Decision Statement Overview Artifact & Decision Record
What is the problem or opportunity?
We currently log JavaScript errors that our users encounter. This helps us make sure the code across our repositories are well maintained and resilient (to connections, skins, across pages).
The same tooling also helps us identify errors in gadgets maintained by editors on wiki.
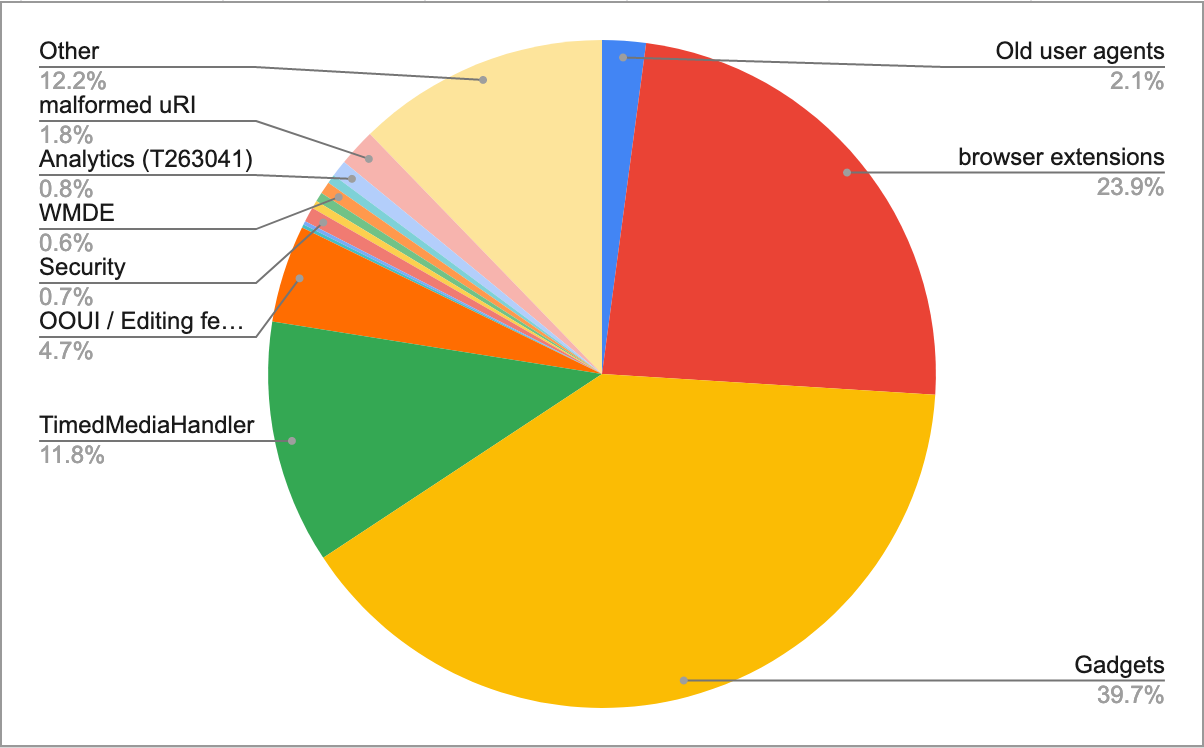
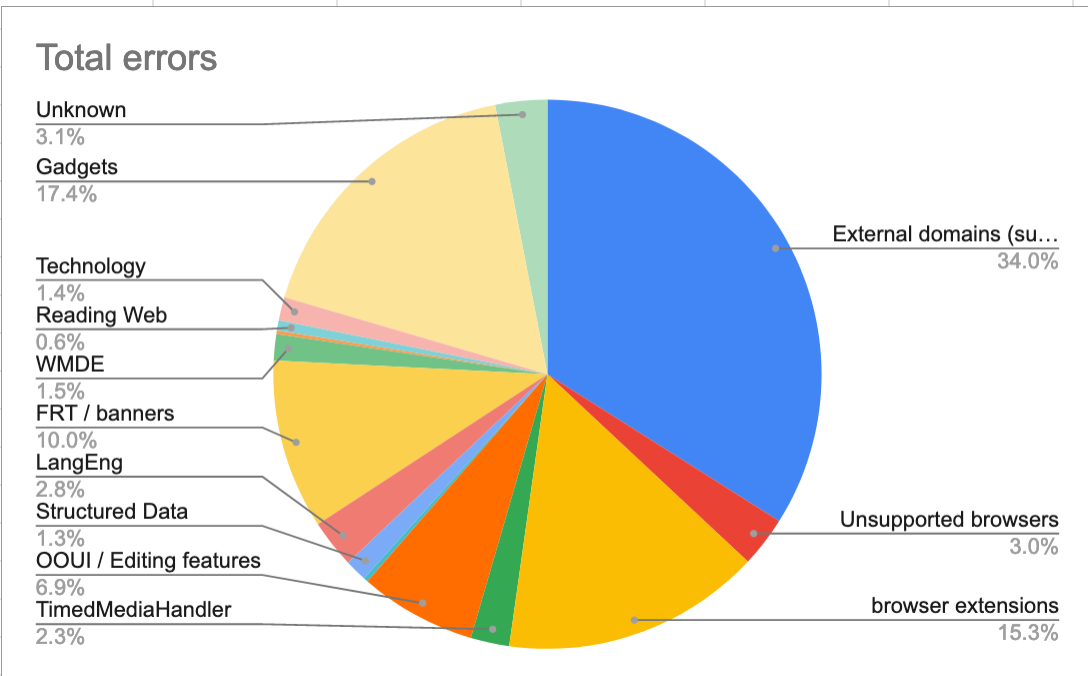
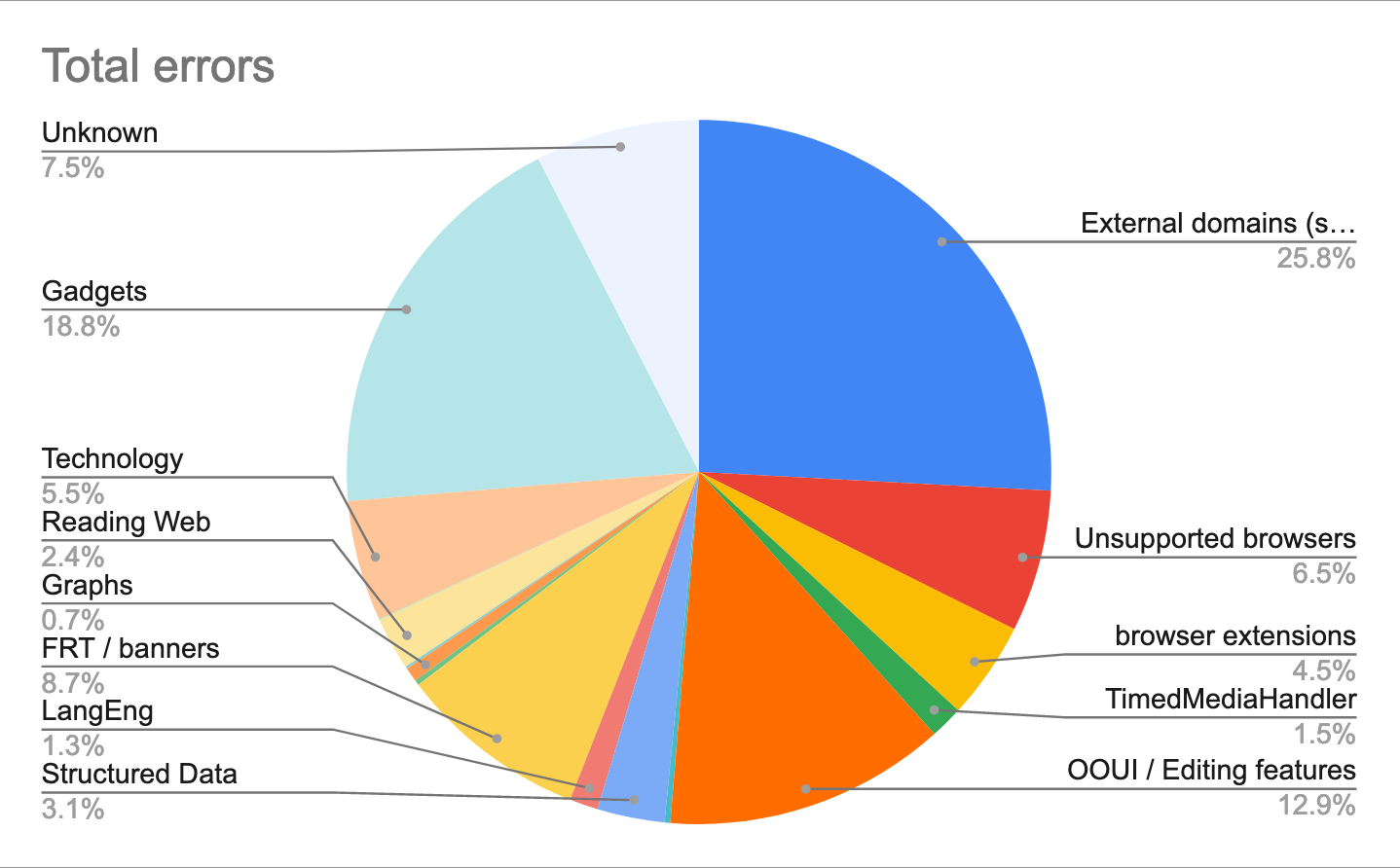
Problematically we cannot easily tell the difference between errors originating in our code and errors originating in gadgets without manually triaging or fixing every issue. This is costly work. This manual work has been done however and at least 20% of our errors originate in gadgets.
