in SAL (#wikimedia-operations) [2020-02-06T14:14:33Z] <ema> run puppet on mw-api-canary to revert nginx keepalive_requests bump T241145
Comment Actions
Change 570670 had a related patch set uploaded (by Ema; owner: Ema):
[operations/puppet@production] profile::mediawiki::webserver: set api keepalive_requests to 200
Comment Actions
Change 570670 merged by Ema:
[operations/puppet@production] profile::mediawiki::webserver: set api keepalive_requests to 200
Comment Actions
Mentioned in SAL (#wikimedia-operations) [2020-02-06T15:14:52Z] <ema> A:mw-api: force puppet run to increase keepalive_requests from 100 to 200 https://gerrit.wikimedia.org/r/#/c/operations/puppet/+/570670/ T241145
Comment Actions
Change 570677 had a related patch set uploaded (by Ema; owner: Ema):
[operations/puppet@production] profile::mediawiki::webserver: set keepalive_requests to 200
Comment Actions
Change 570640 abandoned by Ema:
profile::mediawiki::webserver: increase keepalive_requests
Reason:
We're approaching the problem more gradually instead, going to 200 first
Comment Actions
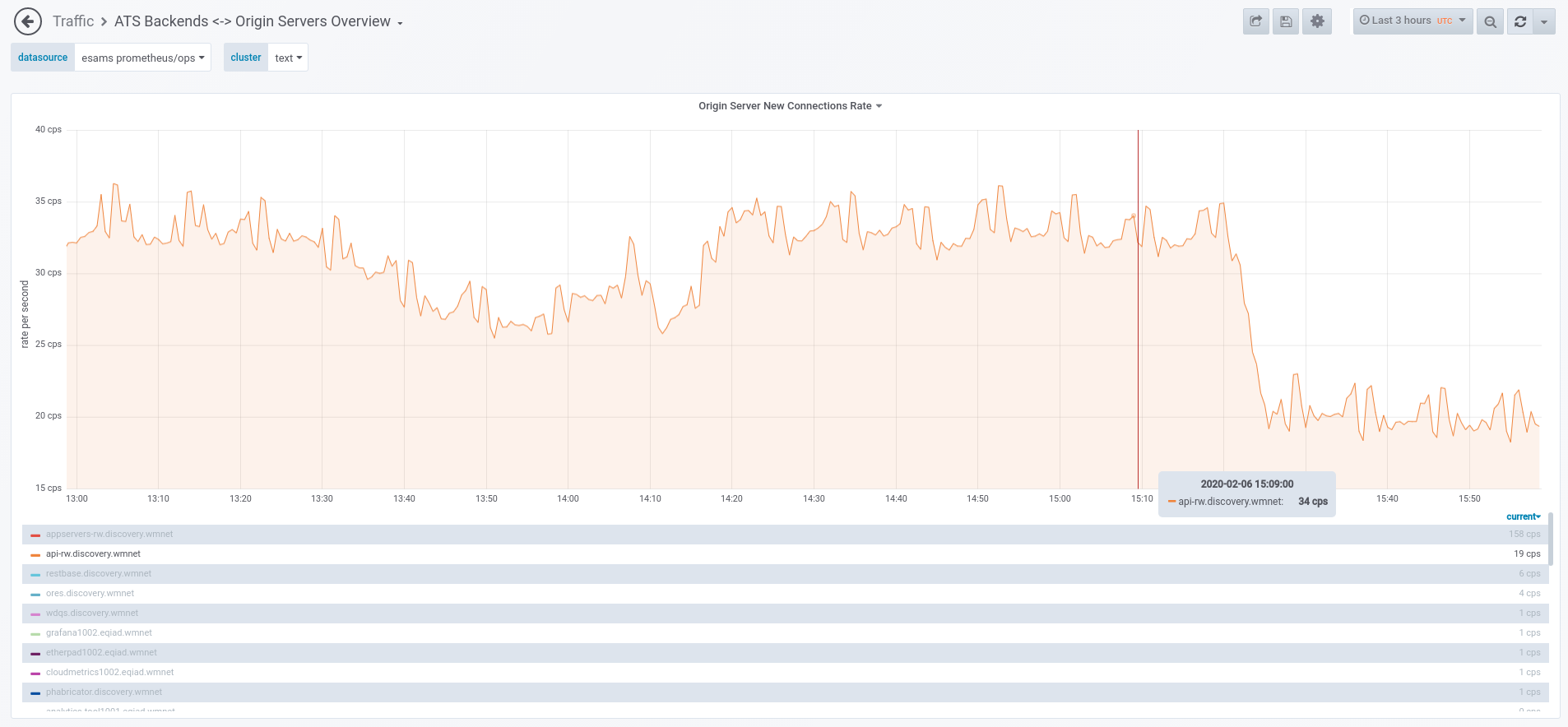
This change had a positive impact on ats-be<->api-rw.discovery.wmnet new connection rate:
Comment Actions

We will keep an eye on the trend in coming days to check how much of a dent it made in the perf regression.
