On rolling all wikis to 1.35.0-wmf.16, an alert triggered for GET latency and @CDanis immediately noticed elevated CPU usage on application servers:
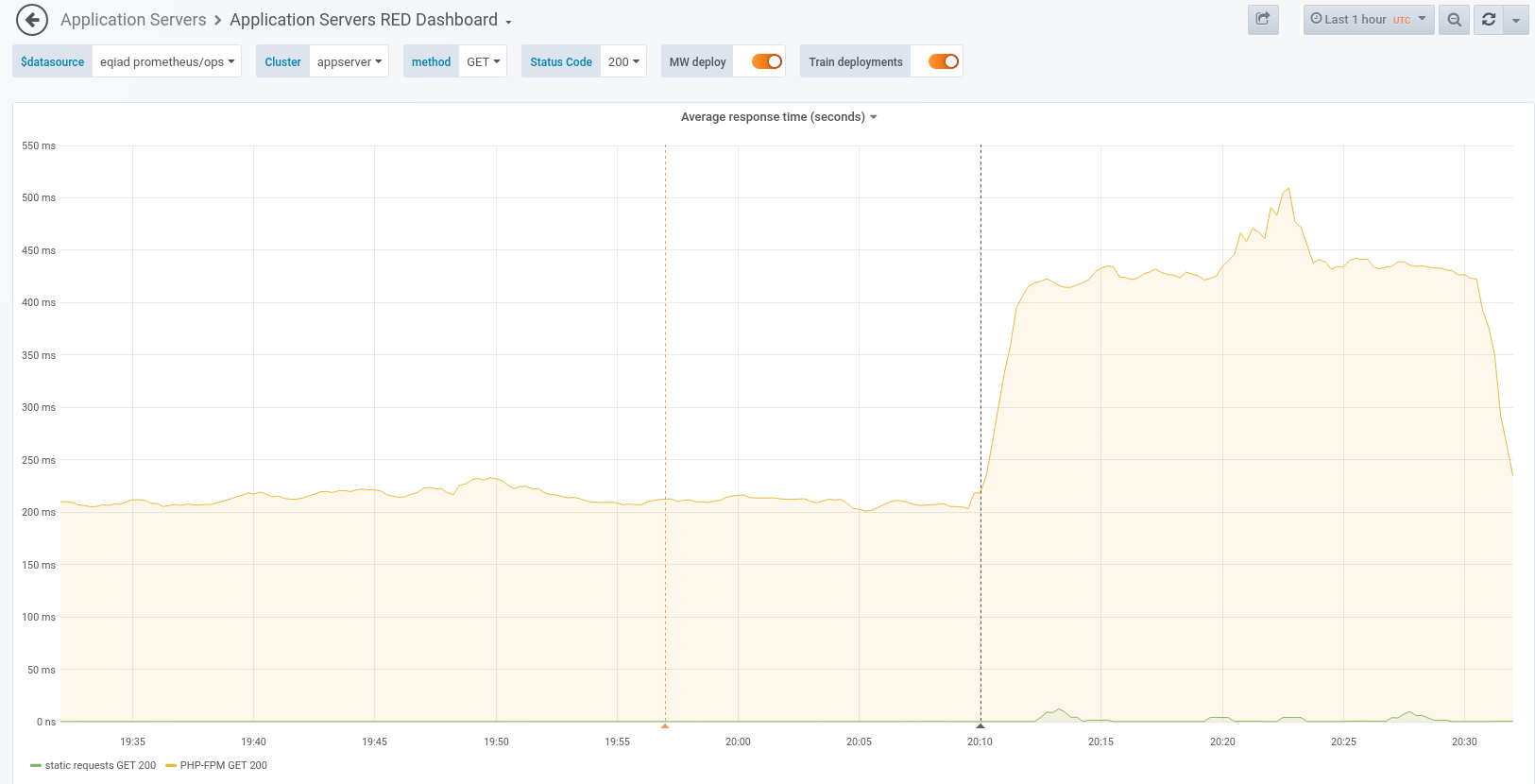
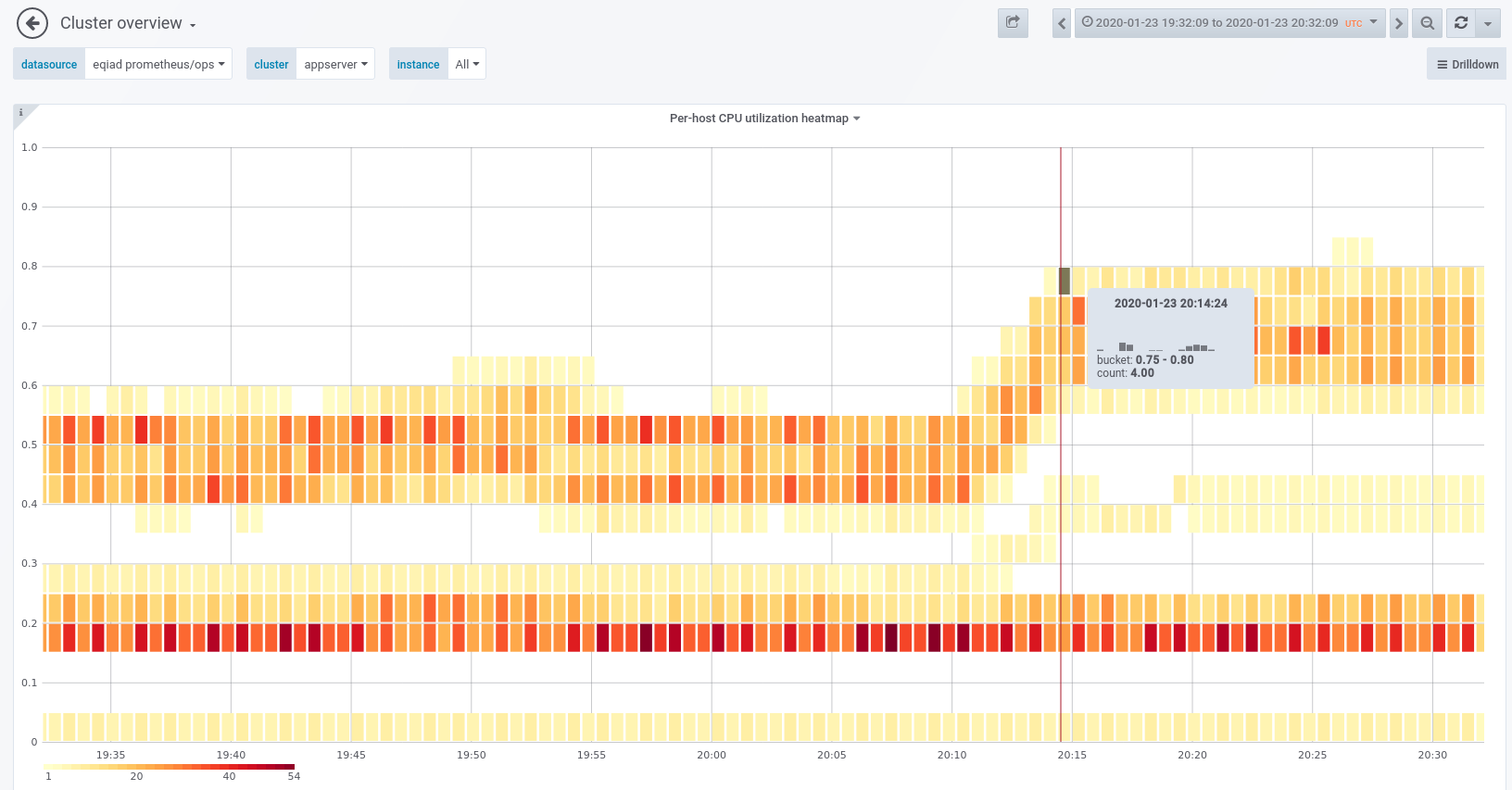
On rollback, situation immediately returned to normal. I didn't observe any serious spike in errors during the window when wmf.16 was fully deployed.
A lightly-edited log from #wikimedia-operations:
13:10 <+logmsgbot> !log brennen@deploy1001 rebuilt and synchronized wikiversions files: all wikis to 1.35.0-wmf.16 13:13 <+icinga-wm> PROBLEM - High average GET latency for mw requests on appserver in eqiad on icinga1001 is CRITICAL: cluster=appserver code=200 handler=proxy:unix:/run/php/fpm-www.sock https://wikitech.wikimedia.org/wiki/Monitoring/Missing_notes_link https://grafana.wikimedia.org/d/RIA1lzDZk/application-servers-red-dashboard?panelId=9&fullscreen&orgId=1&from=now-3h&to=now&var-datasource=eqiad+prometheus/ops&var-cluster=appserver&var-method=GET 13:14 <rlazarus> yow, that's pronounced 13:14 <cdanis> CPU is up a lot 13:14 <mutante> it's during deployment 13:15 <cdanis> yeah 13:15 <cdanis> it is right after the sync-wikiversions 13:15 <brennen> roll back, you think? 13:15 <cdanis> let's see if it continues 13:15 <mutante> i meant to say that it often happens only during the deployment itself 13:15 <cdanis> it's not uncommon to have large CPU consumption right after a deploy 13:15 <mutante> and then recovers 13:15 <mutante> that :) 13:16 <cdanis> btw, plugging