Cross posting from T231185#6107666 and T231185#6122136
Tue May 5th:
We had an issue with tendril today where tendril was very slow and almost unresponsive, at first I thought it was another case of T231769: Investigate possible memory leak on db1115, but it wasn't.
First of all we realized that after restarting mysql we got some errors with TokuDB not being loaded:
daemon.log:May 5 05:00:00 db1115 mysqld[1029]: 2020-05-05 5:00:00 140204559673088 [ERROR] Event Scheduler: [root@208.80.154.151][tendril.tendril_global_status_log_5m] Unknown storage engine 'TokuDB'
That resulted on a tables failing. This was due to a mistake on https://gerrit.wikimedia.org/r/#/c/operations/puppet/+/585115/3/modules/profile/templates/mariadb/mysqld_config/tendril.my.cnf.erb which as been fixed with: https://gerrit.wikimedia.org/r/#/c/operations/puppet/+/594405/
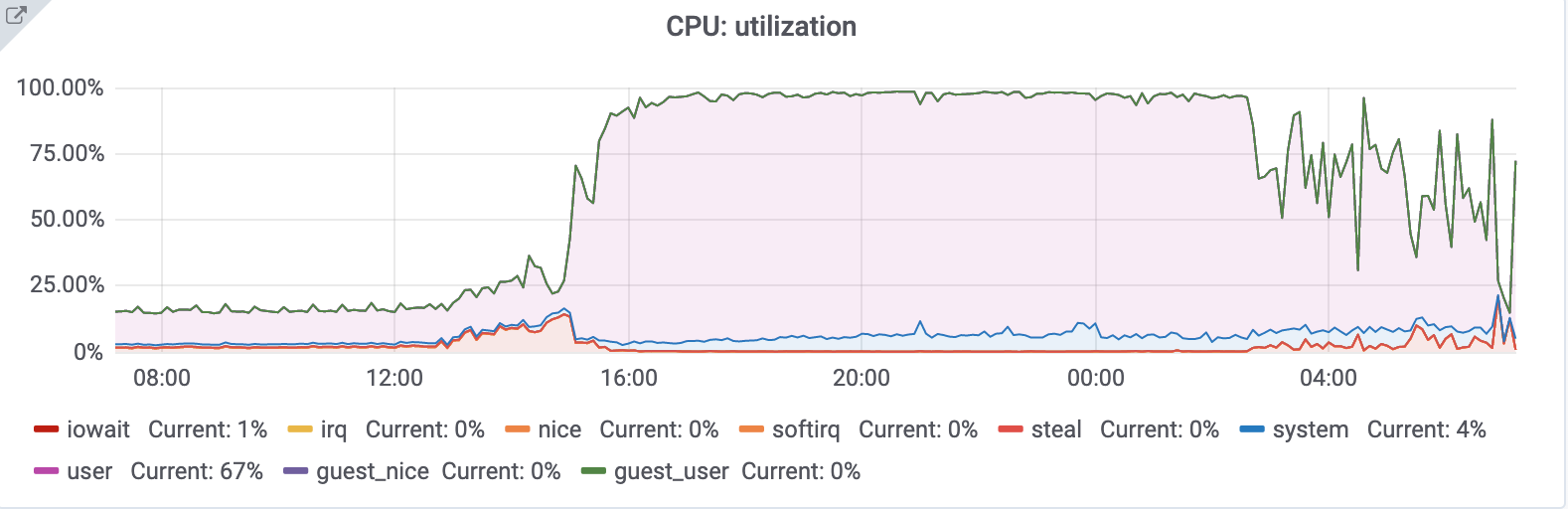
However, after manually enabling TokuDB we also saw that the host was super loaded as soon as MySQL was started, and the CPU was over the roof:
05:31:43 up 36 min, 3 users, load average: 64.56, 57.27, 36.13
The host was full of connections that were piling up, but one of them was taking ages to complete:
| 240574 | root | 10.64.32.25 | tendril | Connect | 852 | Copying to tmp table | insert into processlist_query_log
(server_id, stamp, id, user, host, db, time, info)
select p.server_id, now(), p.id, p.user, p.host, p.db, p.time, p.info
from processlist p
left join processlist_query_log q
on q.server_id = @server_id
and p.id = q.id
and p.user = q.user
and p.host = q.host
and p.db = q.db
and p.info = q.info
and p.time > q.time
and q.stamp > now() - interval 7 day
where
p.server_id = @server_id
and p.command = 'Query'
and q.server_id is nullThat was the only query that would remain running after stopping the event scheduler.
