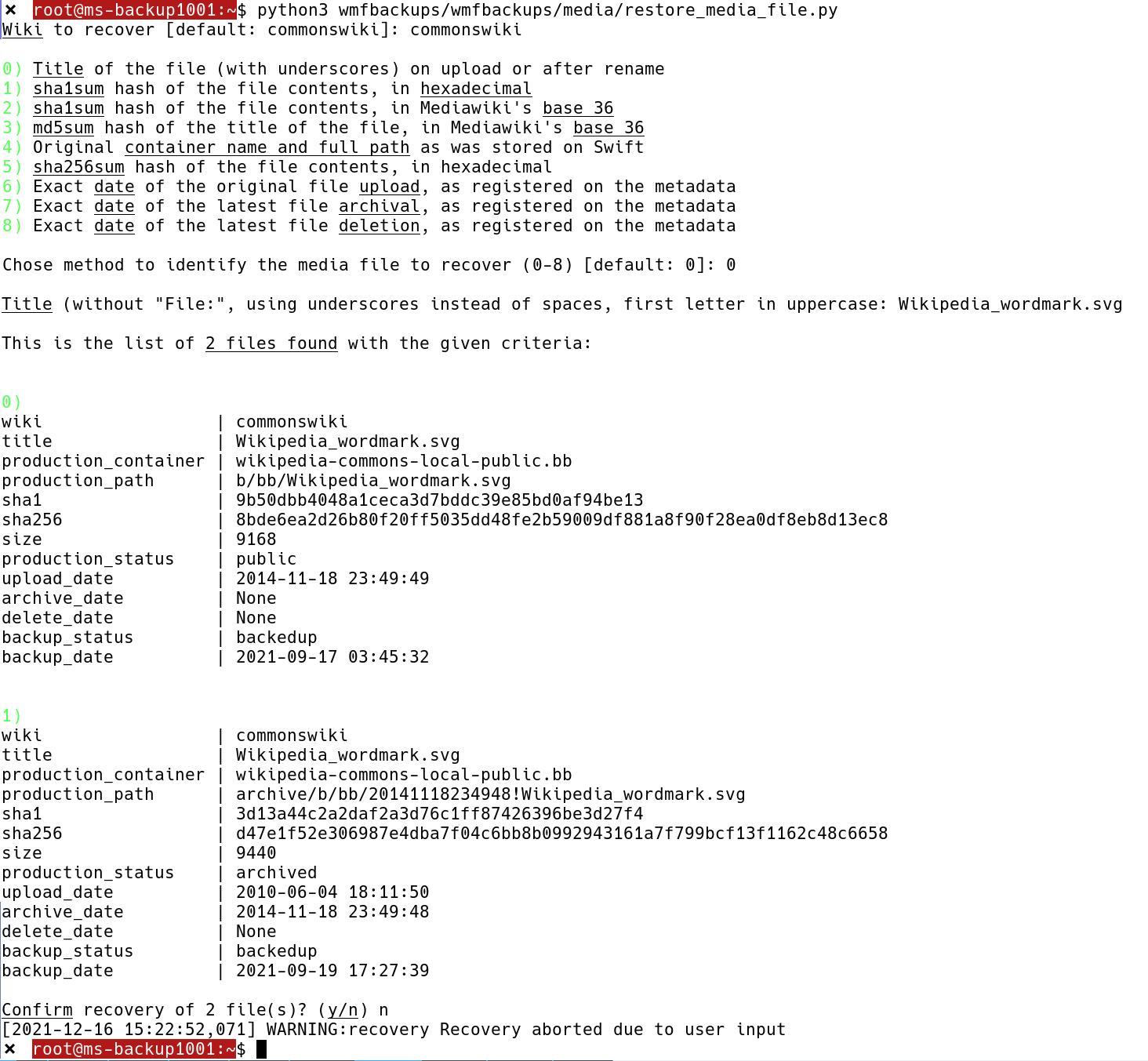
There is a desire to have 100% backup coverage of all data hosted at Wikimedia Foundation in a centralized solution. After wiki content database backups were finally set up (T79922), multimedia –specifically data stored on Swift to serve Wiki non-text content– was the highest priority in terms of impact (if lost), overall size, and desire by the several WMF stakeholders to be backed up.
While there is redundancy in place for media, high availability, while a must to protect against service loss, is not a substitute for proper backups: software bugs, operator mistakes, employee sabotage, hardware issues and malicious attacks are all vectors that online redundancy would not necessarily protect effectively against. Geographically remote offline copies are needed -in addition to service HA- to effectively recover in the eventuality of a data loss.