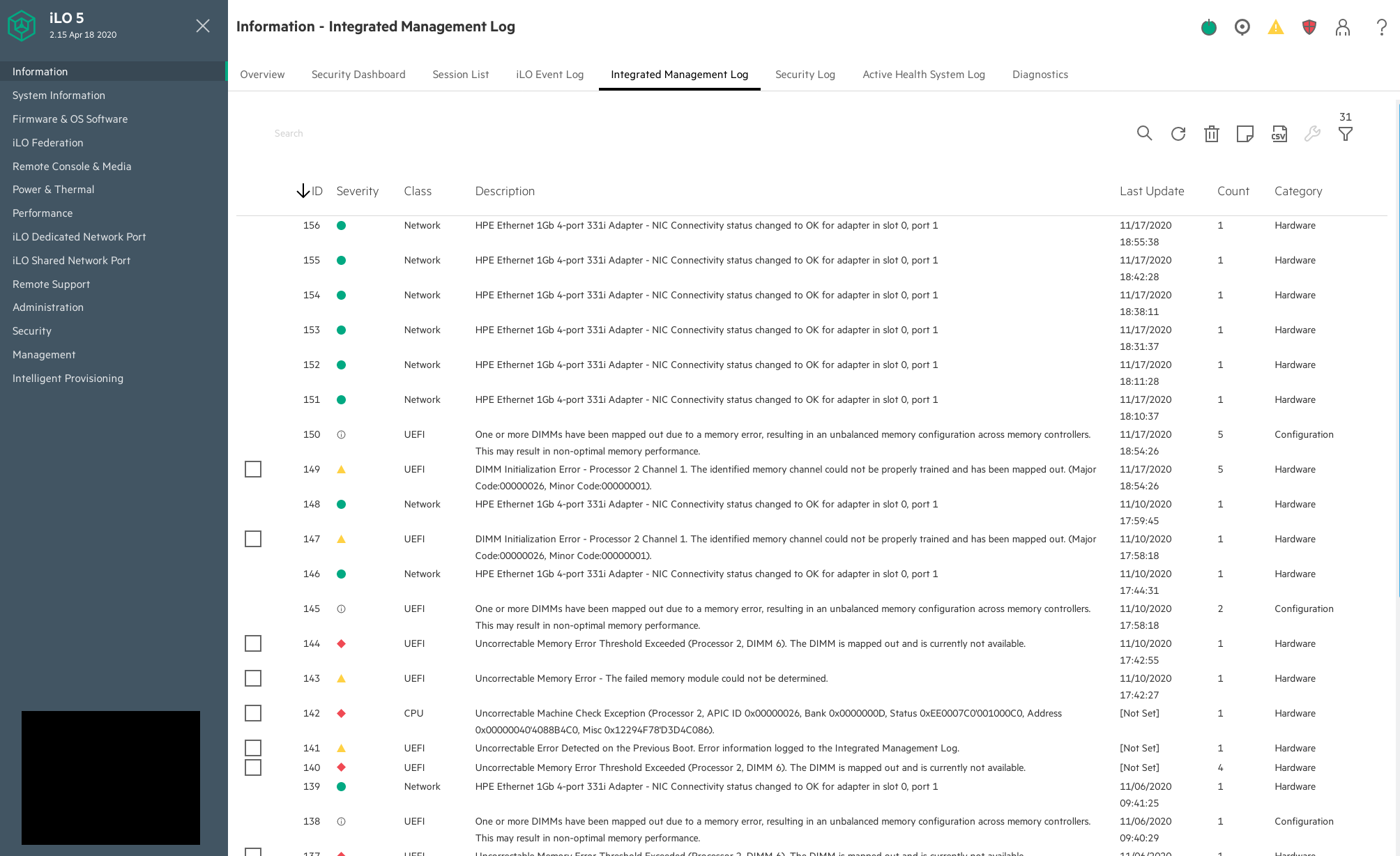
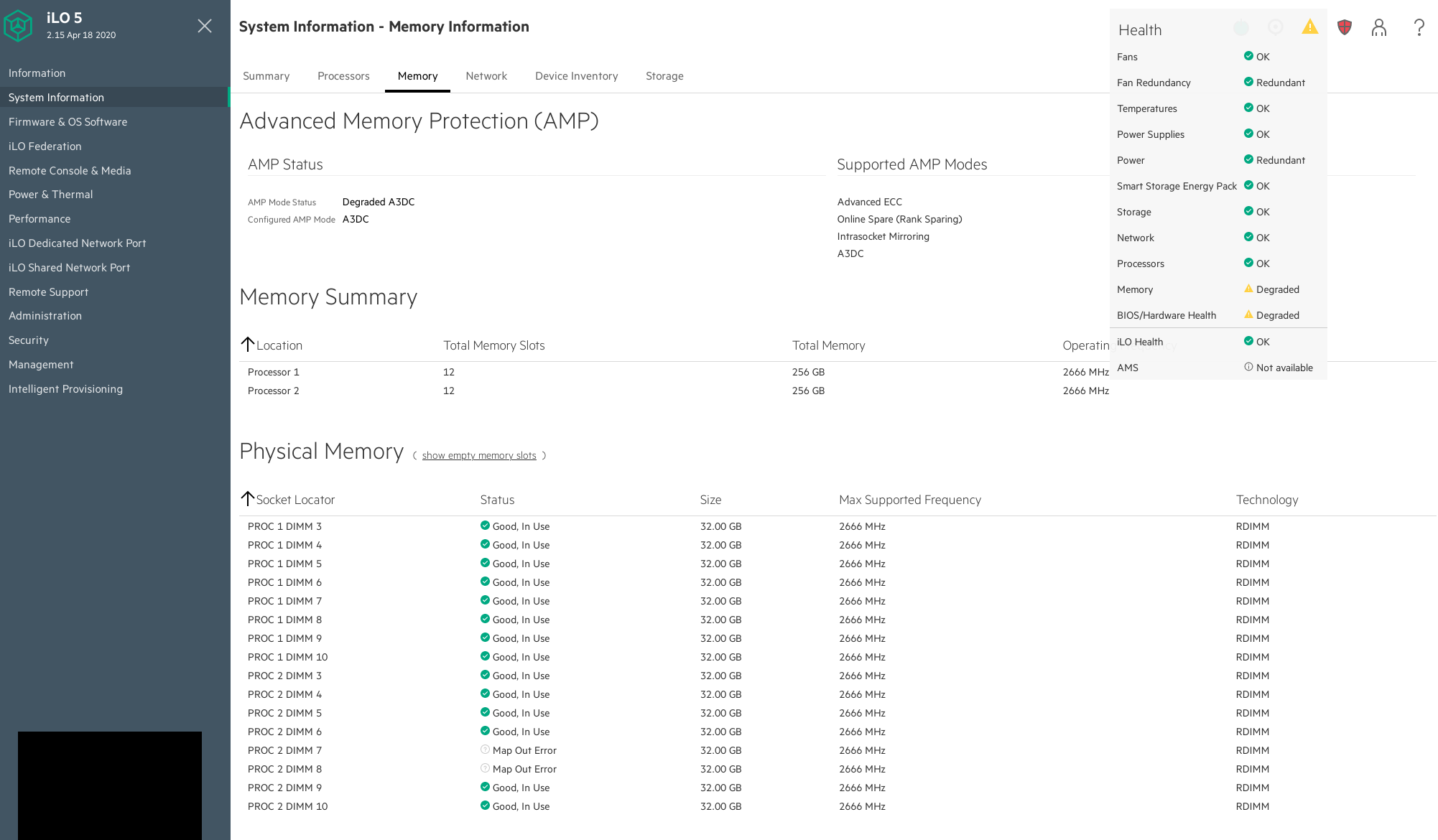
Ongoing issue
Memory keeps failing to be recognized after board change, see: T261405#6617019
Previous maintenance cycle
- - Provide FQDN of system. - done db1139
- - DB systems are left in service until work is ready to begin, then ping a DBA and they'll depool it.
- - Put system into a failed state in Netbox. - cannot be done until the above is confirmed and it is ready for power state changes.
- - Provide urgency of request, along with justification (redundancy, dependencies, etc) - host is enwiki slave, so important but not critical unless we lose more hosts. This shouldn't be UBN, but should reside at top of hw repairs.
- - Describe issue and/or attach hardware failure log. (Refer to https://wikitech.wikimedia.org/wiki/Dc-operations/Hardware_Troubleshooting_Runbook if you need help) - partially done with the original request body below
- - rob working with HP to get replacement part/engineer dispatch.
- - system repaired
- - system reimaged (due to mainboard swap)
original hw failure request body
315 - An uncorrectable memory error was detected prior to this system boot. Action: Check the Integrated Management Log (IML) for additional information. Starting required devices. Please wait, this may take a few moments.... Important information available or errors detected Press 'ESC+1' to continue, or 'ESC+2' for more information System will continue to boot in 1 seconds..