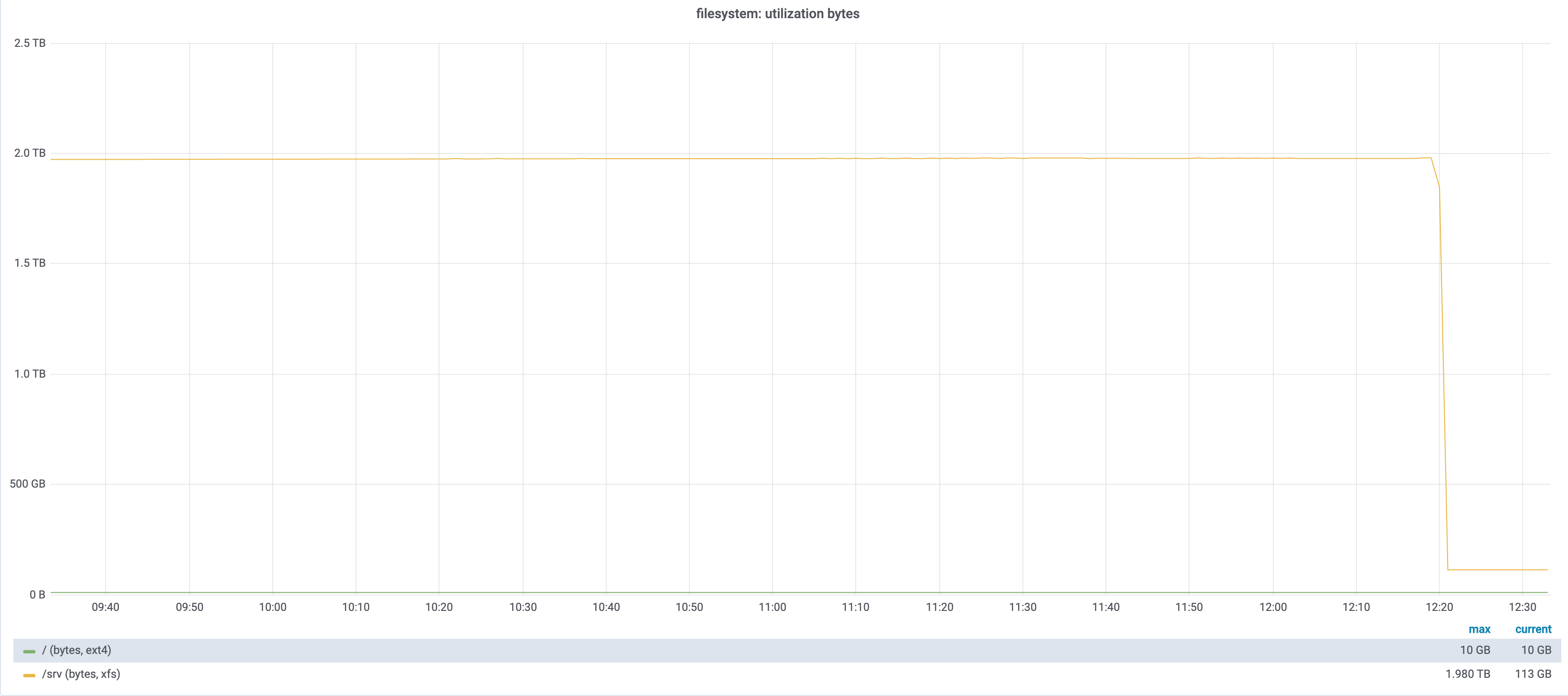
One of the involved tables is: processlist_query_log which is a huge table:
According to the ibd creation dates, it looks like the partitions are purged every month, but for some reason they had lots of rows lately.
