We were paged by lots of services starting at Thu Sept 24 14:40:04 UTC 2020 with the labs-ip-alias-dump process. The problem was clearly one of getting timeouts and failures contacting various openstack services
eg.
Sep 24 15:03:09 cloudcontrol1004 wmcs-dns-floating-ip-updater[28525]: requests.exceptions.HTTPError: 504 Server Error: GATEWAY TIMEOUT for url: http://openstack.eqiad1.wikimediacloud.org:9001/v2/zones
We initially suspected everything from haproxy to firewalls, but as of this ticket's creation, we haven't seen a root cause. The actual failures in openstack services were clearly caused by a concurrent split brain in both Galera and RabbitMQ at around the same time (14:48-ish UTC). During that time, the services reported a network partition, and TCP retransmit errors popped up:
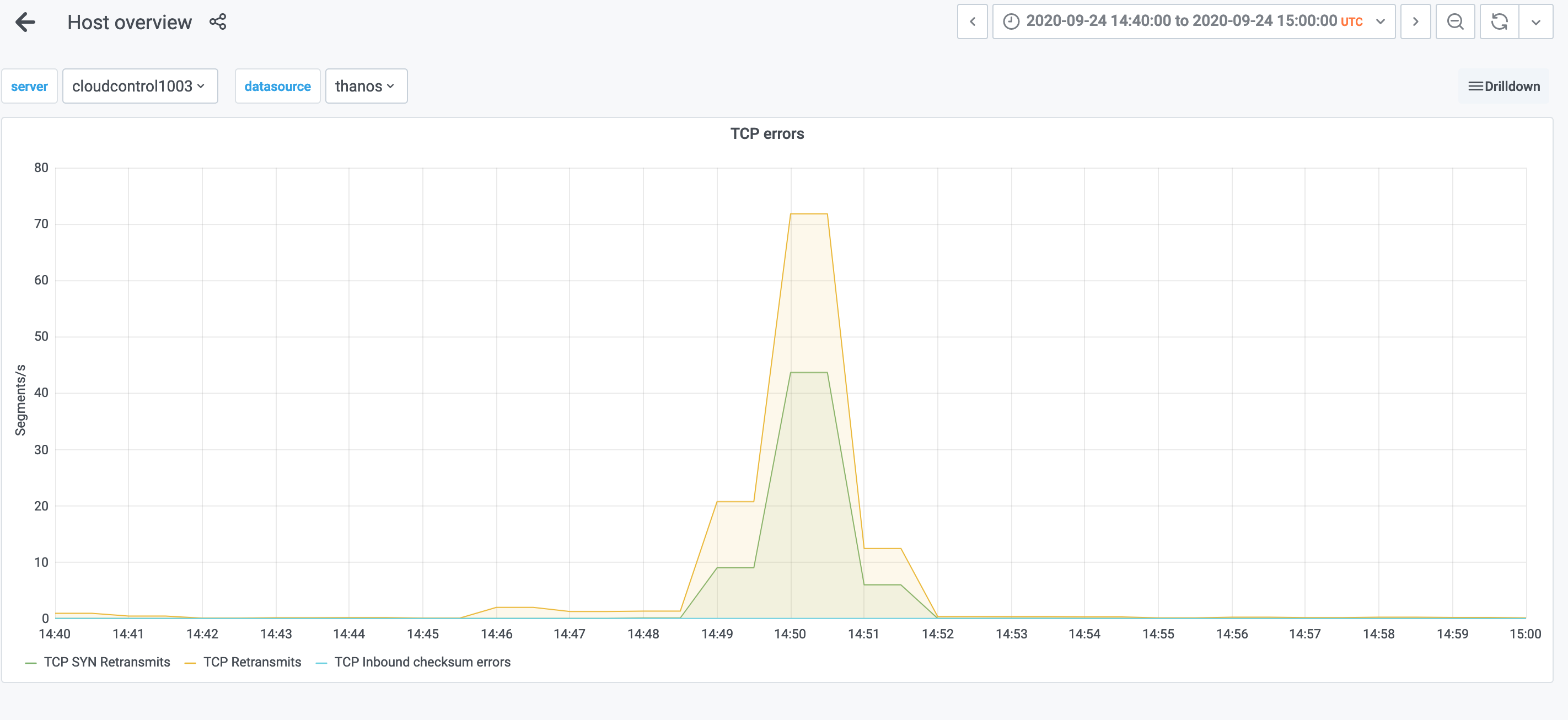
Naturally, network and other activity went down. Memory saturation also spiked:
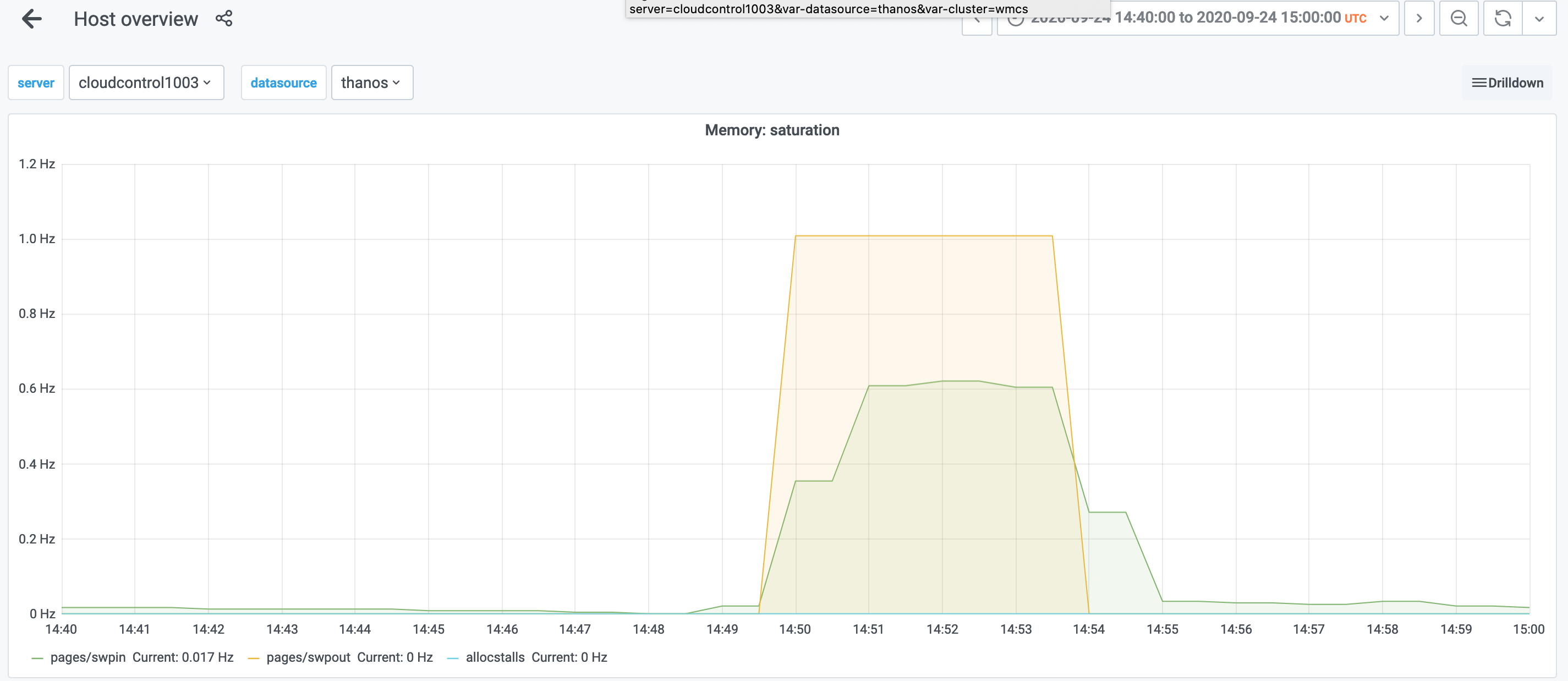
Memory utilization remained stable.
That roughly describes what the event looked like. Hopefully, we can refer to this ticket, update this and keep it from happening again.