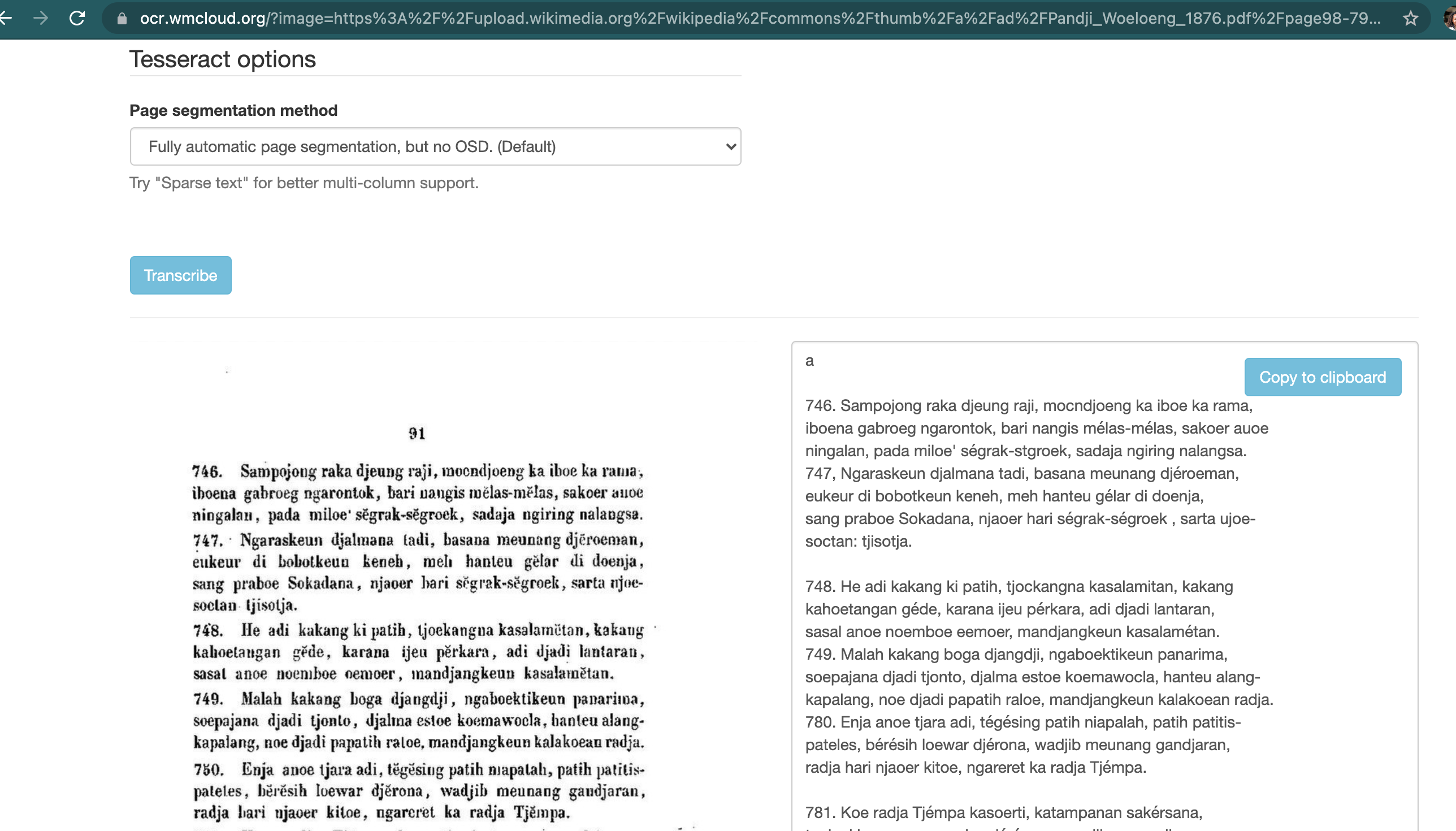
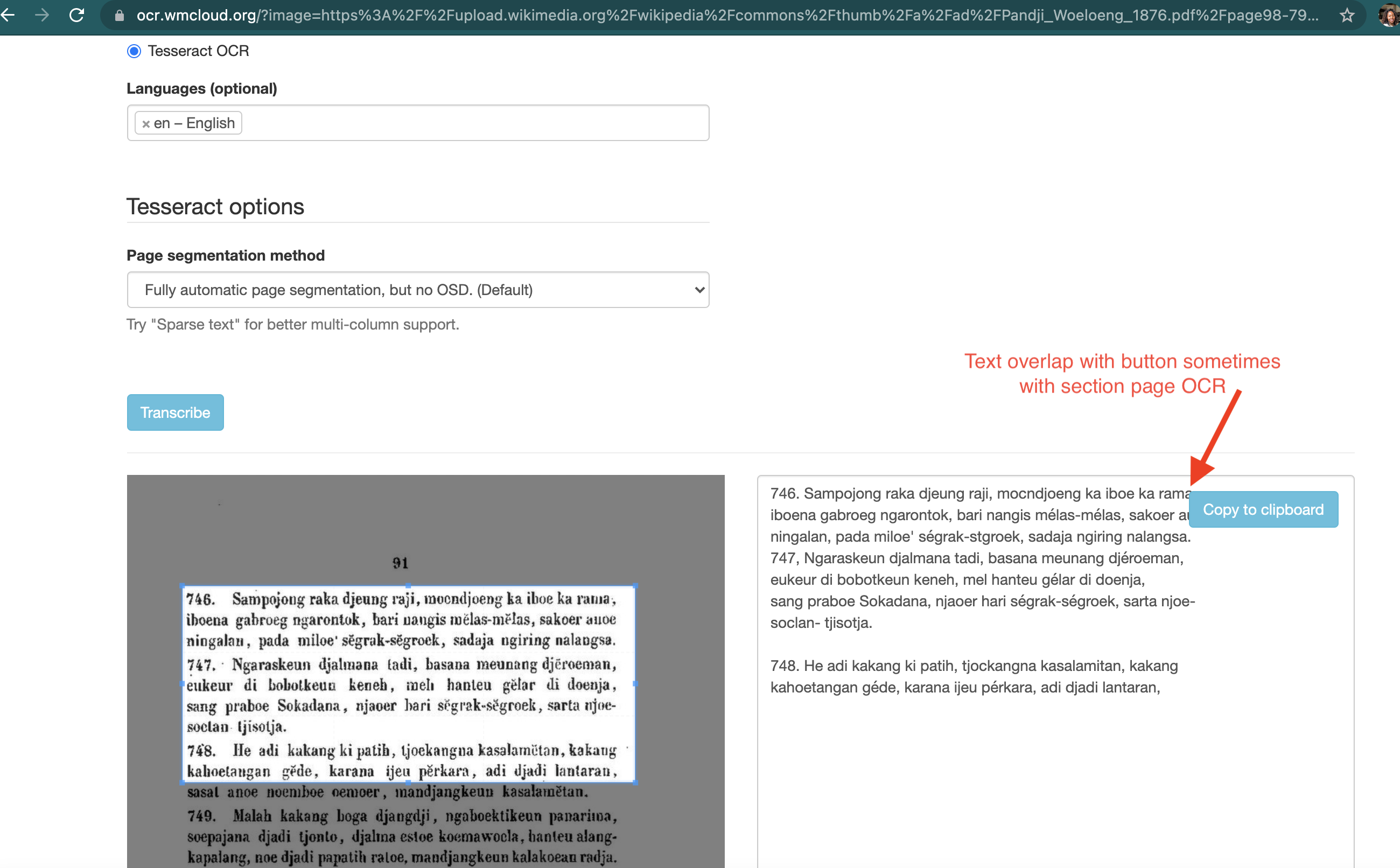
Many pages at Wikisource are extremely difficult to OCR because they flummox the segmenting engines of the OCR tools. For example:
While not as ideal as an AI-driven automagic system that just works, a decent fallback would be if the user could select a rectangular region to OCR. This at least would allow the proofreading to proceed in chunks.