For instance:
-rw-rw---- 1 mysql mysql 11G May 2 00:58 processlist_query_log#P#p737911.ibd -rw-rw---- 1 mysql mysql 16G May 3 00:56 processlist_query_log#P#p737912.ibd -rw-rw---- 1 mysql mysql 15G May 4 00:56 processlist_query_log#P#p737913.ibd
That's lots of rows for just 24h.
The subquery involving a left join on that huge table was likely going to take hours, creating those CPU usages.
After truncating the table, everything went back to normal, as that query is now able to finish quickly as the table decreased its size.
For some reason, seeing the file sizes, something has made the partitions to increase almost 5 times since 1st May. Normally it used to be around 3GB or 4GB per day, but since 1st May they are bigger than 10GB. That needs some investigation too.
Sun May 9th
IRC alerts start to show the issue (times in UTC):
[18:00:49] <icinga-wm> PROBLEM - HTTPS-dbtree on dbmonitor1001 is CRITICAL: CRITICAL - Socket timeout after 10 seconds https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org [18:04:27] <icinga-wm> RECOVERY - HTTPS-dbtree on dbmonitor1001 is OK: HTTP OK: HTTP/1.1 200 OK - 85088 bytes in 9.106 second response time https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org [18:24:49] <icinga-wm> PROBLEM - HTTPS-dbtree on dbmonitor1001 is CRITICAL: CRITICAL - Socket timeout after 10 seconds https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org [18:30:19] <icinga-wm> RECOVERY - HTTPS-dbtree on dbmonitor1001 is OK: HTTP OK: HTTP/1.1 200 OK - 85467 bytes in 8.924 second response time https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org [18:35:53] <icinga-wm> PROBLEM - HTTPS-dbtree on dbmonitor1001 is CRITICAL: CRITICAL - Socket timeout after 10 seconds https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org [18:43:23] <icinga-wm> RECOVERY - HTTPS-dbtree on dbmonitor1001 is OK: HTTP OK: HTTP/1.1 200 OK - 85560 bytes in 9.687 second response time https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org [18:54:37] <icinga-wm> PROBLEM - HTTPS-dbtree on dbmonitor1001 is CRITICAL: CRITICAL - Socket timeout after 10 seconds https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org [19:03:53] <icinga-wm> RECOVERY - HTTPS-dbtree on dbmonitor1001 is OK: HTTP OK: HTTP/1.1 200 OK - 85565 bytes in 9.664 second response time https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org [19:13:11] <icinga-wm> PROBLEM - HTTPS-dbtree on dbmonitor1001 is CRITICAL: CRITICAL - Socket timeout after 10 seconds https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org
Sun May 10th:
IRC alerts continue (times in UTC):
[00:46:34] <icinga-wm> RECOVERY - Check systemd state on an-launcher1001 is OK: OK - running: The system is fully operational https://wikitech.wikimedia.org/wiki/Monitoring/check_systemd_state [02:59:12] <icinga-wm> RECOVERY - HTTPS-dbtree on dbmonitor1001 is OK: HTTP OK: HTTP/1.1 200 OK - 81635 bytes in 9.852 second response time https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org [03:08:36] <icinga-wm> PROBLEM - HTTPS-dbtree on dbmonitor1001 is CRITICAL: CRITICAL - Socket timeout after 10 seconds https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org [03:12:16] <icinga-wm> RECOVERY - HTTPS-dbtree on dbmonitor1001 is OK: HTTP OK: HTTP/1.1 200 OK - 82035 bytes in 8.368 second response time https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org [03:17:48] <icinga-wm> PROBLEM - HTTPS-dbtree on dbmonitor1001 is CRITICAL: CRITICAL - Socket timeout after 10 seconds