To provide a baseline of comparison when the internet at large seems to be suffering.
Large transit providers seem like the ideal choice?
To provide a baseline of comparison when the internet at large seems to be suffering.
Large transit providers seem like the ideal choice?
Most transit providers don't participate in RIPE Atlas. Here's the ones who do, in order of CAIDA AS rank:
That's all anchors for the complete set of networks listed on https://en.wikipedia.org/wiki/Tier_1_network#List_of_Tier_1_networks
I think we could scrape a few of those anchors, distributed across networks and geographically, and maybe also a few from large content networks (Amazon and Google each have 15+ anchors, for instance).
Good idea! What's the limit?
I'd suggest:
We could add more regions depending on the "granularity" we want
Which measurements to you plan to scrap?
If its the later then i think picking the google and amazon ones are good choices as we could create a dash board similar to https://grafana-next.wikimedia.org/d/K1qm1j-Wz/ripe-atlas?orgId=1 which presents atlas's view on google and amazon.
If its the outbound tests that we want to scrap then the goal is to pick a stable set of hosts and a common set of destinations that all anchors measure. for this i would pick one of the in build measurements backing DNSMON. Specificity i would probably pick the ping tests going to
On the anchor side of things we can filter the anchors based on the system tags system-ipv6-stable-90d and system-ipv4-stable-90d. One additional feature of using the root servers is that they are measured by all probes in the network, which can also be filtered based on those flags, so there are many more data points. theses measurements power https://atlas.ripe.net/results/maps/
Of course theses are all densely anycast addresses which gives a good overview of the internet however it is a slightly different measurement then the ones going to our unicast addresses so not sure if its the right pick.
Something else we could also do is try to get all stable anchors in Singapore, Amsterdam, Ashburn , Dallas and San Francisco.
While I'm not very concerned about cardinality limits in Prometheus here, I think we'd start to hit some scalability limits of atlas_exporter after even just several more measurements. There's two reasons there:
So unless we can get the streaming client working reliably*, I'd like to only add about 5-10 new measurements here.
(*: I don't see any major changes upstream since I last tried this, so this seems like non-trivial work)
Right now we only scrape our own anchoring measurements*, and that's what I was imagining here, at least for the other content networks.
(*: In fact, our current scraping isn't even all our anchoring measurements -- we only scrape our own anchoring ICMP ping measurements, and should scrape at least our anchoring traceroutes as well, and plot things like median/mode/p95 num-hops -- see T251156)
But your points about DNSMON are great, hadn't known about any of that -- thanks!
There's a lot to think about here, and I'm not sure what to do.
I think I'm leaning towards a few stable anchors in similar geographic locations to our PoPs. Maybe also a few root servers as well even though they're less apples-to-apples. Other thoughts very appreciated :)
I think I'm leaning towards a few stable anchors in similar geographic locations to our PoPs. Maybe also a few root servers as well even though they're less apples-to-apples.
i think i agree with this and think i would prioritize the former as we can always use dnsmon* to get a feel for the later
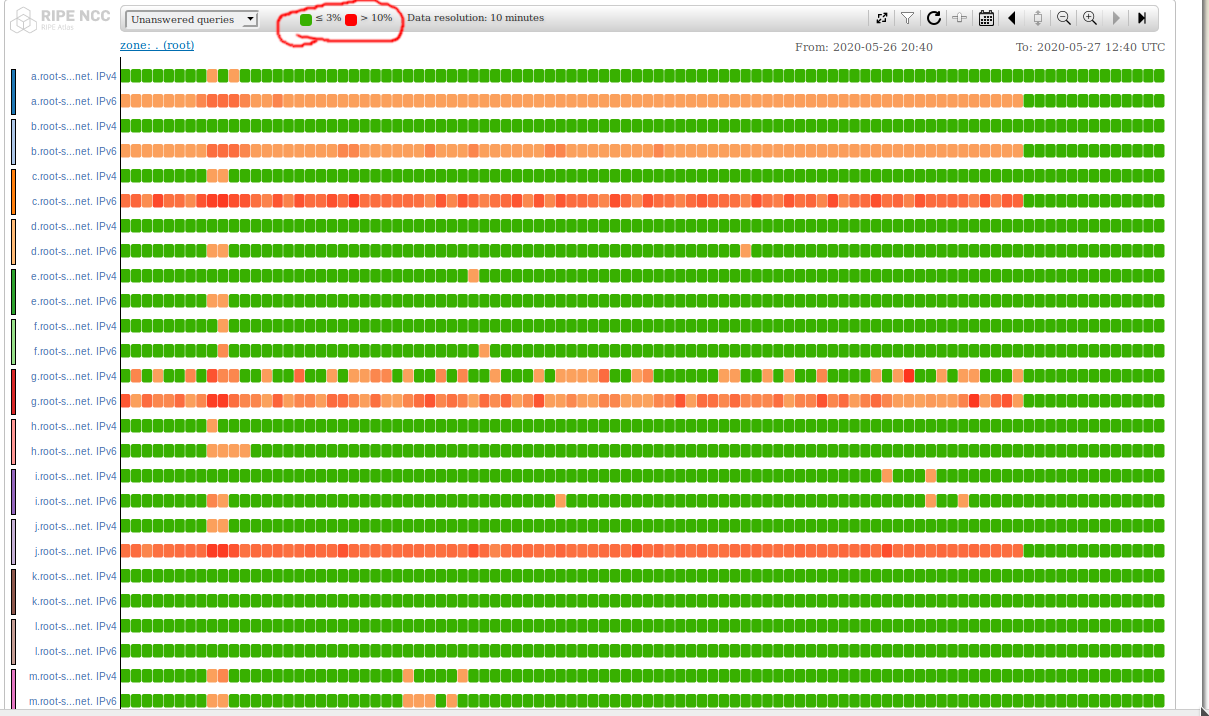
*just a note on DNSMON the default limits are very high to the point that you would only really notice a colour change if a large potion of the internet was down. I tend to set the low value at about 3% and the top value at about 10%, doing so shows an ipv6 event earlier today
It would be interesting to do, but only as more of a curiosity or a research project. NEL serves the actual need here much better :)