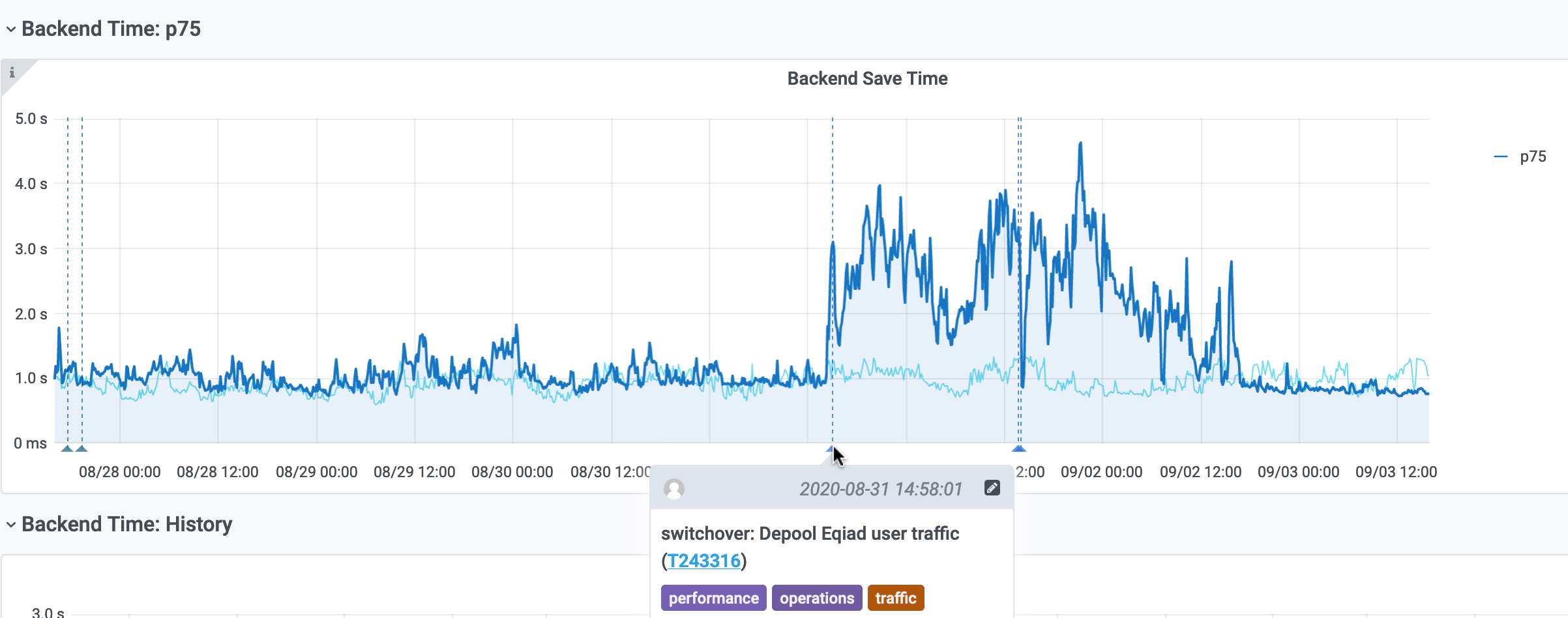
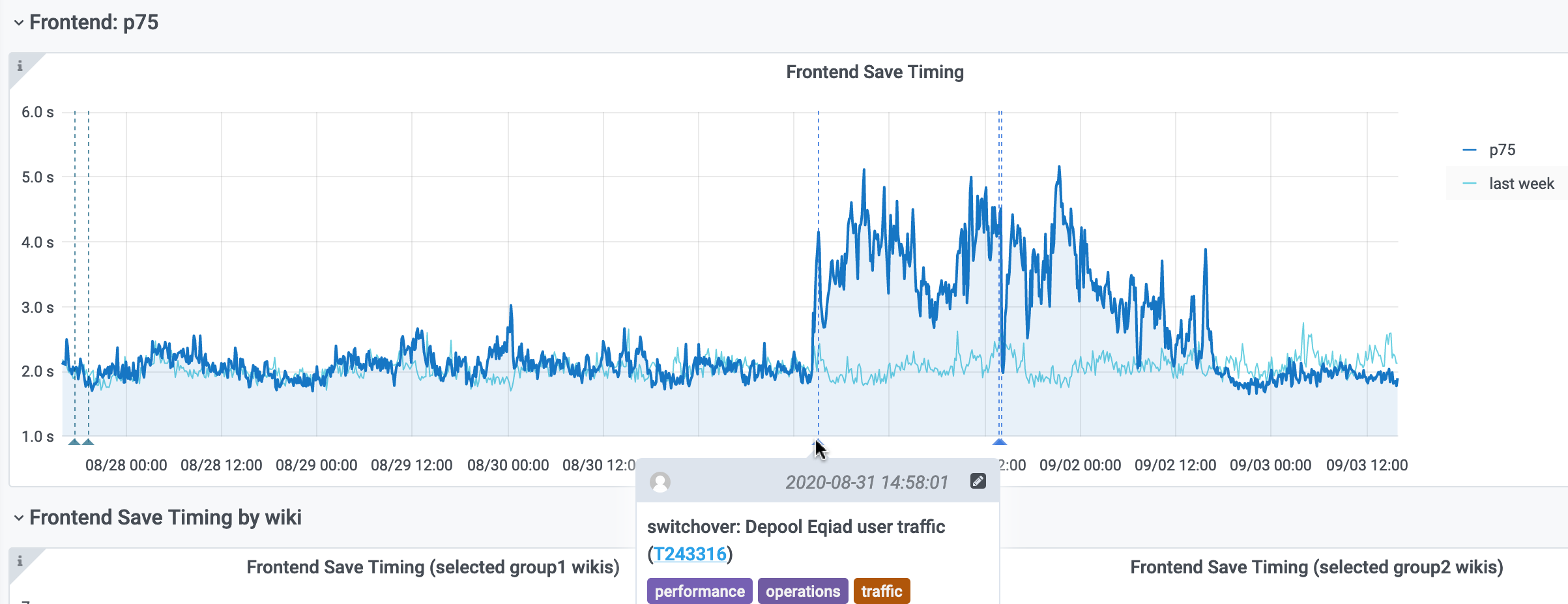
Perf's Save Timing dashboard shows a multiple-second increase in save times, starting about when we migrated active-active services to codfw-only (Aug 31 about 14:21 UTC), but not recovering fully when we moved MediaWiki to codfw today (Sep 1 about 14:04 UTC).
Nothing points to the switchover yet except for the timing; three seconds is much longer than we would expect from cross-dc latency.