Build out a user interface and documentation for interested parties to explore topic models. Details:
- host APIs on Cloud VPS so more control over model size etc.
- build general template for hosting new models on Cloud VPS: https://github.com/geohci/research-api-endpoint-template
- UI should match Research team template: https://github.com/wikimedia/research-api-interface-template
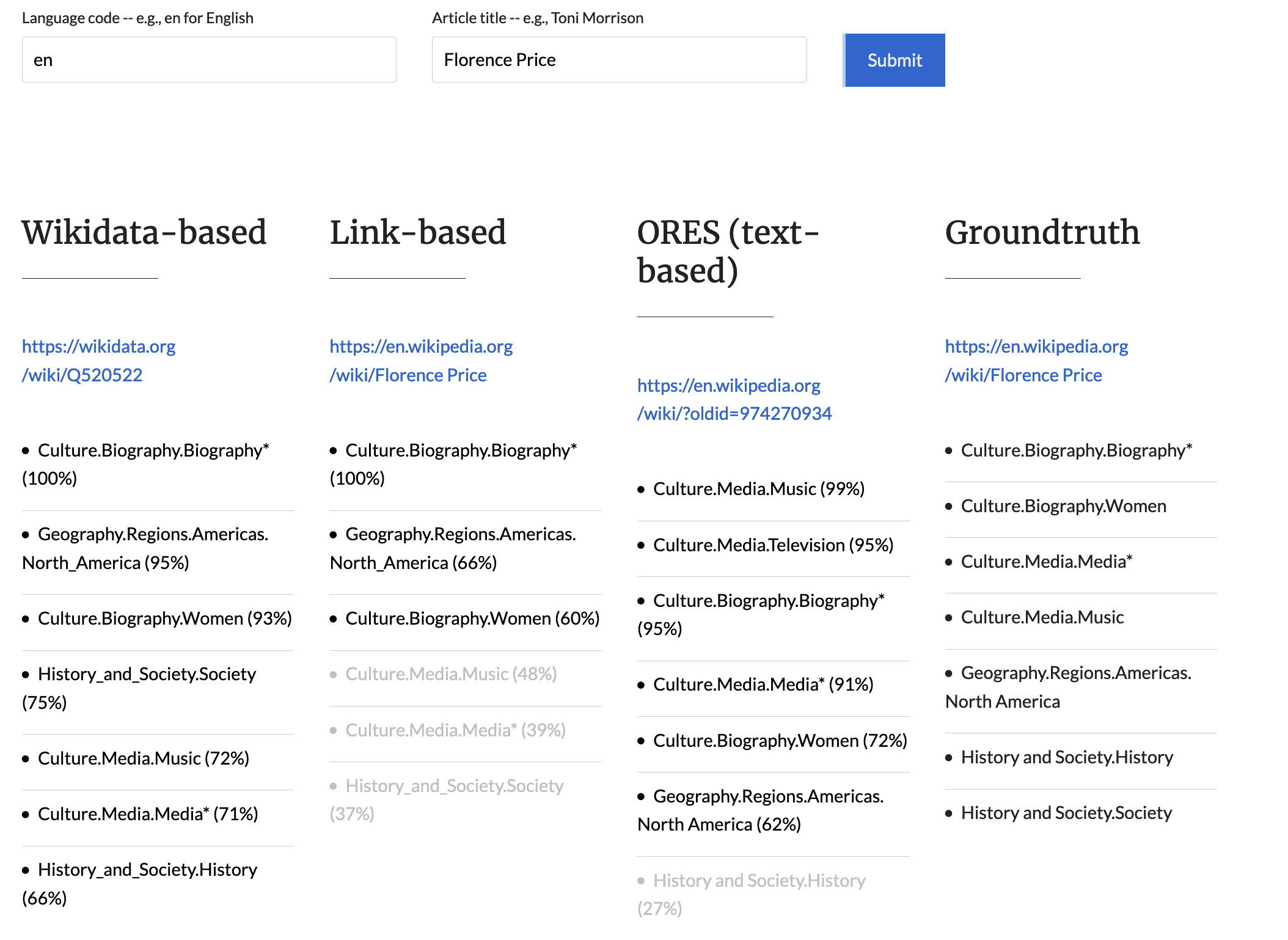
- Ability to query individual models: https://wiki-topic.toolforge.org/
- Ability to easily compare models: https://wiki-topic.toolforge.org/comparison
- Provide comprehensive comparison of ORES (text-based) models, Wikidata-based, and link-based models.
- Add summary of comparison to Meta page: https://meta.wikimedia.org/wiki/Research:Language-Agnostic_Topic_Classification/Model_comparison
Dropped because longer-term efforts going on in this space:
- Determine format for model "report card" that reports both performance and fairness/ethics-related details -- e.g., in the style of model cards.