When paired or single brackets are mixed with paired brackets of a different type neither of them will be highlighted. See these examples and following screen cast.
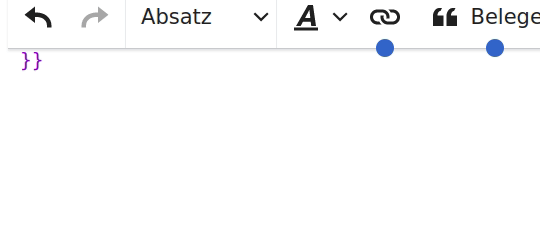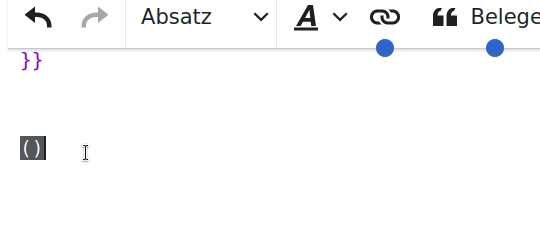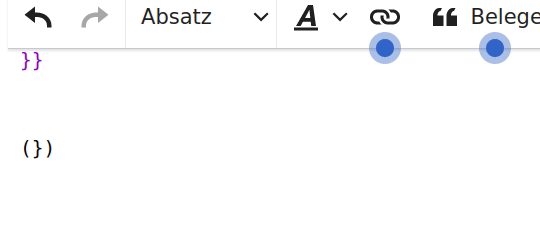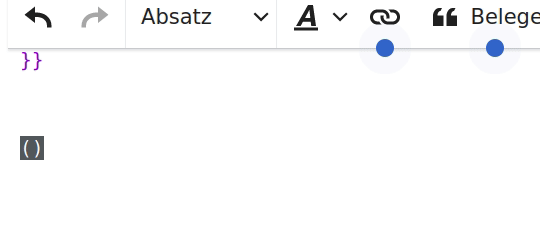
- {[{]
- }[{]
- ([)]
- ([)]
| WMDE-Fisch | |
| Jan 21 2021, 2:53 PM |
| F34009381: Peek 2021-01-20 12-31.gif | |
| Jan 21 2021, 2:53 PM |
When paired or single brackets are mixed with paired brackets of a different type neither of them will be highlighted. See these examples and following screen cast.
We kept wondering about situations like these, e.g. in T262255#6521041, and decided to disable the red error highlighting for non-matching brackets. This is part of the acceptance criteria in T261857. I can't find the ticket any more where this was originally discussed, sorry.
All the examples above are bad for the same reason HTML like <a><b>…</a></b> is bad. While browsers try to make sense of strange interlaced pairs like this, it's almost certainly a mistake and should be fixed.
I'm not sure what the expected behavior is. There are multiple ways to render these examples, and none of them is more "correct" than the other. It might just be a misunderstanding. See, the matchbracket algorithm does not simply search for a matching character, wherever it might find one. That's not really helpful when we talk about source code. The algorithm actually understands the structure of nested brackets. It finds the position where the matching bracket should be and only then checks if the character at this position is the expected one. Non-matching brackets are currently not highlighted via T261857, but could be highlighted in red.
@ECohen_WMDE, do you remember why we disabled the (red) highlighting of non-matching brackets, and where this decision is documented?
In the description of this ticket it says:
Scope
Excludes:
...
Unmatched bracket error highlighting
I left another comment in T272454#6795430 that might help to understand what's going on.
I can think of at least one real-world example where this is relevant: Templates like {{(}} actually exist and are used a lot, see https://en.wikipedia.org/wiki/Template:(.
There are also situations where a single ] or an extra bracket at the end of [[a]]] or {{a}}} isn't syntax but a literal bracket. But this should be rare.
A possible improvement is to change the behavior so that only [ and { (only these are syntax) look for a strict match, but ( (it's never syntax, at least not in wikitext) is much more relaxed and does not interfere with the other bracket types. This might help in situations like {{(}}. But it can't solve everything.
Personally I don't like the idea to "dumb down" the algorithm so that it ignores syntax and nesting structure.
A possible improvement is to change the behavior so that only [ and { (only these are syntax) look for a strict match, but ( (it's never syntax, at least not in wikitext) is much more relaxed and does not interfere with the other bracket types. This might help in situations like {{(}}. But it can't solve everything.
This makes sense to me, especially if we already know of a common situation. If we implemented this, ( ) would still be matched right? I think otherwise, @thiemowmde you're right that it shouldn't need to necessarily detect these interlaced matches.
do you remember why we disabled the (red) highlighting of non-matching brackets, and where this decision is documented?
I think this decision is documented in the [wish] doc, but I can summarize here. There were a couple reasons:
[…] If we implemented this, ( ) would still be matched right?
In theory, yes. Hard to tell how this would turn out. Depends a lot on the details. As of now, in an extreme example like {{(}} {{)}} nothing matches properly, because the different brackets interfere with each other. The main reason to design the highlighter like this is to make it focus on possible errors, and reliably mark them in red.
But we don't mark errors. We can relax the highlighter and make it focus on positive matches instead, without loosing functionality (reliable error detection).
As said, in wikitext [ and { are almost always syntax, but ( never is. Therefor I would love to implement #1, if possible. Should we create a ticket for this, or rephrase this one here accordingly?
Thanks for the breakdown @thiemowmde !
Based on your description option #2 makes a lot of sense to me, helping users find the actual missing bracket instead of breaking the matching for brackets which are in fact matched. Are there any downsides to that version that you're aware of?
Therefor I would love to implement #1, if possible. Should we create a ticket for this, or rephrase this one here accordingly?
I agree that it seems like a pretty straightforward way to improve the situation with one of these options. Otherwise it sounds like it could be relatively often that the bracket matching seems broken. Maybe it makes sense to update the ticket with one of the options and @Lena_WMDE can then prioritize and decide when/if to implement?
… but option 2 makes it harder to find a missing bracket. It's what I described as "dumb down" above. Let me try to illustrate:
[…] which are in fact matched.
That's the problem: there is no way to know which interpretation of the situation is the correct one. In [[Link}] the two outer […] belong together. This is the assumption the current algorithm makes. With option 2 both ◟[◞[Link}◟]◞ and [◟[◞Link}◟]◞ are highlighted as if everything is ok, even if one of the two is wrong. Which one? We can't know.
The argument to put []{} in one group and () in another is not only because one is syntax and the other is not. []{} are pretty much always used as pairs. They form a syntax tree, and this is what the current algorithm respects. The chance that a stray [ is an error is extremely high. On the other hand ( is not necessarily an error, as seen in {{(}}.
Conclusion from discussions during story time are:
Since [ and { are almost always syntax, but ( never is*, we will implement option 1: two groups of brackets, [ ] { } and (), that work independent from each other. This will likely solve some of the most common cases without changing the logic significantly.
*CodeEditor takes over for code content, e.g. Javascript and Lua, where round brackets are syntax.