https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org [03:32:34] <icinga-wm> RECOVERY - HTTPS-dbtree on dbmonitor1001 is OK: HTTP OK: HTTP/1.1 200 OK - 81955 bytes in 5.473 second response time https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org [03:38:16] <icinga-wm> PROBLEM - HTTPS-dbtree on dbmonitor1001 is CRITICAL: CRITICAL - Socket timeout after 10 seconds https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org [03:40:04] <icinga-wm> RECOVERY - HTTPS-dbtree on dbmonitor1001 is OK: HTTP OK: HTTP/1.1 200 OK - 83275 bytes in 7.526 second response time https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org [03:45:42] <icinga-wm> PROBLEM - HTTPS-dbtree on dbmonitor1001 is CRITICAL: CRITICAL - Socket timeout after 10 seconds https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org [04:11:48] <icinga-wm> RECOVERY - HTTPS-dbtree on dbmonitor1001 is OK: HTTP OK: HTTP/1.1 200 OK - 81635 bytes in 9.260 second response time https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org [04:17:26] <icinga-wm> PROBLEM - HTTPS-dbtree on dbmonitor1001 is CRITICAL: CRITICAL - Socket timeout after 10 seconds https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org [04:23:00] <icinga-wm> RECOVERY - HTTPS-dbtree on dbmonitor1001 is OK: HTTP OK: HTTP/1.1 200 OK - 81675 bytes in 9.036 second response time https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org [04:28:36] <icinga-wm> PROBLEM - HTTPS-dbtree on dbmonitor1001 is CRITICAL: CRITICAL - Socket timeout after 10 seconds https://wikitech.wikimedia.org/wiki/Dbtree.wikimedia.org
At around 06:46 investigation starts and this is the cross posting:
This has happened again:
root@cumin1001:~# mysql.py -hdb1115 -e "show processlist" | grep Copy
35178632 root 10.64.32.25 tendril Connect 15049 Copying to tmp table insert into processlist_query_log \n (server_id, stamp, id, user, host, db, time, info)\n 0.000
35964338 root 10.64.32.13 tendril Connect 5533 Copying to tmp table insert into processlist_query_log\n (server_id, stamp, id, user, host, db, time, info)\n 0.000
36340984 root 10.64.32.13 tendril Connect 1032 Copying to tmp table insert into processlist_query_log\n (server_id, stamp, id, user, host, db, time, info)\n 0.000
36421610 root 10.64.32.25 tendril Connect 10 Copying to tmp table insert into processlist_query_log\n (server_id, stamp, id, user, host, db, time, info)\n 0.000
36423267 root 10.64.32.25 tendril Connect 2 Copying to tmp table insert into processlist_query_log\n (server_id, stamp, id, user, host, db, time, info)\n 0.000
36429799 root 10.64.32.25 tendril Connect 0 Copying to tmp table insert into strings (string)\n select lower(concat( NAME_CONST('con_prefix',_latin1' 0.000For some reason that processlist_query_log table is getting lots more data and the select which is under that insert take ages to complete:
-rw-rw---- 1 mysql mysql 11G May 6 00:56 processlist_query_log#P#p737915.ibd -rw-rw---- 1 mysql mysql 16G May 7 00:56 processlist_query_log#P#p737916.ibd -rw-rw---- 1 mysql mysql 16G May 8 00:57 processlist_query_log#P#p737917.ibd -rw-rw---- 1 mysql mysql 15G May 9 01:01 processlist_query_log#P#p737918.ibd -rw-rw---- 1 mysql mysql 9.2G May 10 06:27 processlist_query_log#P#p737919.ibd -rw-rw---- 1 mysql mysql 48M May 10 06:47 processlist_query_log#P#p737920.ibd
After truncating processlist_query_log again I stopped the event_scheduler to let all the threads stop, once it was fully clean, I started it but the spike was massive and the host stalled again.
Finally, I restarted MySQL.
