[03:23] < sDrewth> glitch or maintenance? [03:59] < sDrewth> people aware that the cloud servers are killing connections? [03:59] < sDrewth> lost my ssh at the same time that the bots connected to irc all died [04:00] < sDrewth> happened earlier then recovered [04:02] < sDrewth> recovery is very spotty [04:02] < sDrewth> !help ^^^ [04:07] <Guest71293> [telegram] <bd808> sDrewth: I’m not sure I understand your report. Can you elaborate? [04:07] < sDrewth> irc connections from cloud to freenode died [04:08] < sDrewth> ssh connections died [04:09] < sDrewth> sorry bd808 The servers lost connections, ssh and irc to freenode [04:09] <Guest71293> [telegram] <bd808> And “recovery is very spotty”? [04:09] < sDrewth> bdo808 some recover, some don't, some are flaky [04:10] < sDrewth> bd808 some recover, some don't, some are flaky; having coibot up and down in IRC, though it is often cantakerous [04:13] < sDrewth> bd808 3.16 and 3.58 UTC particular times of ugh.
Description
Description
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Open | None | T268335 cloud: neutron l3 agent: improve failover handling | |||
| Resolved | aborrero | T272797 Report of network interruptions for Toolforge on 2021-01-24 |
Event Timeline
Comment Actions
I couldn't find any alert emails around the times reported (2021-01-24T03:16, 2021-01-24T03:58). Anecdotally my Tool-bridgebot had lost it's Freenode nick which is sometimes a sign that it had reconnected following a connection loss.
Comment Actions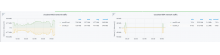
There was apparently a failover going on between the 2 cloudnet servers at that time:

The 2 spikes on the right graph are the 2 failovers that happened. All connections were cut because T268335: cloud: neutron l3 agent: improve failover handling is not quite finished yet and is proving to be more challenging than initially expected.
This theory can be confirmed in cloudnet1003 logs:
aborrero@cloudnet1003:~ $ sudo journalctl -u neutron-l3-agent | grep "Jan 24 03" Jan 24 03:13:20 cloudnet1003 Keepalived_vrrp[43319]: (VR_1) Received advert from 169.254.192.6 with lower priority 50, ours 50, forcing new election Jan 24 03:13:22 cloudnet1003 Keepalived_vrrp[43319]: (VR_1) Received advert from 169.254.192.6 with lower priority 50, ours 50, forcing new election Jan 24 03:13:24 cloudnet1003 Keepalived_vrrp[43319]: (VR_1) Received advert from 169.254.192.6 with lower priority 50, ours 50, forcing new election [...] Jan 24 03:57:34 cloudnet1003 Keepalived_vrrp[43319]: (VR_1) Received advert from 169.254.192.6 with lower priority 50, ours 50, forcing new election Jan 24 03:57:36 cloudnet1003 Keepalived_vrrp[43319]: (VR_1) Received advert from 169.254.192.6 with lower priority 50, ours 50, forcing new election Jan 24 03:57:38 cloudnet1003 Keepalived_vrrp[43319]: (VR_1) Received advert from 169.254.192.6 with lower priority 50, ours 50, forcing new election [...]
Unfortunately we are suffering a hardware issue on cloudnet1004, which makes it very unreliable. The network flapping could be very well this hardware issue, see T271058: cloudnet1004/cloudnet1003: network hiccups because broadcom driver/firmware problem.
Additionally, I see the autogenerated keepalived config by neutron contains the same state and priority for both routers, which I don't think are the right values to prevent this kind of sudden-primary-renegotiations:
aborrero@cloudnet1003:~$ cat /var/lib/neutron/ha_confs/d93771ba-2711-4f88-804a-8df6fd03978a/keepalived.conf vrrp_instance VR_1 { state BACKUP interface ha-37a86ebc-17 virtual_router_id 1 priority 50 [..] aborrero@cloudnet1004:~$ cat /var/lib/neutron/ha_confs/d93771ba-2711-4f88-804a-8df6fd03978a/keepalived.conf [..] vrrp_instance VR_1 { state BACKUP interface ha-d8c86248-12 virtual_router_id 1 priority 50 [..]
Thanks for reporting :-) As you can see, there are several moving parts here, none of them trivial to solve.