Comment Actions
Change 570677 merged by Ema:
[operations/puppet@production] profile::mediawiki::webserver: set keepalive_requests to 200
Comment Actions
Mentioned in SAL (#wikimedia-operations) [2020-02-07T09:53:46Z] <ema> A:mw: increase keepalive_requests from 100 to 200 https://gerrit.wikimedia.org/r/#/c/operations/puppet/+/570670/ T241145
Comment Actions
This had likely a positive impact for the performance of API requests, not so much when it comes to general MediaWiki traffic. I've started plotting the percentage of requests served over a reused connection. Different lines represent different origin servers:
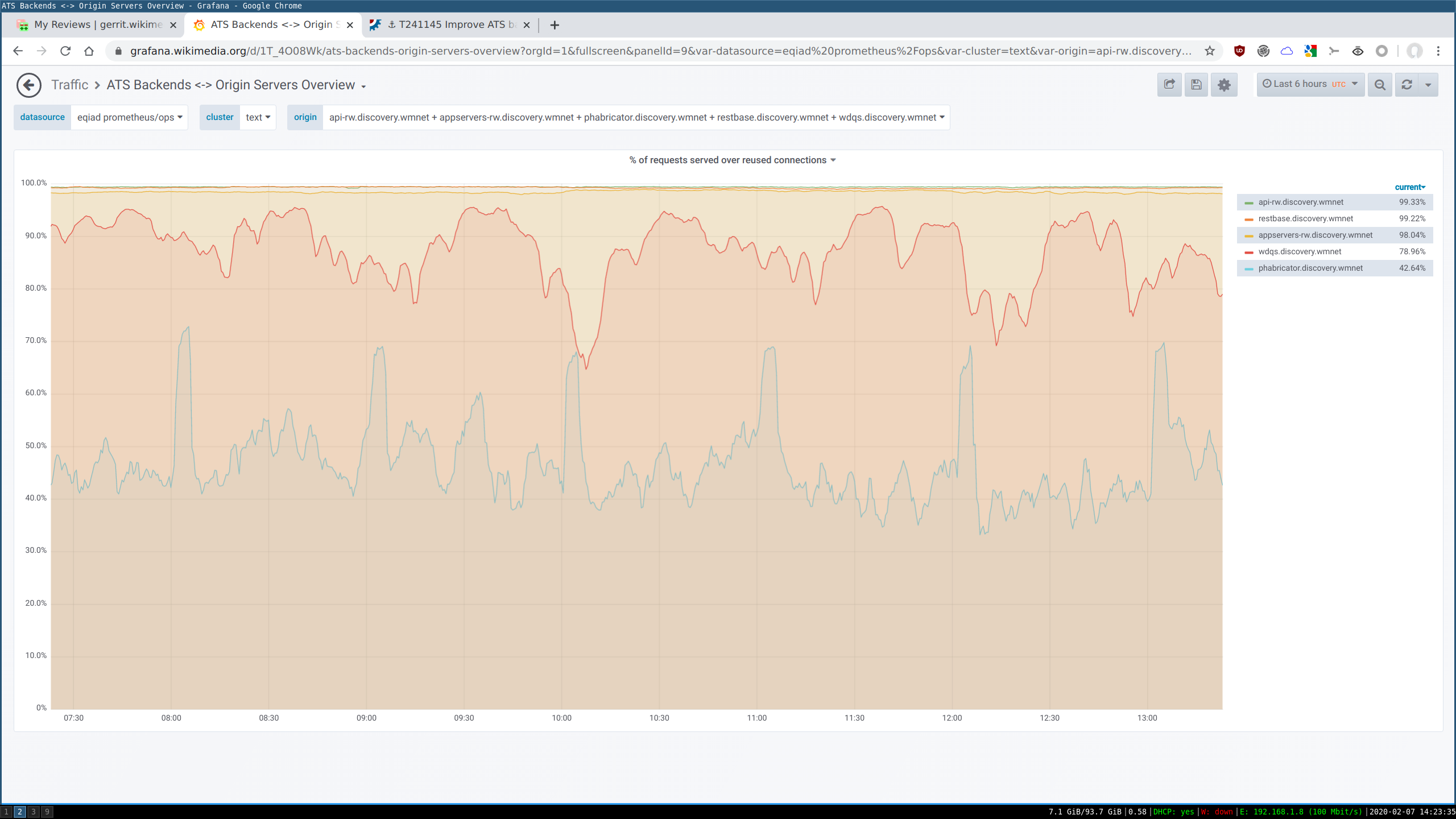
ATS in eqiad has excellent connection reuse for api-rw and restbase, with more than 99% of requests being served without establishing a new TCP connection. The situation is also good for regular MediaWiki appservers, at ~98% reuse.
By looking at esams instead, it's clear that things aren't optimal there. Only between 92 and 95% of MediaWiki requests are served over reused connections (ie: between 5 and 7% require TCP connection establishment + TLS dance over the ocean). Similar values can be observed in eqsin.
For each request that goes through ats-be, we log the number of times the given TCP connection to the origin has been reused. I have gathered some data with the following command on ATS backends in eqiad and esams:
