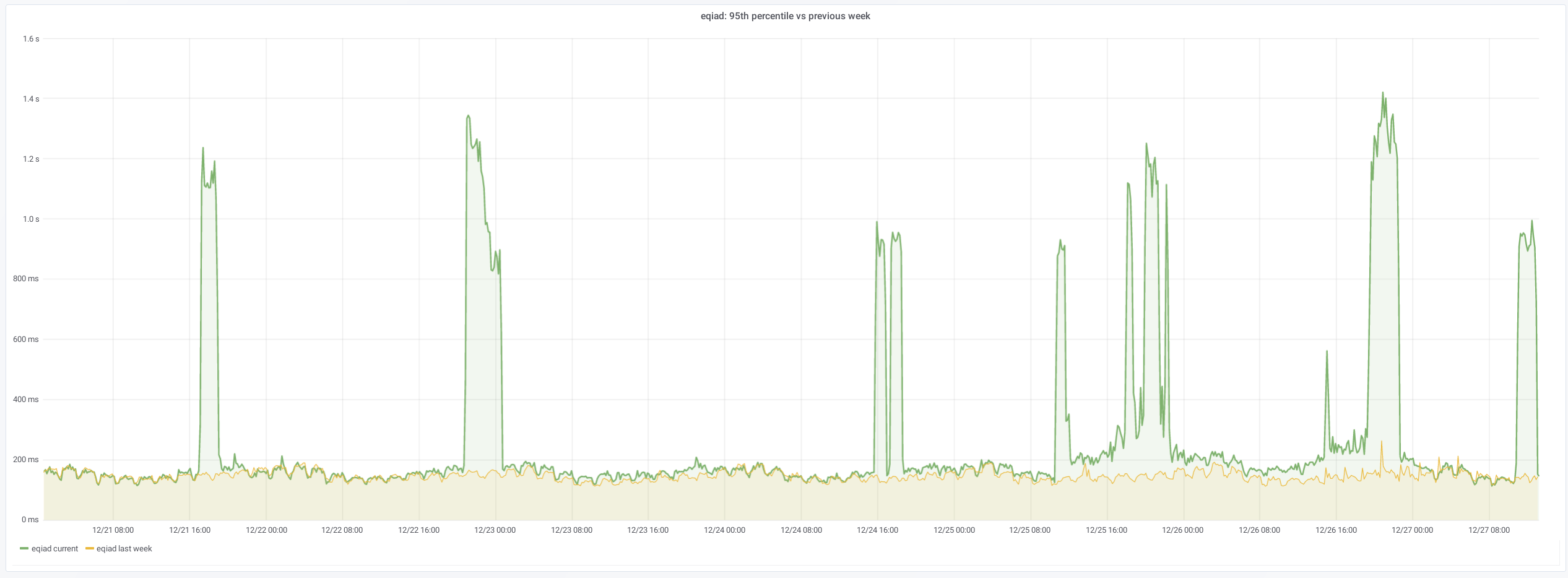
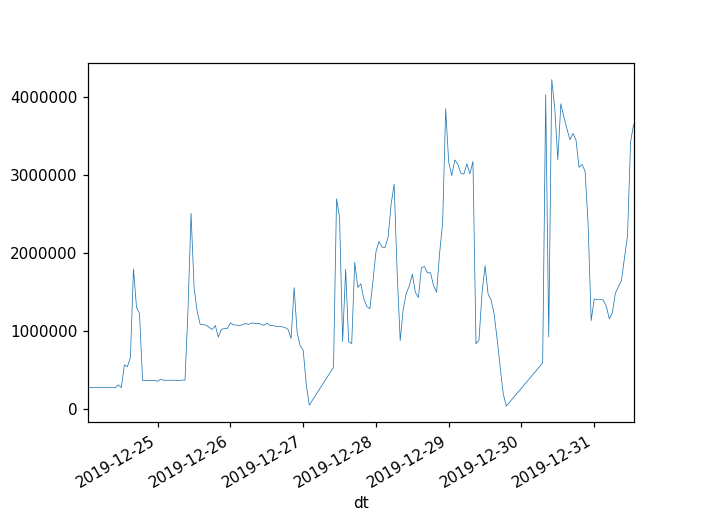
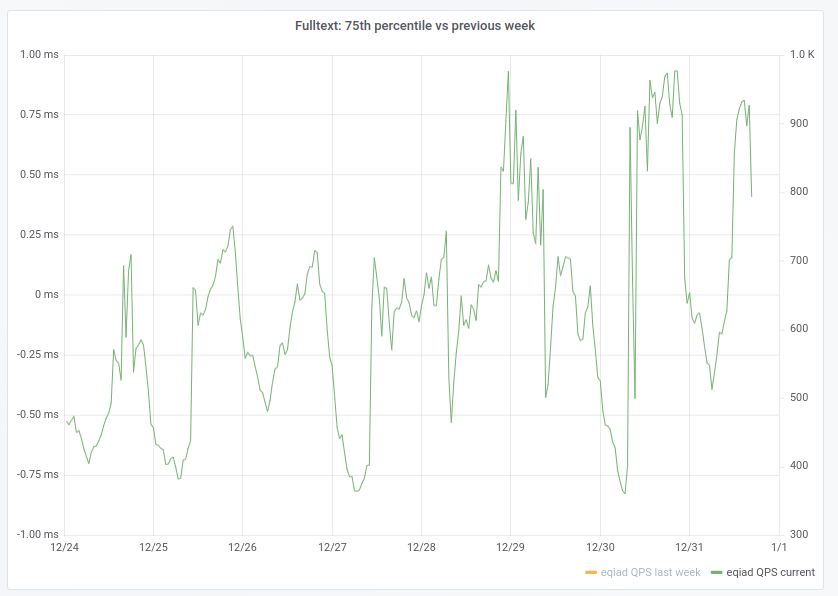
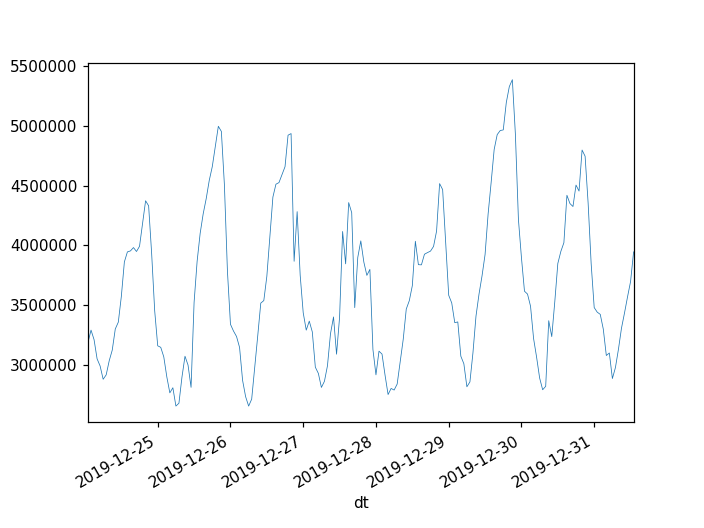
There has been at least 3 occasions in the last week, each on different day, in which the 95% percentile raised over 1 second -the 50% percentile increases too, from ~10ms to ~30ms, but that is less worrying. Last one started at 15:47 (Dec 24).
