As a searcher i would like search to not reject my requests so i can do searchy things
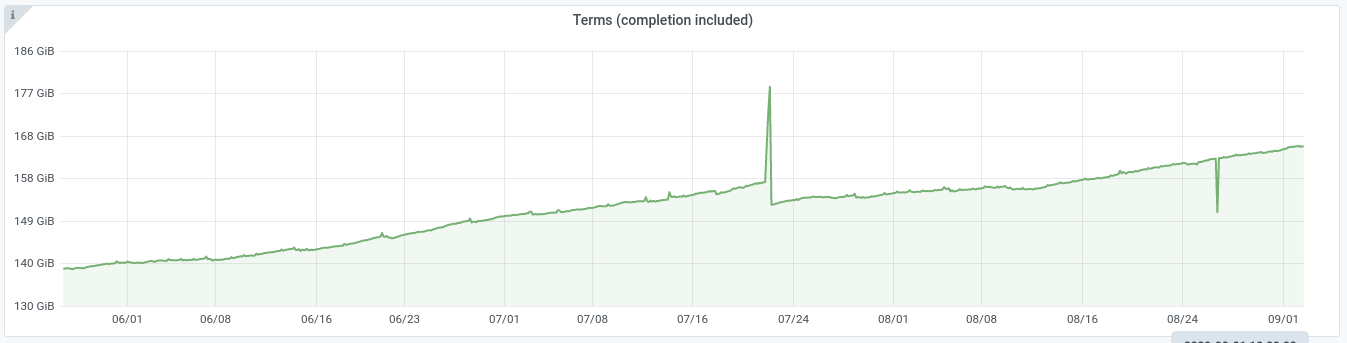
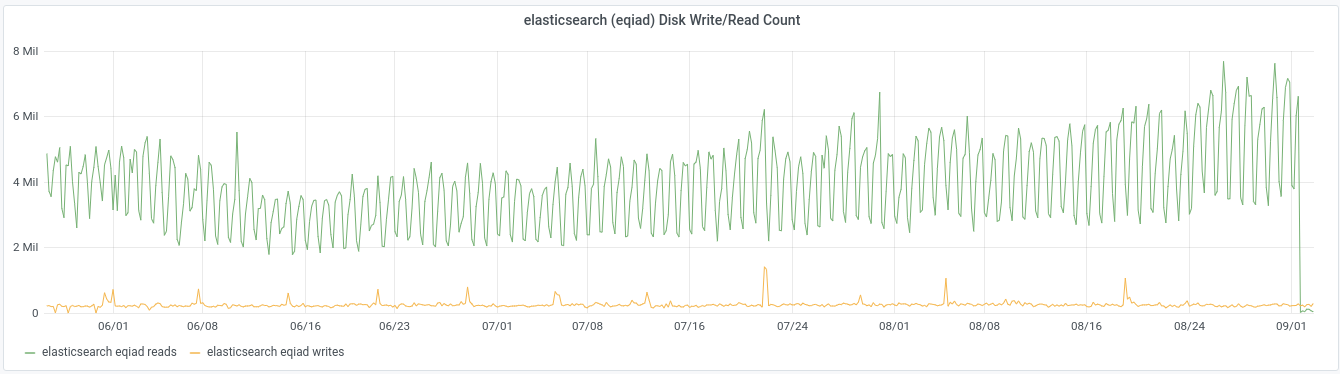
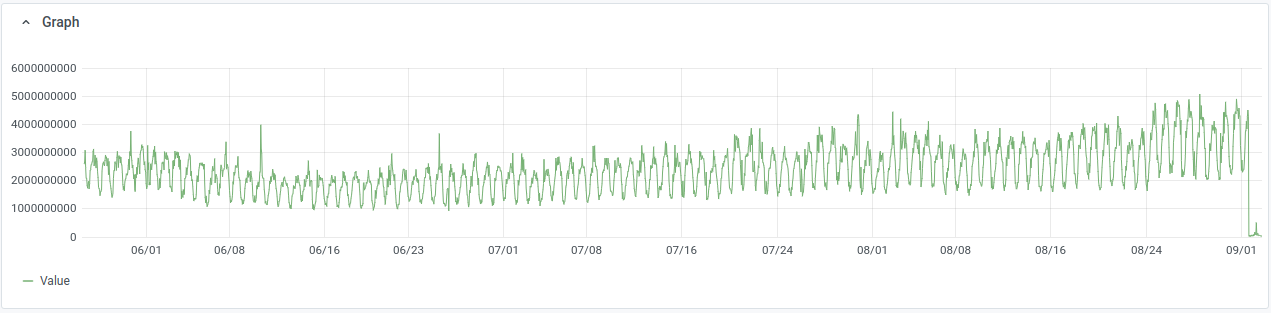
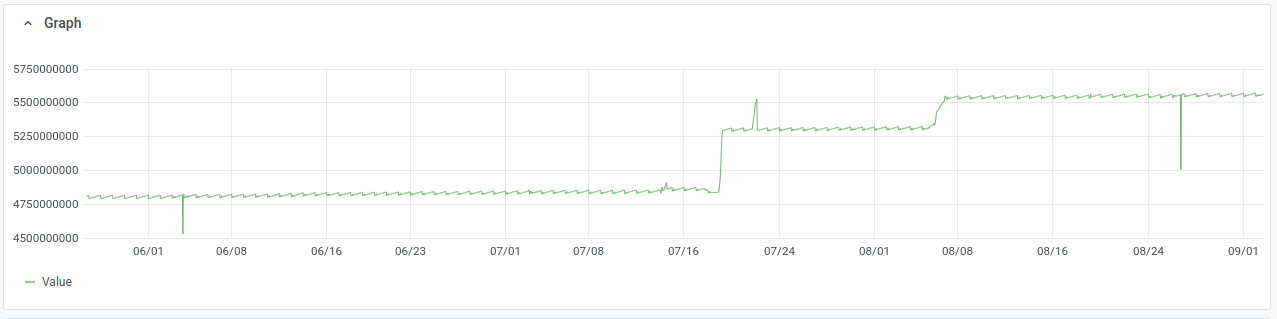
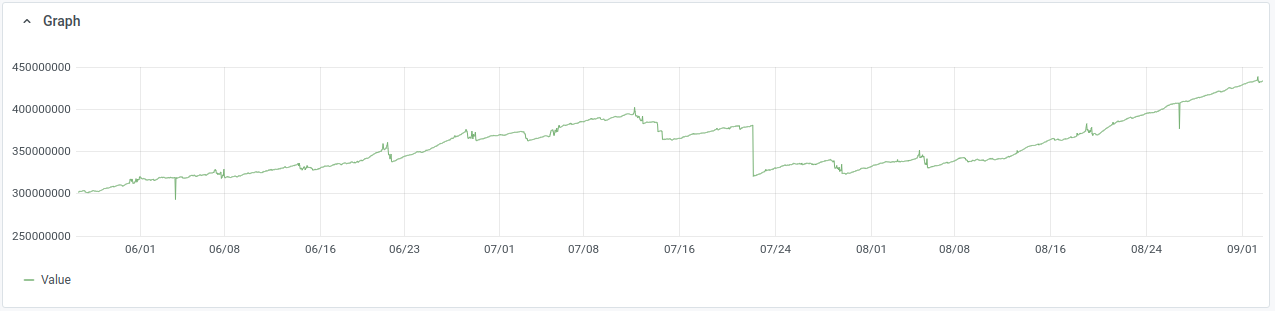
Codfw cluster alerted today. While looking into it noticed that disk utilization is surprisingly high, >30% on many servers and peaks >60% on some. Looking back over graphs[1], read rate has been high(5-7GB/sec across nodes) on codfw since we moved to that DC, looking back at eqiad pre-switchover it was similar but slightly lower (3-5GB/sec). The relevent prometheus metric only goes back to may 25th, but as recently as mid june we were doing 2-2.5GB/sec across nodes. It's been some time since i looked into this, but there was a time in the past when 500MB/sec across the cluster was typical read usage.
This looks like the hot set, the data that is referenced at query time, has grown larger than our available disk cache. The graphs show clear growth since the beginning of july, left unchecked this will certainly lead to resource starvation and regular interruptions of service.
[1] sum(irate(node_disk_read_bytes_total{cluster="elasticsearch",device=~"[vsh]d[a-z]"}[5m]))