@Marostegui points out that after I ran the 08-update-tendril cookbook, the entries for pcNNNN hosts still needed to be updated by hand. They should be included as part of that automation.
In order to compute the Tendril update, the script loops over for section in mysql_legacy.CORE_SECTIONS, which doesn't include pc1, pc2, or pc3 -- but I don't think the right fix is to add them there. That would also mean we operate on them e.g. while setting the DBs read-only, and then read-write again. With nothing but optimism in my heart, I'm assigning this task over to the Touched It Last owner of the mysql_legacy module, to figure out what needs to happen here. (A reasonable answer is "we'll cover this with the new mysql module" -- this task is just to make sure the cookbook does the right thing, one way or the other.)
Note also that the Cumin query used by mysql_legacy in get_core_dbs() to identify the DB masters won't work without modification, since it starts with "A:db-core and..." and that alias doesn't include the pcNNNN hosts. Very reasonably, since parsercache isn't part of the core DBs.
And one last thing, in passing:
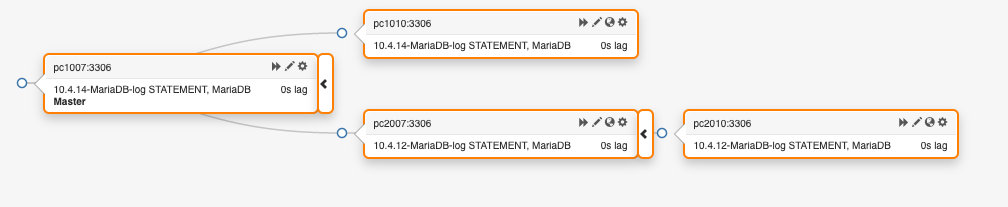
rzl@cumin1001:~$ sudo cumin 'A:eqiad and A:db-section-pc1 and A:db-role-master' 2 hosts will be targeted: pc[1007,1010].eqiad.wmnet
That seems like it ought to only be pc1007, right? Same in codfw.