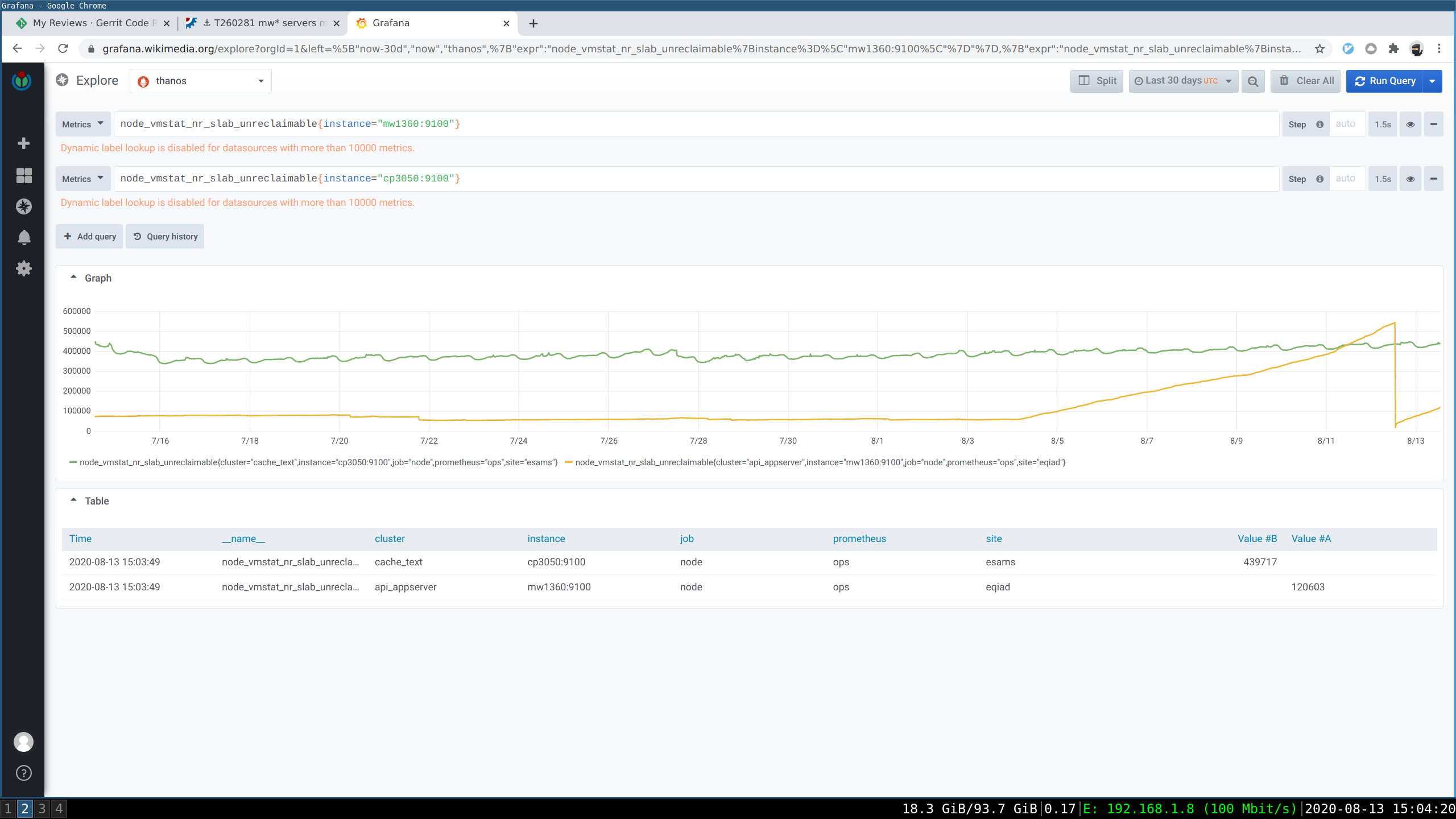
We noticed that some servers have been leaking memory possibly after the 4th of August. There are suspicions that it might be related to the following, but nothing is proven yet:
06:13 <tstarling@deploy1001> Synchronized wmf-config/CommonSettings.php: re-enabling lilypond execution in safe mode 3rd attempt (duration: 00m 58s)
See https://sal.toolforge.org/log/TsQauHMBLkHzneNNt1NY.
Another potential trigger is the puppet change MW firejail: blacklist /run and conf cache given that many calls to mem_cgroup_create were found to be leaking.
We are letting mw1357 depooled so to investigate, @CDanis has installed bpfcc-tools on some appservers, and we have started rebooting both API and APP servers
TLDR for third parties: if you run MediaWiki with $wgShellRestrictionMethod = 'firejail'; you should do so with a relatively recent kernel, 4.19+ or 5.3+ IIRC.