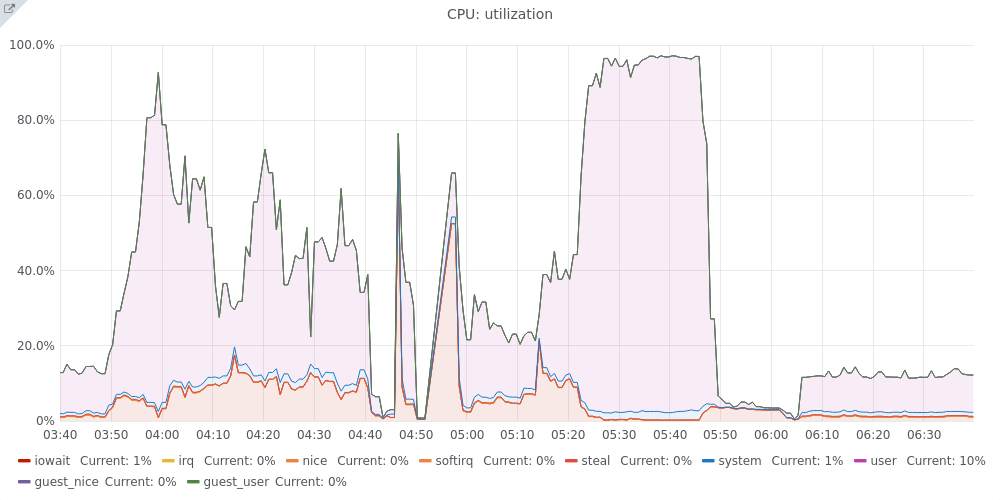
CPU graph is scary with a sudden spike:
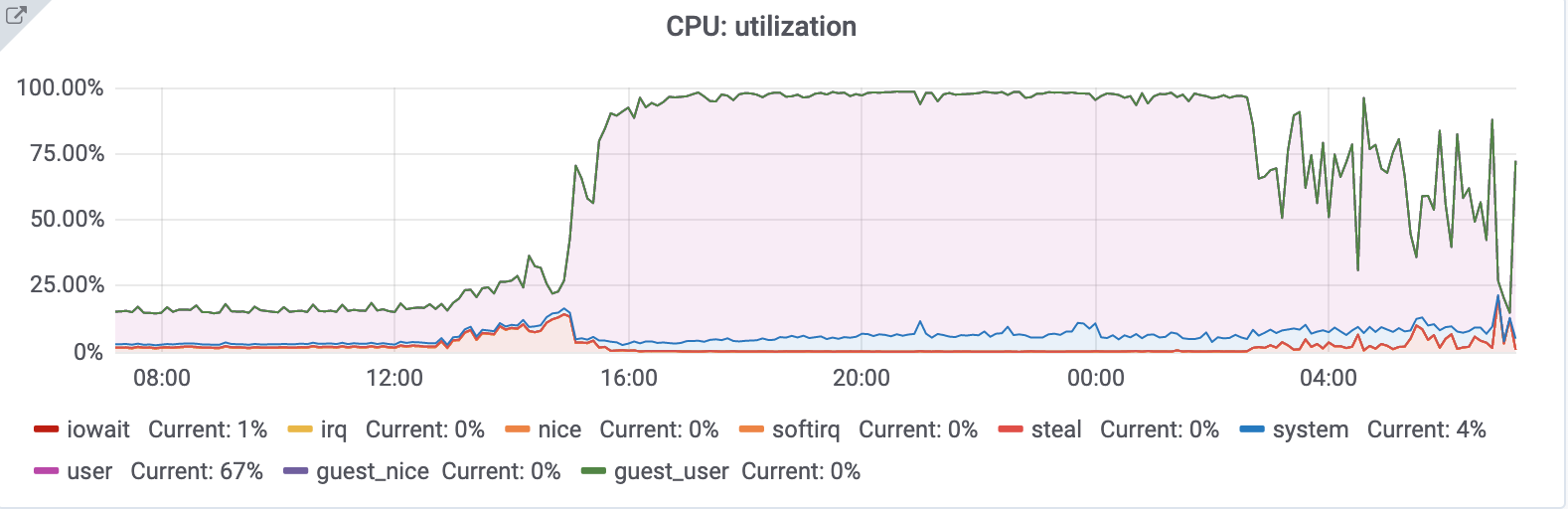
After restarting mysql the server went back to crazy values and had like 1200 connections again
I am still investigating