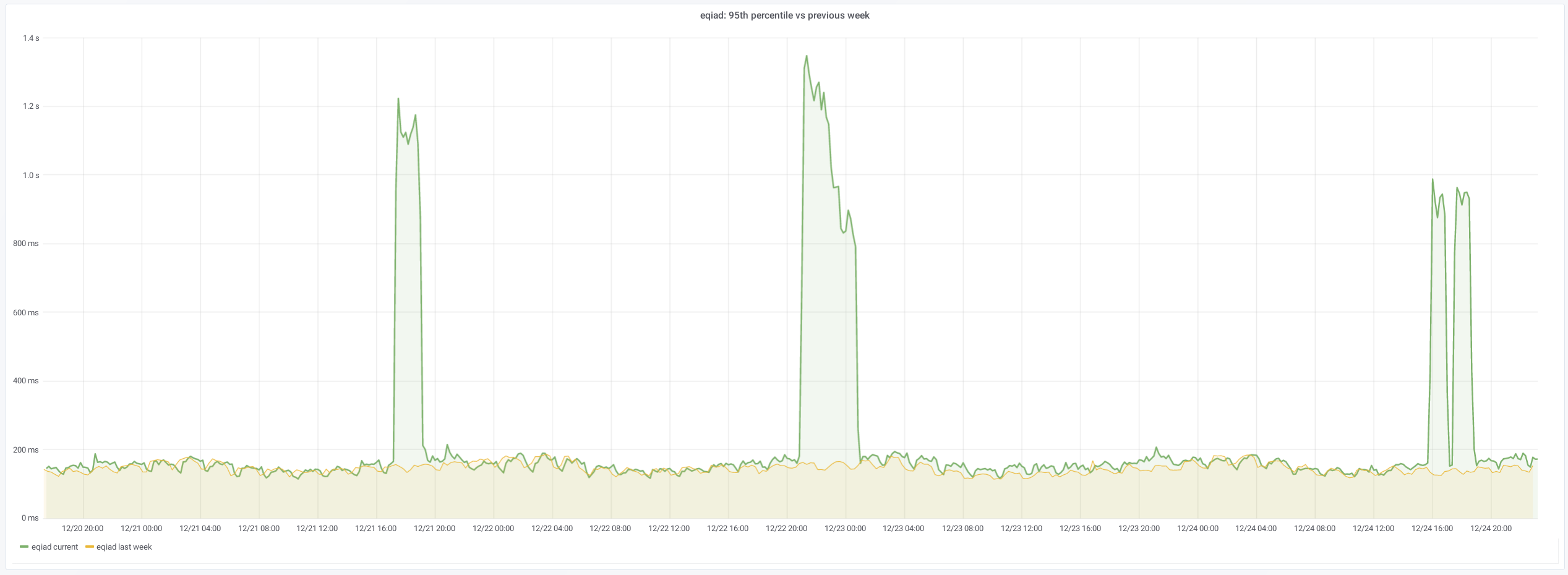
This could be due to traffic (sorry I could not find traffic statistics to confirm that), in which case, there are not many actionables here, but reporting for awareness, to evaluate impact/importance, and in case there is something internally (e.g. indexing, configuration), that could cause it or mitigate the slowdown.