sudo timeout 30 atslog-backend OriginServer:appserv | egrep -o ConnReuse:[0-9]+ | sed 's/ConnReuse://' | sort -n | awk '
{ v[NR]=$1 ; sum+=$1 }
END { print "p50", v[int(NR*.5)] ; print "p75", v[int(NR*.75)] ; print "p99", v[int(NR*.99)] }'The current keepalive_requests value on the TLS-terminating nginx on the origin servers is 200, so the highest possible value for connection reuse on ATS is 199.
Connection reuse values for api-rw.discovery.wmnet:
| host | median | p75 | p99 |
| cp1075 | 73 | 114 | 196 |
| cp3052 | 93 | 145 | 197 |
Values for appservers-rw.discovery.wmnet:
| host | median | p75 | p99 |
| cp1075 | 24 | 57 | 183 |
| cp3052 | 13 | 26 | 84 |
Specifically, in the case of esams requests to appservers-rw, we don't get even close to the limit of 200 connections imposed by nginx. The absolute maximum I've seen is around 110. As shown by p99, however, values above 100 are more the exception than the norm. The next step is finding out why this is the case.
Comment Actions
It turns out that cache_text nodes send quite a lot of RSTs to appservers-rw. See for example cp3054:
11:13:59 ema@cp3054.esams.wmnet:~
$ sudo timeout 10 tcpdump -n "src host `hostname --fqdn` && (tcp[tcpflags] & (tcp-rst) != 0)" | awk '{print $5}' | grep .443 | sort | uniq -c
[...]
