Context
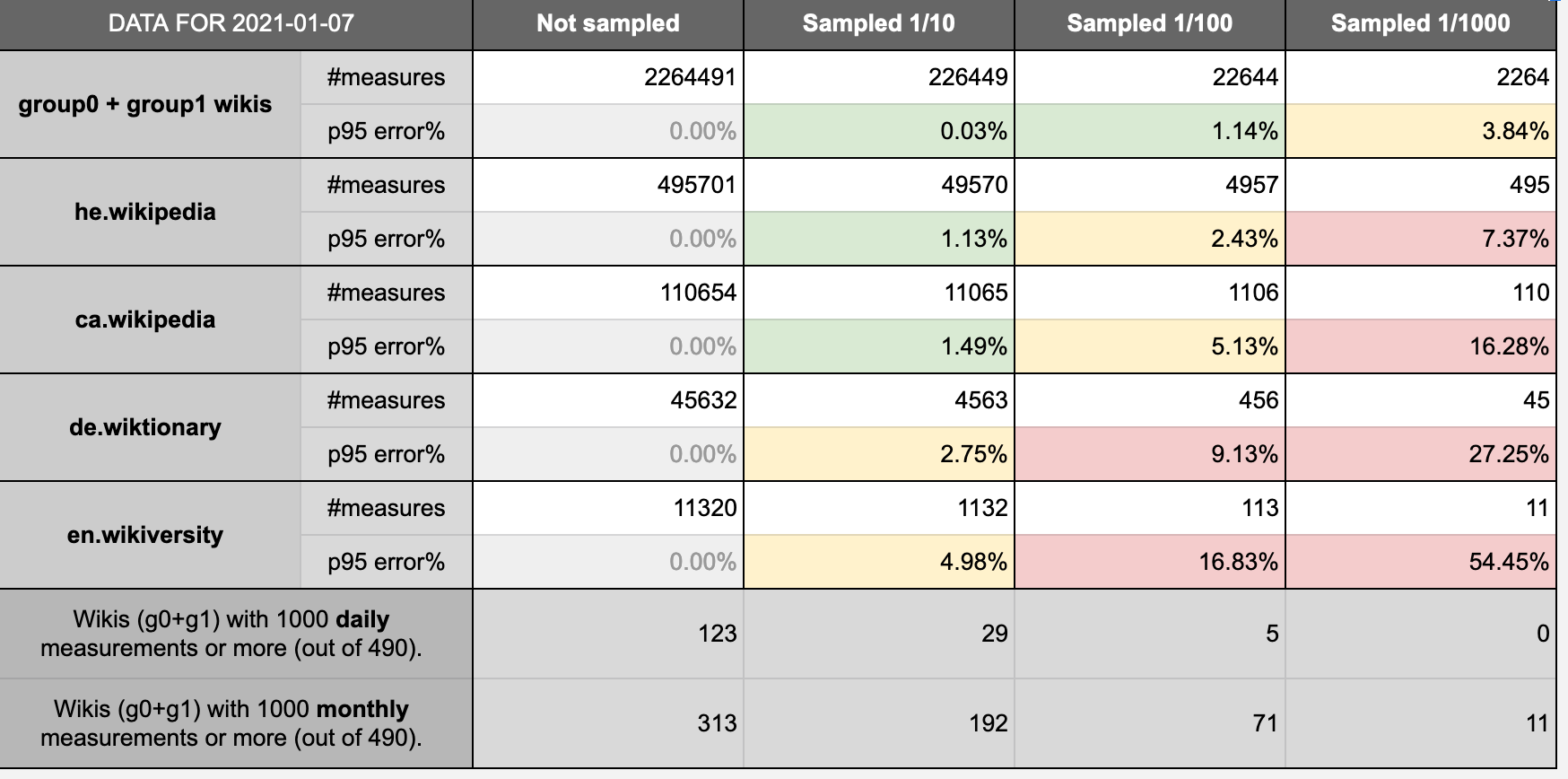
Once session_tick tracking is rolled out to all wikis, the dataset will quickly become too large if we don't institute sampling. Details are in Marcel's comment here: https://phabricator.wikimedia.org/T271455#6741794
As we sample, we need to consider how representative the data is for key breakdowns of the data (e.g. wiki, country, day). Is there a minimum threshold for sessions we should set? What do we know or can we learn about activity within key breakdowns to inform sampling strategy?
Decision
Initial rollout: 1/100 sampling; we will check the amount of events coming in. If the volume is within projected levels, we will move to 1/10 sampling.
If needed, we will adjust sampling on a per wiki basis once we have a better sense of event volume.
See comments T272069#6763490 and T272069#6801863 for additional details.