Hi all -
Ok this is fun and interesting, so please chime in if you are interested!
The Problem:
In our research of large Wikimedia data reusers, an obvious pain point is accidentally ingesting our live content that might have vandalism in the time frame between when editors pick it up. This causes obvious risk to the product they are reusing our content in but also creates a situation where there is content our community handles that is a phantom living outside of our projects.
The Solution:
We are building a feature into our alpha HTML Exports on Okapi to try to create different "safety" levels of our corpus of content as to fit the needs of different users. We are creating 5 different exports for each text-based wiki project that fit different levels on the spectrum from Safe (hyper community reviewed content) to Fresh (which is the raw data feed, similar to the current offerings). Below is a mock of the what it will look like for the downloaders. Disclaimer "Credible -> Fresh" is not the language we're using here, these are just mocks.
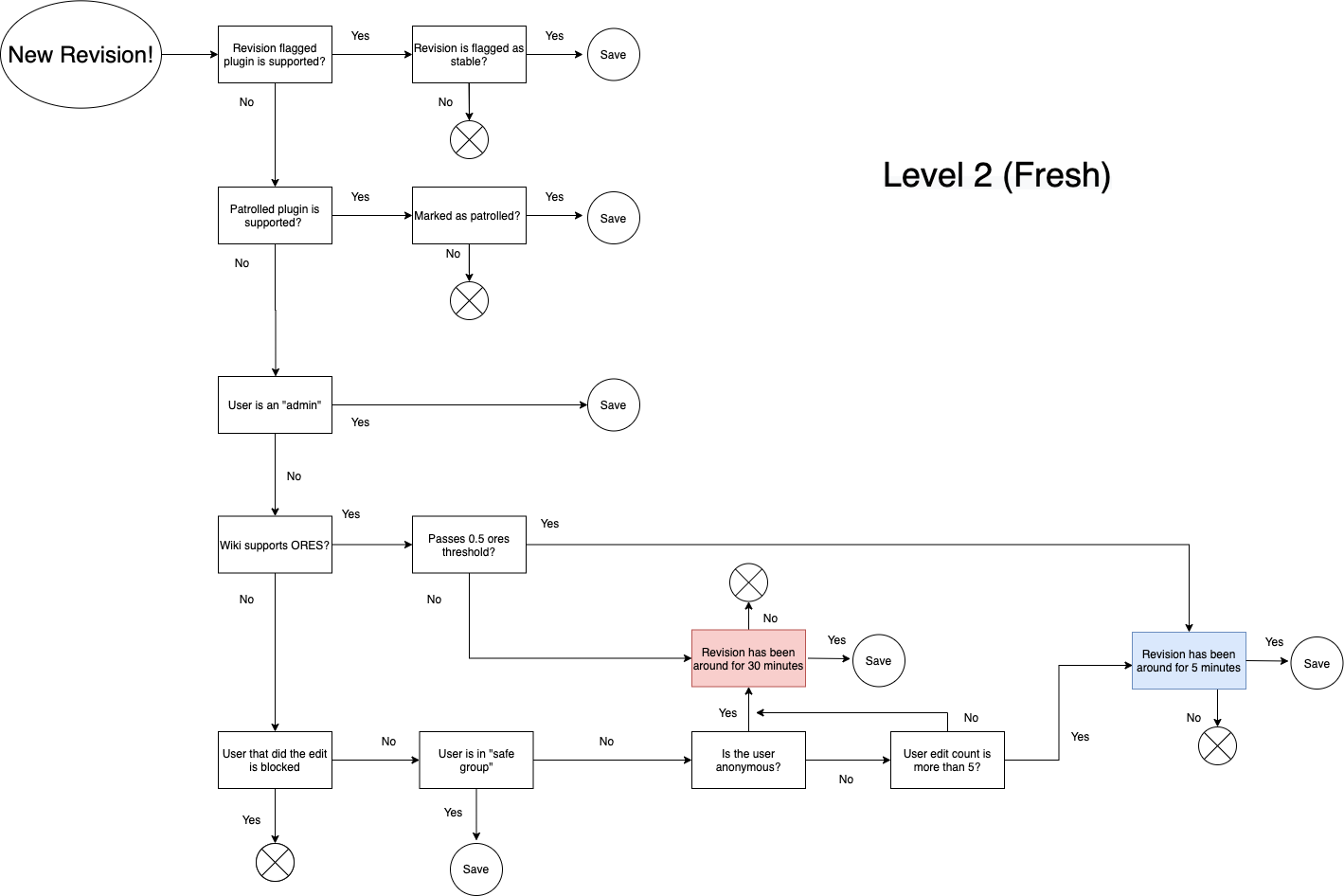
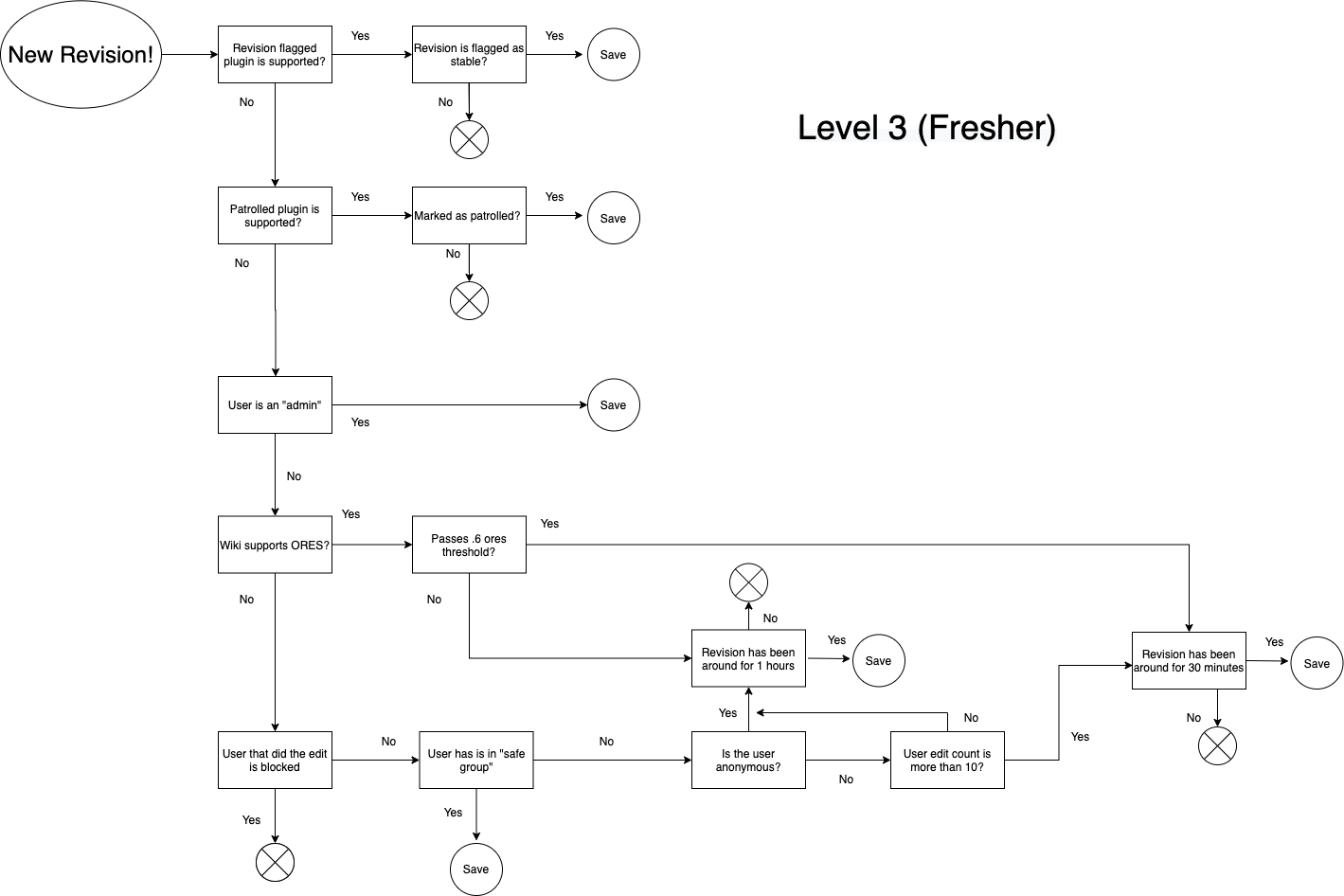
We are using inputs from the project/communities themselves; i.e Flagged Revisions, Patrolled Revisions, ORES Thresholds, Edit Count from user (in case of anonymous users), Time of edit live on project. Below is a TL;DR of the major differences at each level as well as a diagram explaining the data flow. Open to suggestions, critiques, and thoughts.