0 packets dropped by kernel
414 10.2.2.1.443:
4 10.2.2.17.7443:
12 10.64.16.8.443:
2 10.64.32.178.7443:That's about 40 RSTs per second, compared to 0.4 sent to restbase (10.2.2.17)
Like esams cache nodes, eqiad nodes also send RSTs mainly to appservers-rw, though less often. Note that the difference is not proportional to traffic volume. Traffic ratio is 1.5, while RST ratio is 6.
11:18:12 ema@cp1075.eqiad.wmnet:~
$ sudo timeout 10 tcpdump -n "src host `hostname --fqdn` && (tcp[tcpflags] & (tcp-rst) != 0)" | awk '{print $5}' | grep .443 | sort | uniq -c
[...]
0 packets dropped by kernel
69 10.2.2.1.443:
2 10.2.2.22.443:
2 10.64.0.50.443:
4 10.64.16.8.443:One of the reasons to send RSTs (other than having received a TCP packet on a closed port) is when tcp_close is called on a socket with unread data. From Linux's net/ipv4/tcp.c:
2325 void tcp_close(struct sock *sk, long timeout)
[...]
2362 /* As outlined in RFC 2525, section 2.17, we send a RST here because
2363 * data was lost. To witness the awful effects of the old behavior of
2364 * always doing a FIN, run an older 2.1.x kernel or 2.0.x, start a bulk
2365 * GET in an FTP client, suspend the process, wait for the client to
2366 * advertise a zero window, then kill -9 the FTP client, wheee...
2367 * Note: timeout is always zero in such a case.
2368 */
2369 if (unlikely(tcp_sk(sk)->repair)) {
2370 sk->sk_prot->disconnect(sk, 0);
2371 } else if (data_was_unread) {
2372 /* Unread data was tossed, zap the connection. */
2373 NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONCLOSE);
2374 tcp_set_state(sk, TCP_CLOSE);
2375 tcp_send_active_reset(sk, sk->sk_allocation);
2376 } else if (sock_flag(sk, SOCK_LINGER) && !sk->sk_lingertime) {
2377 /* Check zero linger _after_ checking for unread data. */
2378 sk->sk_prot->disconnect(sk, 0);
2379 NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONDATA);
2380 } else if (tcp_close_state(sk)) {
2381 /* We FIN if the application ate all the data before
2382 * zapping the connection.
2383 */
2384
[...]
2410 tcp_send_fin(sk);
2411 }The data_was_unread integer represents the number of unread bytes on the given socket when it was closed, and if it's greater than 0 Linux sends a RST instead of a FIN to close the connection. With SystemTap we can see that this happens often, and essentially only with appservers-rw.
global c
probe timer.ms(10000) {
foreach (ip in c) {
printf("%s: %d\n", ip, c[ip])
}
exit()
}
probe kernel.statement("tcp_close@./net/ipv4/tcp.c:2356") {
daddr = format_ipaddr(__ip_sock_daddr($sk), __ip_sock_family($sk))
dport = __tcp_sock_dport($sk)
if ($data_was_unread && substr(daddr, 0, 3) == "10." && dport == 443) {
c[daddr]++
}
}Output on cp3054:
10.2.2.1: 131 10.2.2.22: 1
ATS should likely not call close(2) before having read all the data on the socket.