This is a problem as editors currently do not have access to these logs without signing an NDA, may not share the same motivation/values around code quality or may have written their gadgets some time ago and have since left our projects. Where Wikimedia-staff have fixed errors, there has sometimes been friction has some users take issue with staff editing scripts that editors see themselves as "owners".
Historically Wikimedia has set the informal expectation that it does not maintain community gadgets, however, if gadget errors are equal alongside Wikimedia code errors, it's hard to ignore them. When gadgets change jQuery version or introduce other code that breaks experiences for users, it becomes hard to ignore.
It would be useful to get interested parties involved in a conversation to reflect on the status quo, how much we should care and if we don't care modify our code to reflect this.
Goals:
- Define a policy around gadget/user scripts that lives on a wiki page somewhere. It should make clear to WMF staff and gadget developers expectations around who can edit, what is expected with regards to quality and errors, and what should happen to gadgets where the maintainer has retired or lost interest.
- Our error logging system should be built around this policy, potentially programatically distinguishing between WMF errors and gadget errors. This may come with trade-offs such as no longer running gadgets in global scope.
- Gadget developers should be able to improve their code if they wish. It should be decided whether the current tooling with NDA i sufficient or if appropriate tooling needs to be provided.
- The existing gadget system should be modified if necessary to reflect the new policy.
What does the future look like if it's achieved?
- WMF spends less time triaging and fixing broken gadgets
- When building and deploying new products WMF is able to clearly determine impact of changes that break gadgets
- Users gadgets do not suddenly stop working
- User gadget developers and WMF staff enjoy a better relationship, better communication.
What happens if we do nothing
Certain staff members including myself will continue to try to prop up the system by keeping an eye on issues on-wiki and fixing them as they arise. They will do this until they lose interest/burn out.
When nobody is looking at errors, unchecked the amount of errors will rise, leading to alerts in grafana and noise in the error logging tooling will grow large.
Eventually this might lead to a high volume of errors that make the tooling useless, and potentially break the EventLogging platform it's built upon. If this ever happens, worse case scenario is that this valuable infrastructure will lose its value, and be turned off, and we will go back to how it was before we had error logging.
More background
Blog posts
- https://jdlrobson.com/posts/2020-09-28_diving-into-wikipedia-s-ocean-of-errors-a6b6be92bf2e?r=jt
- https://diff.wikimedia.org/2021/03/08/sailing-steady%E2%80%8A-%E2%80%8Ahow-you-can-help-keep-wikimedia-sites-error-free/
Motivation for this ticket
In a 12 hr period 251 / 2,530 production errors came from gadgets e.g. Error: module already implemented: ext.gadget.Cat-a-lot - none of these are actionable as it's not clear how they were loaded. Note the number is likely a lot larger as many of these are likely to be surfacing as "Script error" due to cross domain loading.
Presumably, this is because modules can be loaded via different means from different projects via global scripts.
If a module is already implemented I would prefer it logs a warning rather than an error. Do we really need to throw an error here (asking ResourceLoader expert)? If so, could we at least disable the error logging for modules that are gadgets