- Level 1: Raw data feed; no considerations
- Level 2: Freshest; .5 ORES threshold, 5 minutes live if passes threshold, trust anonymous user after 5 edits, trust anonymous edit after 30 minutes live.
- Level 3: Fresher; .6 ORES threshold, 30 minutes live if passes threshold, trust anonymous user after 10 edits, trust anonymous edit after 1 hour live.
- Level 4: Safer; .67 ORES threshold, 3 hours live if passes threshold, trust anonymous user after 50 edits, trust anonymous edit after 12 hours live.
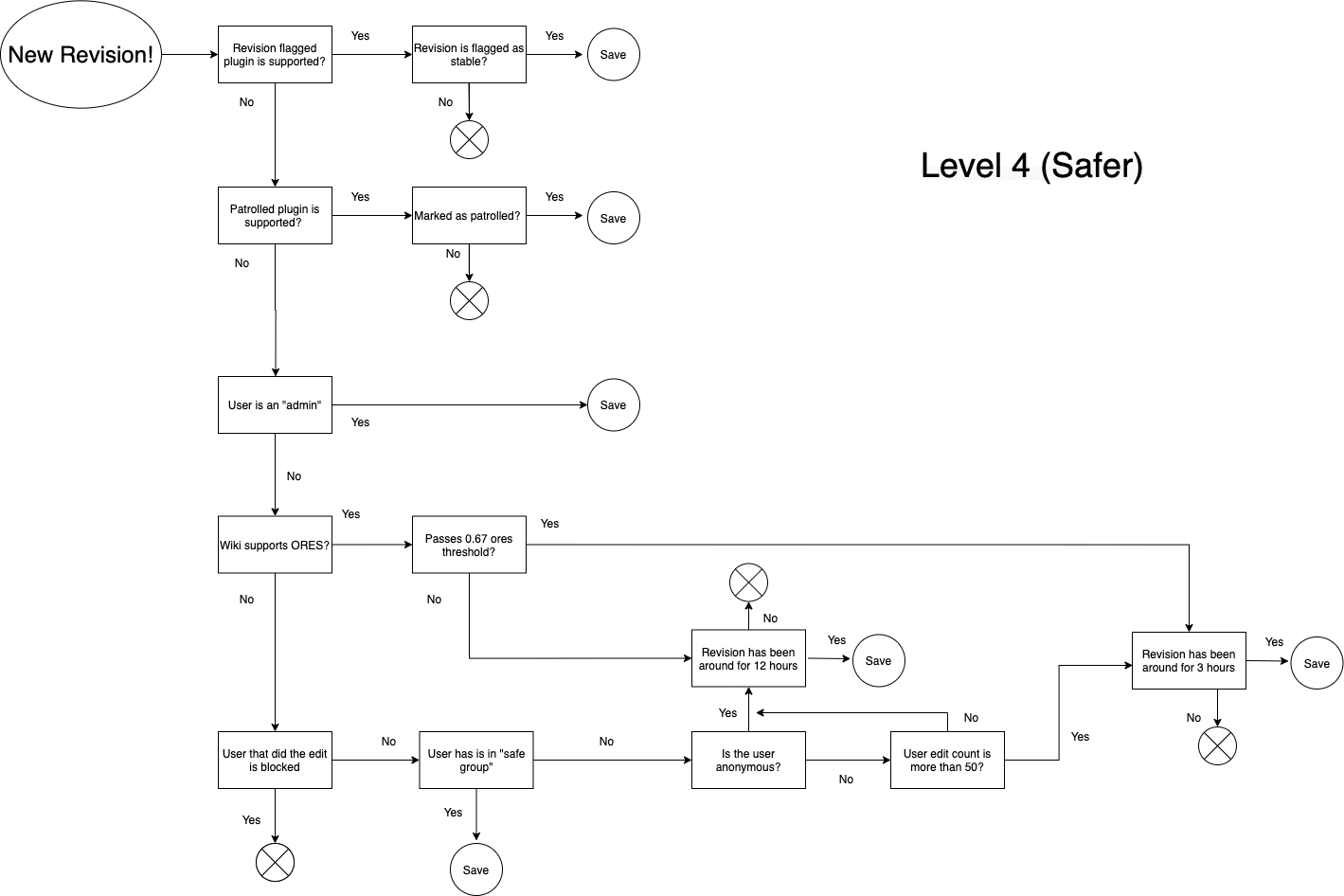
- Level 5: Safest; .7 ORES threshold, 6 hours live if passes threshold, trust anonymous user after 100 edits, trust anonymous edit after 1 day live.
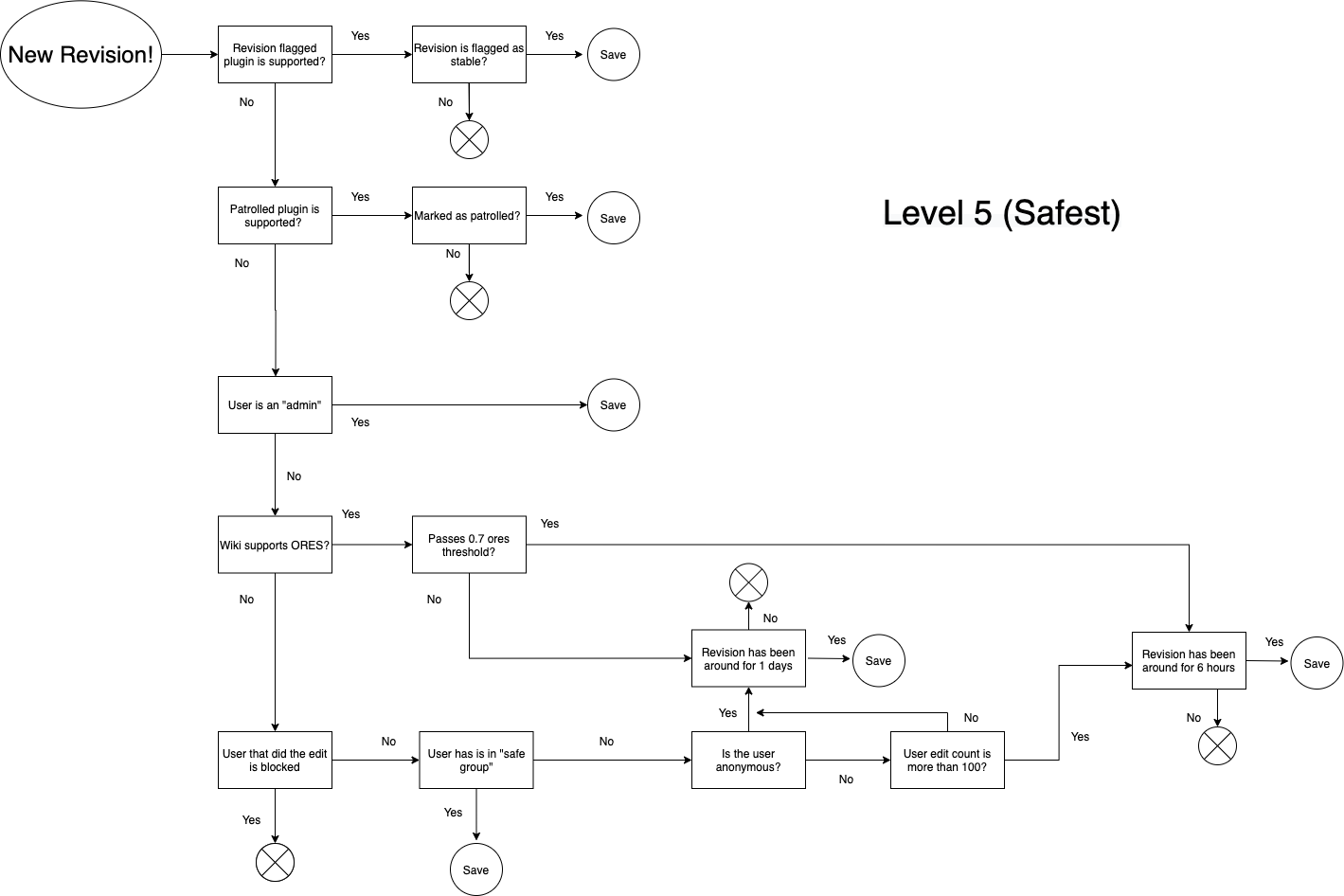
Let us know your thoughts, resources around different projects around Time Delays would be very helpful as these will different along project lines - we understand that and want to defer to the folks that understand that to help guide those decisions. Thanks all.
Ryan