The number of times the ATS function do_io_close@./iocore/net/SSLNetVConnection.cc is called is near (but slightly less than) the number of times the kernel calls tcp_close:
global tcp_close, do_io_close
probe timer.ms(10000) {
printf("tcp_close=%d do_io_close=%d\n", tcp_close, do_io_close)
exit()
}
probe process("/usr/bin/traffic_server").function("do_io_close@./iocore/net/SSLNetVConnection.cc") {
remote_addr = &(@cast($this, "NetVConnection")->remote_addr)
ip_addr = ip_ntop(@cast(&remote_addr->sa, "sockaddr_in")->sin_addr->s_addr)
port = ntohs(@cast(&remote_addr->sa, "sockaddr_in")->sin_port)
if (port == 443 && ip_addr == "10.2.2.1") {
do_io_close++
}
}
probe kernel.statement("tcp_close@./net/ipv4/tcp.c:2356") {
daddr = format_ipaddr(__ip_sock_daddr($sk), __ip_sock_family($sk))
dport = __tcp_sock_dport($sk)
if (dport == 443 && daddr == "10.2.2.1") {
tcp_close++
}
}13:26:21 ema@cp3054.esams.wmnet:~ $ sudo stap -v tcp_do_io_close.stp [...] Pass 5: starting run. tcp_close=201 do_io_close=191 Pass 5: run completed in 0usr/50sys/10841real ms.
The function is called much more often for appservers-rw than for other origins:
global do_io_close
probe timer.ms(10000) {
foreach (ip in do_io_close) {
printf("%s: %d\n", ip, do_io_close[ip])
}
exit()
}
probe process("/usr/bin/traffic_server").function("do_io_close@./iocore/net/SSLNetVConnection.cc") {
remote_addr = &(@cast($this, "NetVConnection")->remote_addr)
ip_addr = ip_ntop(@cast(&remote_addr->sa, "sockaddr_in")->sin_addr->s_addr)
port = ntohs(@cast(&remote_addr->sa, "sockaddr_in")->sin_port)
if (port == 443 && substr(ip_addr, 0, 3) == "10.") {
do_io_close[ip_addr]++
}
}10.2.2.1: 155 10.2.2.22: 19 10.2.2.32: 2 10.64.36.110: 1 10.64.0.111: 1
It seems worth investigating why do_io_close@./iocore/net/SSLNetVConnection.cc is called so often for appservers-rw. The backtrace obtained with SystemTap's print_ubacktrace() looks like this:
0x5636641785e0 : _ZN17SSLNetVConnection11do_io_closeEi+0x0/0x330 [/usr/bin/traffic_server] 0x563663f8ebbb : _ZN17HttpServerSession11do_io_closeEi+0xcb/0x2960 [/usr/bin/traffic_server] 0x563663f6d078 : _ZN6HttpSM22release_server_sessionEb+0x48/0x1c0 [/usr/bin/traffic_server] 0x563663f8863b : _ZN6HttpSM14set_next_stateEv+0xd0b/0x1200 [/usr/bin/traffic_server] [...]
The function release_server_session calls do_io_close if the following condition is false:
if (TS_SERVER_SESSION_SHARING_MATCH_NONE != t_state.txn_conf->server_session_sharing_match && t_state.current.server != nullptr &&
t_state.current.server->keep_alive == HTTP_KEEPALIVE && t_state.hdr_info.server_response.valid() &&
t_state.hdr_info.server_request.valid() &&
(t_state.hdr_info.server_response.status_get() == HTTP_STATUS_NOT_MODIFIED ||
(t_state.hdr_info.server_request.method_get_wksidx() == HTTP_WKSIDX_HEAD &&
t_state.www_auth_content != HttpTransact::CACHE_AUTH_NONE)) &&
plugin_tunnel_type == HTTP_NO_PLUGIN_TUNNEL) {Now it's about investigating why the condition above is so often false for appservers-rw, and true for other origins.
Comment Actions
I haven't had the time to work on this lately, but an important finding is that for appservers-rw what is making the above condition false is t_state.hdr_info.server_response.status_get() == HTTP_STATUS_NOT_MODIFIED . With stap I've verified that the above code is being called with status 200, not 304.
Comment Actions
The swap of Traffic for Traffic-Icebox in this ticket's set of tags was based on a bulk action for all such tickets that haven't been updated in 6 months or more. This does not imply any human judgement about the validity or importance of the task, and is simply the first step in a larger task cleanup effort. Further manual triage and/or requests for updates will happen this month for all such tickets. For more detail, have a look at the extended explanation on the main page of Traffic-Icebox . Thank you!