Hi,
Really great extension, thank you very much for working on this.
I have a person template, identical to https://genealogy.toolforge.org/wiki/Template:Person (but translated to another language). And I have several people with parent relationships.
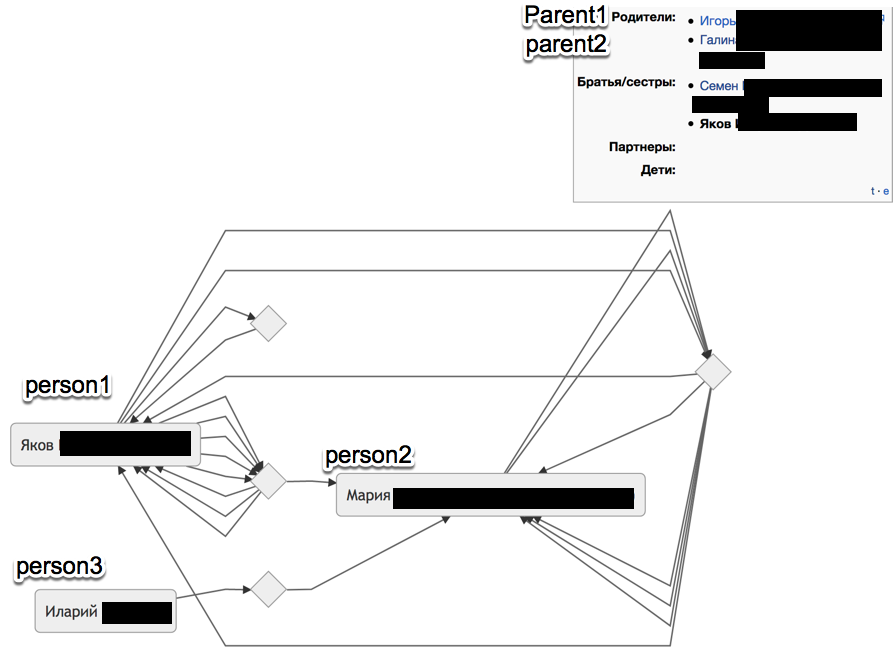
However, when I try to create a tree I get a bunch of empty nodes in it. I tried downgrading to 1.9.3, but it doesn't work with the mediawiki 1.35.0. I tried all releases of the extensions above 2.0.0 including dev-master, and get this weird graph.
The relevant part of the template looks like this:
!style="vertical-align:top; text-align:right"| Parents:
|{{#if: {{{parent1|}}} | {{#genealogy:parent | {{{parent1}}} }} }}<!--
-->{{#if: {{{parent2|}}} | <br />{{#genealogy:parent | {{{parent2}}} }} }}<!--
-->{{#if: {{{parent3|}}} | <br />{{#genealogy:parent | {{{parent3}}} }} }}And I try to make a tree using:
{{#genealogy:tree |ancestors=Person1 | format=mermaid}}But I do not see parent1 & parent2 in the tree. Instead some other "random" people. I do not understand where the loops and empty nodes come from.
Could it be that something is cached incorrectly? If not, are there any suggestions on how to fix this?
Thank you very much for your help.