lvs1016 has interface errors on just enp5s0f0. They started at a very small rate ~10 days ago and have been growing slowly ever since. This in turn has caused a slowly growing rate of random ProxyFetch healtcheck failures (all on vlan 1018, which is attached to the physical interface experiencing the errors). As of today, the rate is high enough that it's causing sporadic icinga alerts for pybal pooling issues from all the ProxyFetch failures.
Attached is the network errors over 14 days from grafana Host Overview, edited to cap at 300pps so that the rare large spikes don't drown out the interesting pattern:
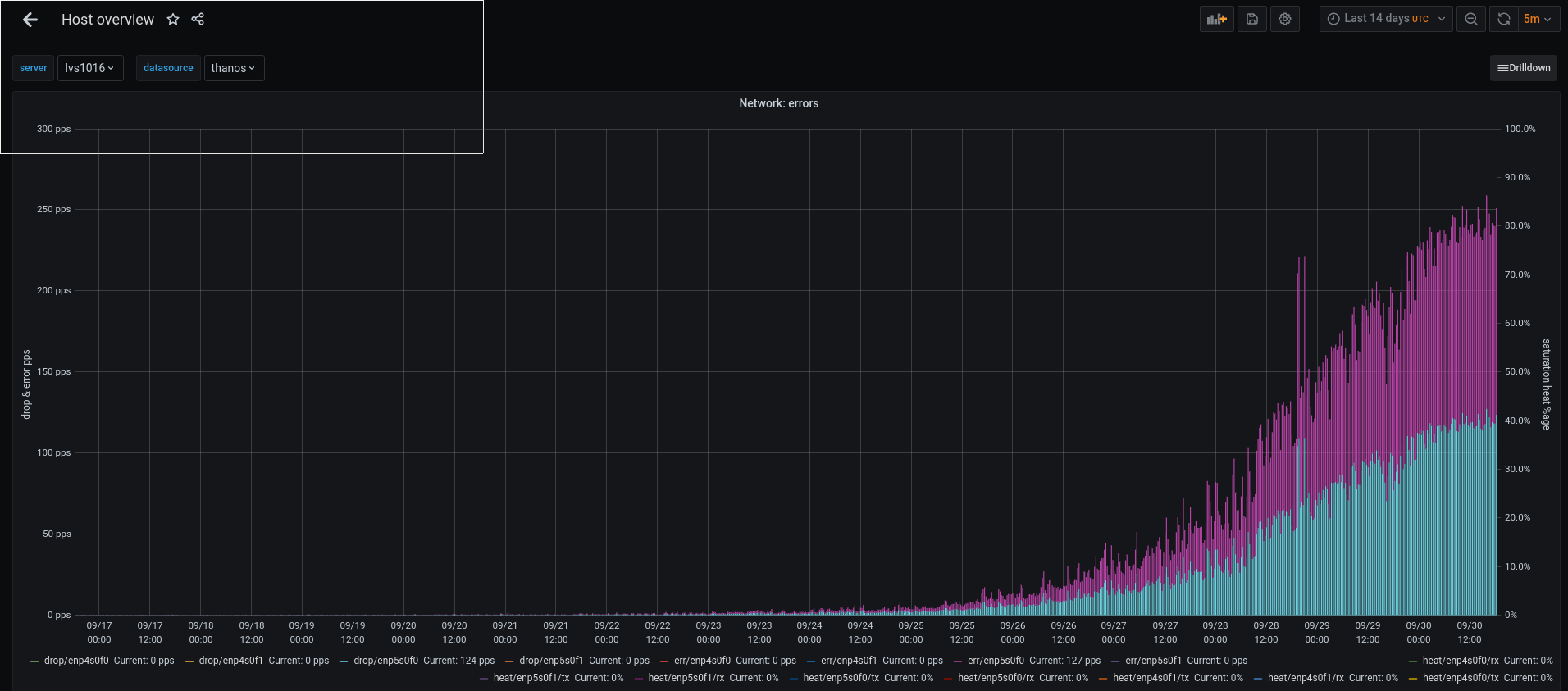
Does this look like a signature from anything we recognize, like a slowly failing transceiver?
It's also possible the drops here are just because we're reaching some kind of effective pps limits due to new monitoring checks being added? It would seem unlikely we'd hit a pps limit with healthcheck traffic given the interface byte rates seems totally sane and reasonable, though, and we're not having any similar symptoms on lvs1015, even though it has the bulk of the same healthchecks plus all the live traffic, while lvs1016 has no live traffic to compete with.
Maybe we should try replacing transceivers on either end?