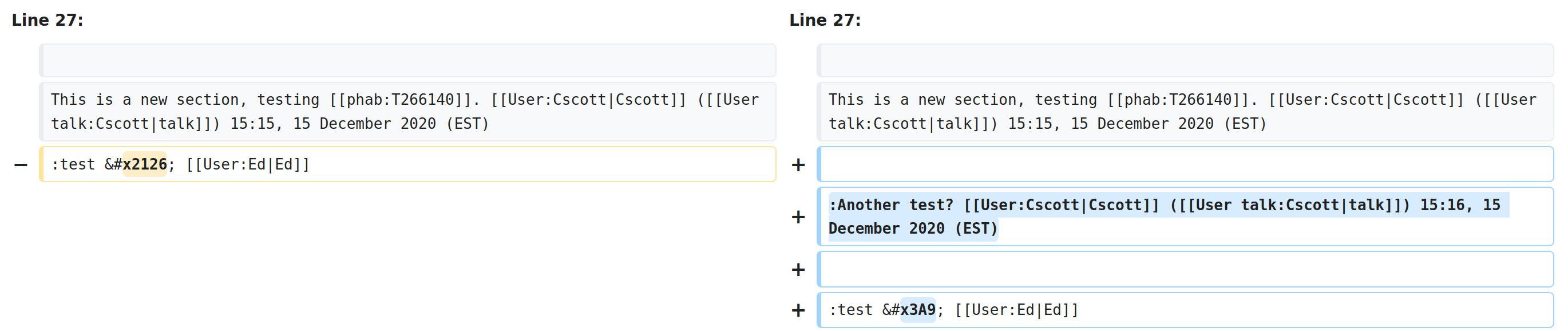
HTML entities were replaced by the Unicode characters in these edits made with DiscussionTools:
- https://he.wikipedia.org/?diff=29625893 – Ω
- https://sv.wikipedia.org/?diff=48324635 –  
In both diffs, there are other entities that were not affected (even on the same line of text).
More occurrences: