Wikimedia uses over 200 MariaDB instances to store content and metadata for Wikipedia and other free knowledge projects. It also uses Bacula, mydumper and xtrabackup to perform backups if its hundreds of terabytes of data in its infrastructure. While standard open source tools for both monitoring and automation are used when possible, there are some tasks that require custom development. There are several options for a project to choose here, of which you should do your own research about which is the right one (only one) to complete within the 175 hours of work:
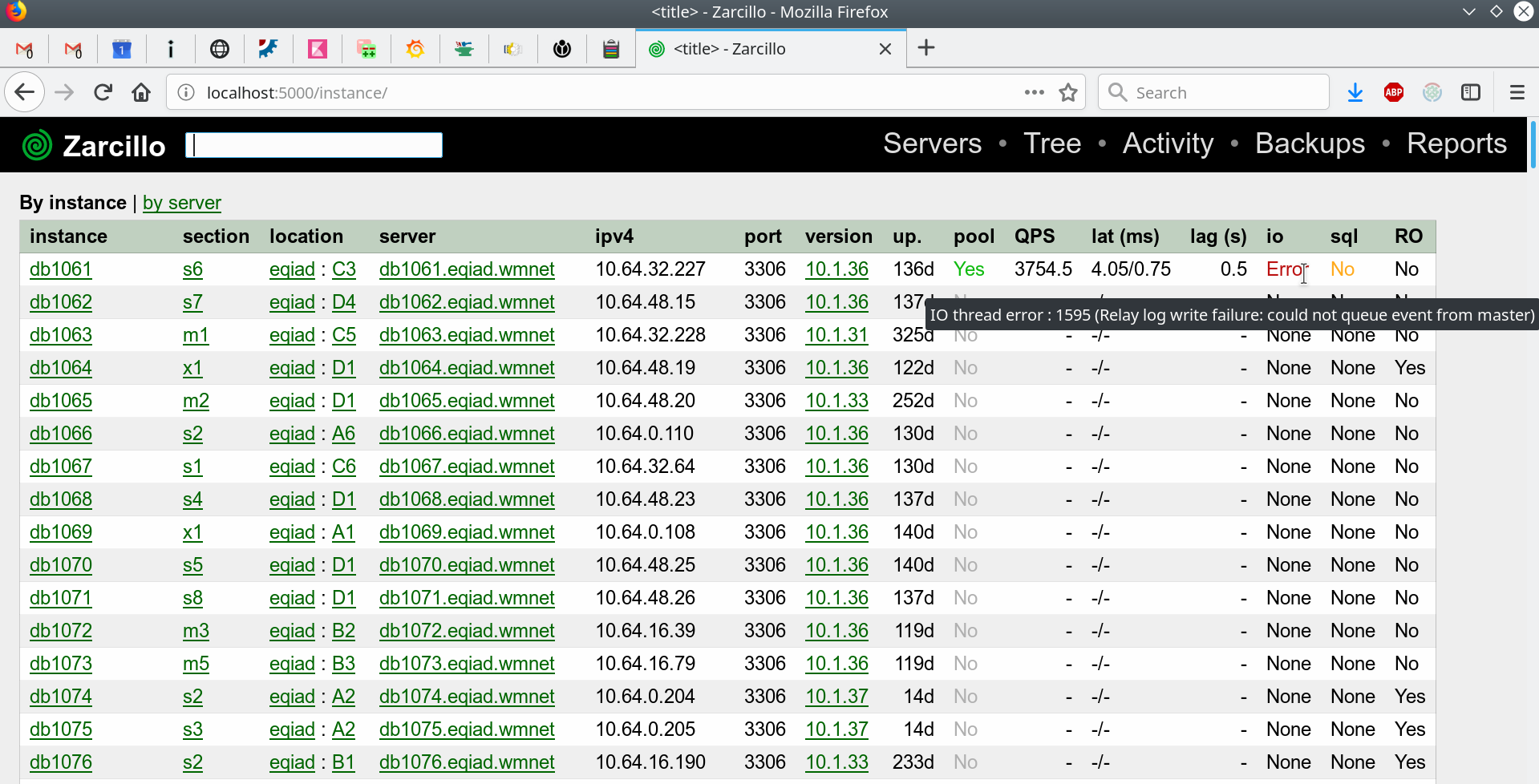
MariaDB instances inventory (zarcillo web interface)
There is an existing database "zarcillo" that inventories the existing mariadb instances. However, edits and check to it are using SQL directly. The aim is to change that into a web-based CRUD to inventory mariadb instances and its basic properties (servers, sections, etc.) and also develop a web api for easy querying from external services.
Mockup:
- Relevant script using the zarcillo db to generate prometheus targets
Database object inventory
We would like to keep track of existing objects (databases, tables, columns, indexes) in our over 1000 databases throughout over 200 mariadb instances, and then detect (alert) on differences with the latest version of the schema deployed, in order to:
- Facilitate and schedule schema changes
- Detect backups errors (e.g. missing objects on backup)
- Provision more instances/more disks due to growth
For that, we need to 1) scrape information keep a metadata database up to data with reality 2) provide reports of interest (number of objects, size) 3) regularly check for inconsistencies over the same objects on different servers (e.g. a column has a different type on 2 different servers).
There is already some shy initiatives working on this direction:
- Zarcillo has a tables database, but it is not used a lot
- Backups metadata database has an objects table, but it is also not in use
- Ladsgroup has developed some scripts to compare production and tables.sql/tables.json (current mediawiki schema)
We would like to merge all those efforts into a canonical metadata solution to monitor db objects.
Database backup inventory improvements
Database backups provide a database (mariadb) structured log of backup output, including timing, success, and backed up objects, so we can track that the dozens of backups produced everyday finish correctly. While there is a basic check to ensure backups are fresh, we would like to expand the usefulness of this database by providing more fine grained info:
- A postprocesed information of the size of each backup object (filling in the backup_objects table)
- A web dashboard to the metadata, that easily reports the status of backups or its errors
- A web dashboard that tracks the status of ongoing backups (next scheduled run, running, postprocessing, finishing ETA, etc.)
- Relevant repository: operations/software/wmfbackups
Improve WMF Bacula monitoring
While there is already a basic check_bacula.py script, that makes sure backups are being correctly taken, as well as exporting to prometheus the necessary metrics, and basic cli information, we would like to expand existing functionality.
Some of the ways in which the script could be complemented would be:
- Provide additional metrics regarding retention time, media storage, available disk space, etc.
- Provide additional information on command line that makes simpler to query backup status by engineers
- Improve the Grafana bacula dashboard or create additional dashboards with those more detailed statistics
- If Grafana is not the right technology for that, improve the visibility of bacula statistics by providing a nice web dashboard summarizing the status of bacula, that helps engineers understand backup status
- Relevant repository: WMF Bacula module on puppet and Bacula source code
MySQL account metadata inventory
Currently, most of account management for MySQL happens on Puppet configuration management tool. However, puppet may be far from ideal for deployment of certain changes that have to be done synchronously throughout the cluster, as well as monitoring anomalies.
That is why we want to develop a tool that help track and monitor account configuration among different distributed instances. Such tool should be able to:
- Connect and read the account information as well as permissions (grants) for each instances
- Track what should be the account information for a given instances (including different roles, usages and peculiarities of different group of servers)
- Alert on anomalies found, such as accounts or grants missing from a Mariadb server, passwordless accounts or grants too open for a given account.
This will require maintaining a database inventory of accounts and instances, and a way to emit alerts (web interface or through a provided monitoring tool api).
- Relevant script: Reporting users with no password
Suggested microtasks
- T268258: transfer.py argument parsing exception
- T277160: Make recover-dump show the time taken
- T277162: recover-mariadb should use logging (logger) to indicate actions taken
- T253959: Check we are preparing (xtrabackup --prepare) with the same package version as the server version of which the backup was taken