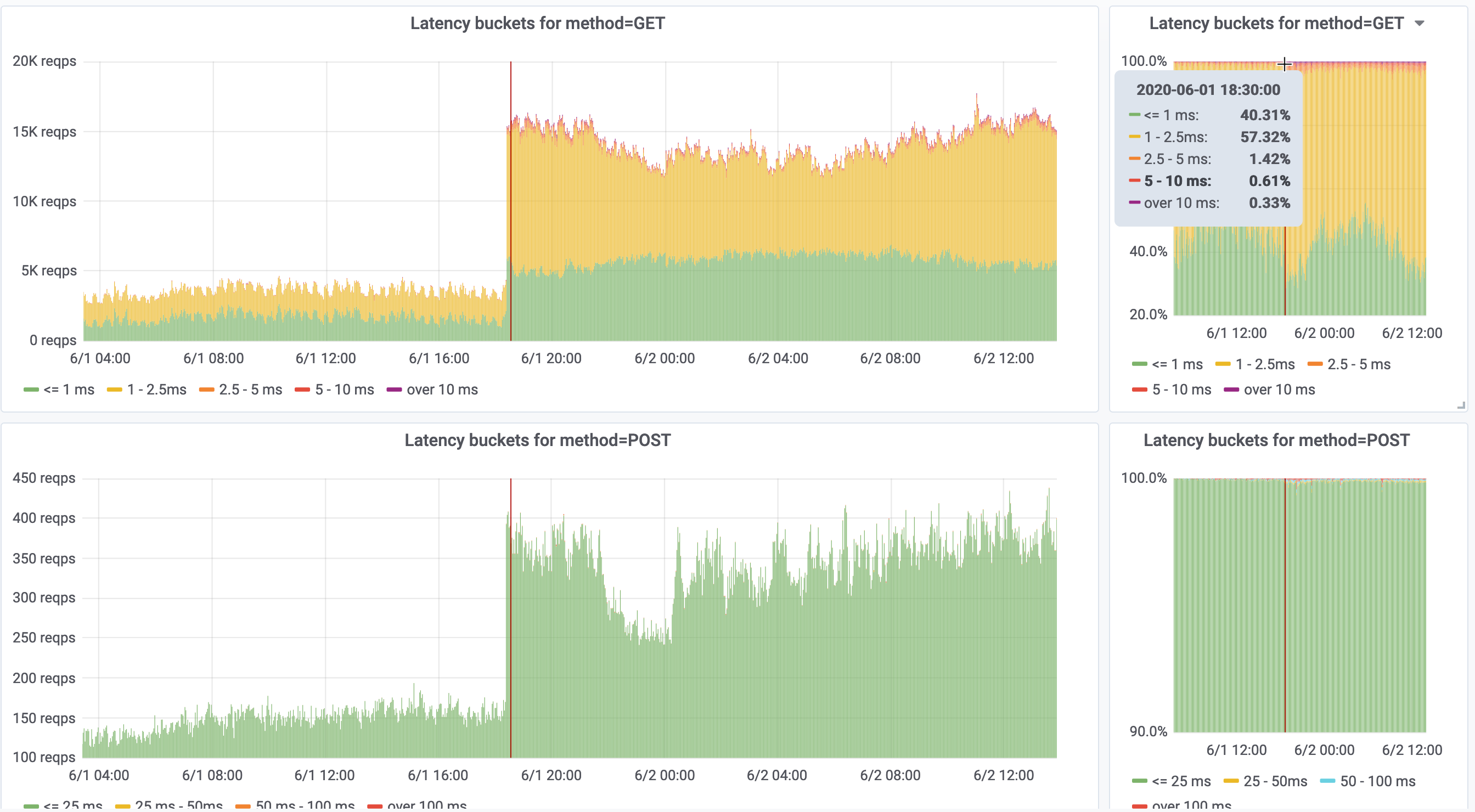
The remaining steps for session storage rollout are:
- Update testwiki from kask-transition (multi-write w/ redis) to kask-session (Kask-only)
- Update the remainder of testwikis to kask-transition (multi-write w/ redis)
- Update the remainder of testwikis to kask-session (Kask-only)
- Update group0 & group1 to kask-transition (r569678)
- Update group0 & group1 to kask-session (r570393)
- Update group1 to kask-transition (skipping...)
- Update group1 to kask-session (skipping...)
- Update all remaining wikis (default) to kask-transition (r570395)
- Update all remaining wikis (default) to kask-session (r570396)
Each step from kask-transition to kask-session should be spaced apart by either a) $wgObjectCacheSessionExpiry (1 hour), or b) the amount of time necessary to be confident everything is working as expected (which ever is longer).