Over the past couple days, we have noticed Kubernetes nodes becoming somewhat crippled periodically because the OOM killer is randomly stopping processes and the system breaks down until it is able to recover maybe 20 minutes later (or sometimes it won't recover without a reboot).
This is quite clearly caused by spikes in RAM consumption by the celery container in the deployment (see graph from prometheus)
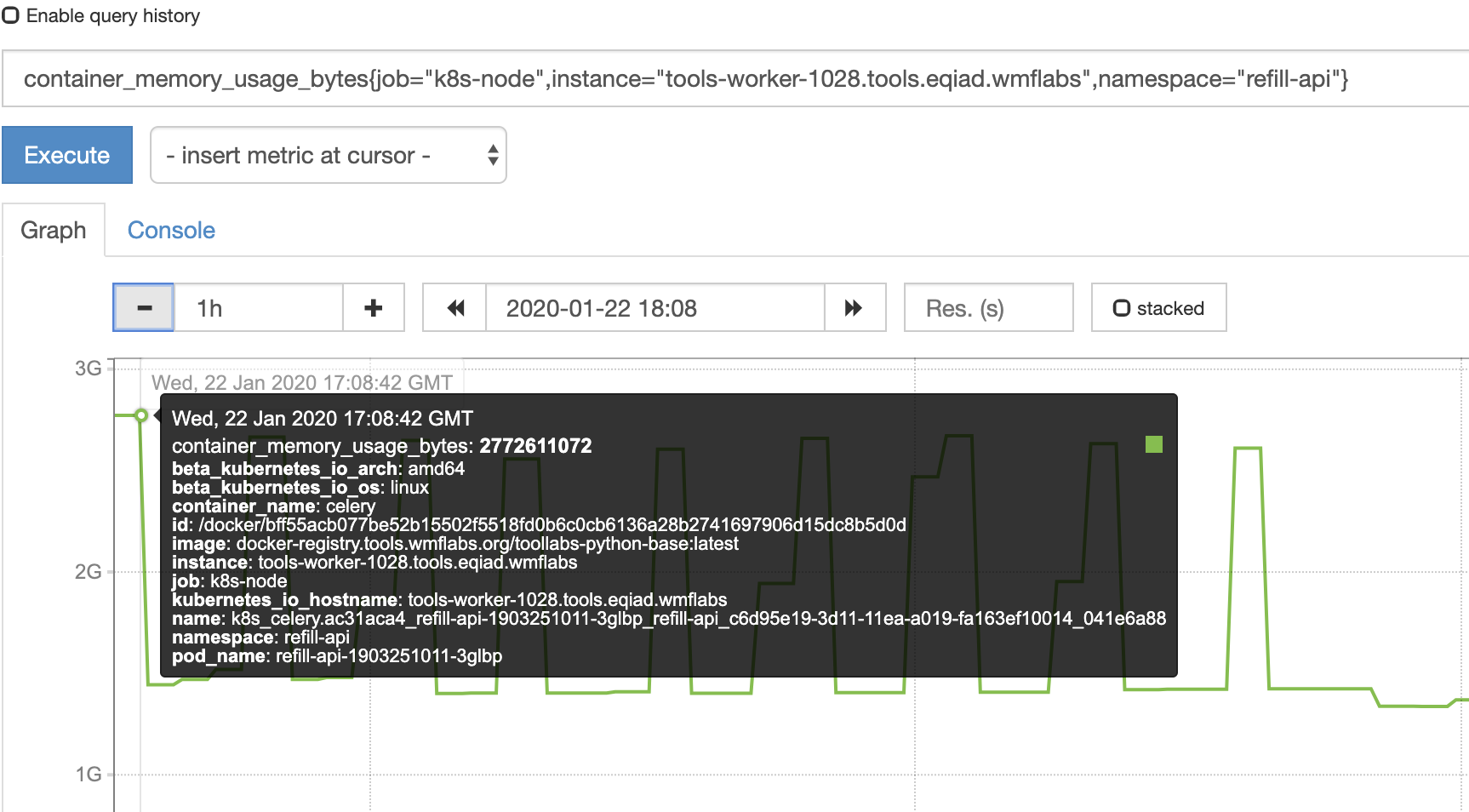
This needs a resources section for that container in the deployment manifest.
The celery container now looks like:
- name: celery image: docker-registry.tools.wmflabs.org/toollabs-python-base:latest imagePullPolicy: Always command: ["bash", "-c"] args: ["source $HOME/www/python/venv/bin/activate && cd $HOME/www/python/src && celery --autoscale=100,10 worker"] env: - name: HOME value: /data/project/refill-api volumeMounts: - mountPath: /public/dumps/ name: dumps - mountPath: /data/project/ name: home - mountPath: /etc/wmcs-project name: wmcs-project - mountPath: /data/scratch/ name: scratch terminationMessagePath: /dev/termination-log workingDir: /data/project/refill-api/
I suggest you make it:
- name: celery image: docker-registry.tools.wmflabs.org/toollabs-python-base:latest imagePullPolicy: Always resources: limits: cpu: "2" memory: 3Gi requests: cpu: "1" memory: 2Gi command: ["bash", "-c"] args: ["source $HOME/www/python/venv/bin/activate && cd $HOME/www/python/src && celery --autoscale=100,10 worker"] env: - name: HOME value: /data/project/refill-api volumeMounts: - mountPath: /public/dumps/ name: dumps - mountPath: /data/project/ name: home - mountPath: /etc/wmcs-project name: wmcs-project - mountPath: /data/scratch/ name: scratch terminationMessagePath: /dev/termination-log workingDir: /data/project/refill-api/
This will prevent the containers from being scheduled on nodes that are resource constrained and prevent any spikes over 3GB. At that level, it can still cause harm, but it is much less likely to than it is now.