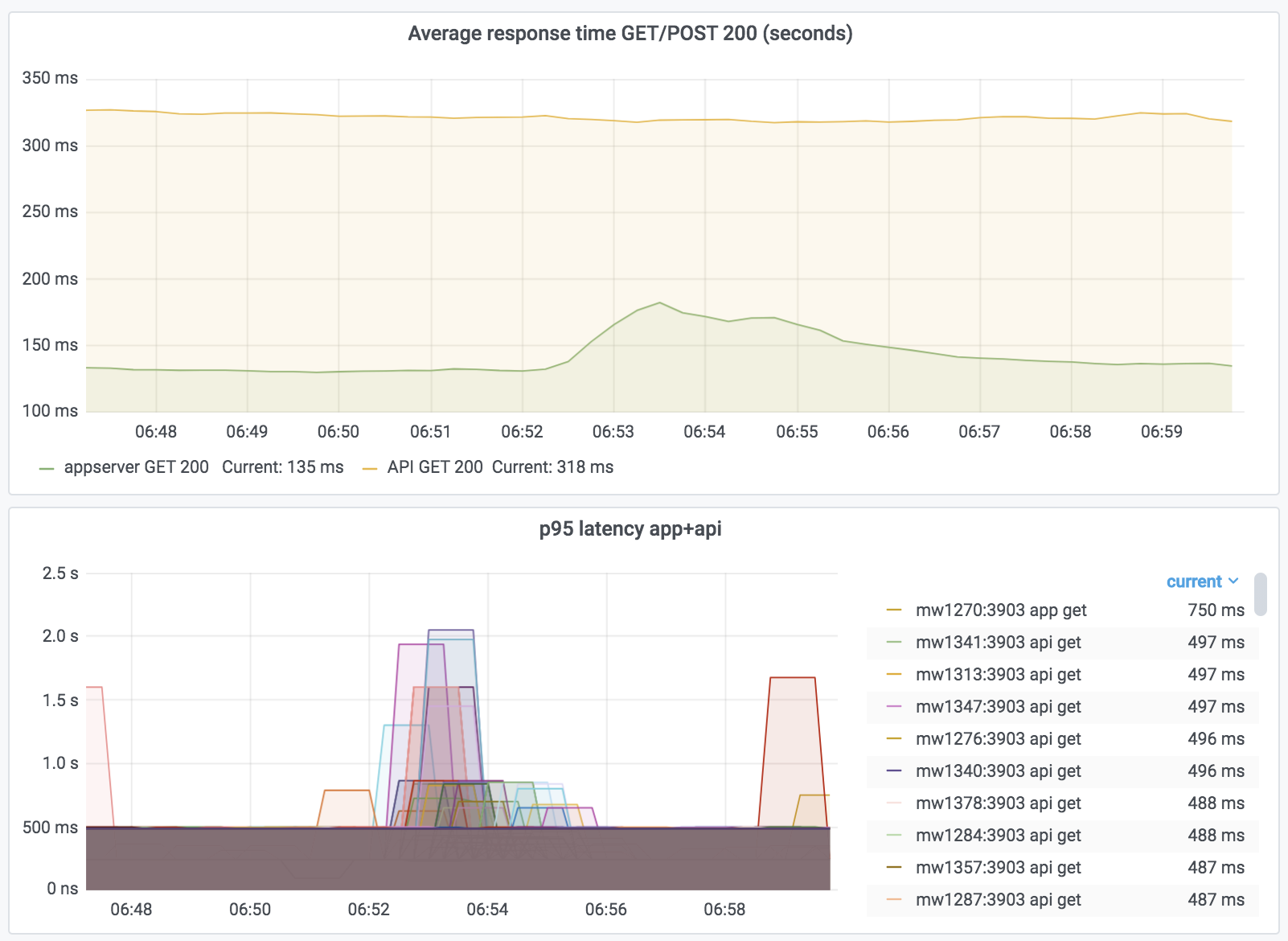
I'd like a feature flag that restarts php-fpm on every deployment (sync-world, sync-file, sync-wikiversions, etc). Turning on this feature would give us a better understanding of the time it takes to roll out MediaWiki if we do a restart (current estimates range from 5 minutes to 15 minutes).
This will help inform whether or not we can do a restart of php-fpm for *every* deployment to mitigate the possibility of opcache corruption.