the CPU usage heatmap I added to the 'cluster overview' dashboard https://grafana.wikimedia.org/d/000000607/cluster-overview?orgId=1&from=now-30m&to=now&var-datasource=eqiad%20prometheus%2Fops&var-cluster=appserver&var-instance=All&fullscreen&panelId=2607 13:18 <ori> how quickly does it recover? 13:20 <mutante> usually faster than icinga rechecks the grafana graph 13:20 <mutante> but this time it hasnt yet 13:20 <brennen> spike of ~20 "MediaWiki::restInPeace: transaction round 'LinksUpdate::doUpdate' still running" errors a bit ago but otherwise error logs look roughly status quo i think, but CPU still elevated... 13:21 <+icinga-wm> PROBLEM - PHP7 rendering on mw1269 is CRITICAL: CRITICAL - Socket timeout after 10 seconds https://wikitech.wikimedia.org/wiki/Application_servers/Runbook%23PHP7_rendering 13:22 <+icinga-wm> RECOVERY - PHP7 rendering on mw1269 is OK: HTTP OK: HTTP/1.1 200 OK - 75043 bytes in 0.628 second response time https://wikitech.wikimedia.org/wiki/Application_servers/Runbook%23PHP7_rendering 13:26 <brennen> cdanis, rlazarus: doesn't seem to be tapering off. 13:27 <mutante> yea, this case looks different 13:27 * brennen rolling back. 13:30 <+logmsgbot> !log brennen@deploy1001 rebuilt and synchronized wikiversions files: Revert "group2 wikis to 1.35.0-wmf.15" 13:32 <brennen> well, that's pretty much an immediate effect. 13:32 <rlazarus> yup that's an "it hurts when I do this" graph 13:33 <cdanis> hopefully whatever is going on is just as obvious in profiling :)