Follows-up from T269593: ParserCache should use CachedBagOStuff
Description
Description
Details
Details
| Subject | Repo | Branch | Lines +/- | |
|---|---|---|---|---|
| ParserCache: only use in-process caching for metadata | mediawiki/core | master | +53 -21 |
Related Objects
Related Objects
- Mentioned Here
- T269593: ParserCache should use CachedBagOStuff
Event Timeline
Comment Actions
The results are in, and quite volumous in Grafana: Production logging:
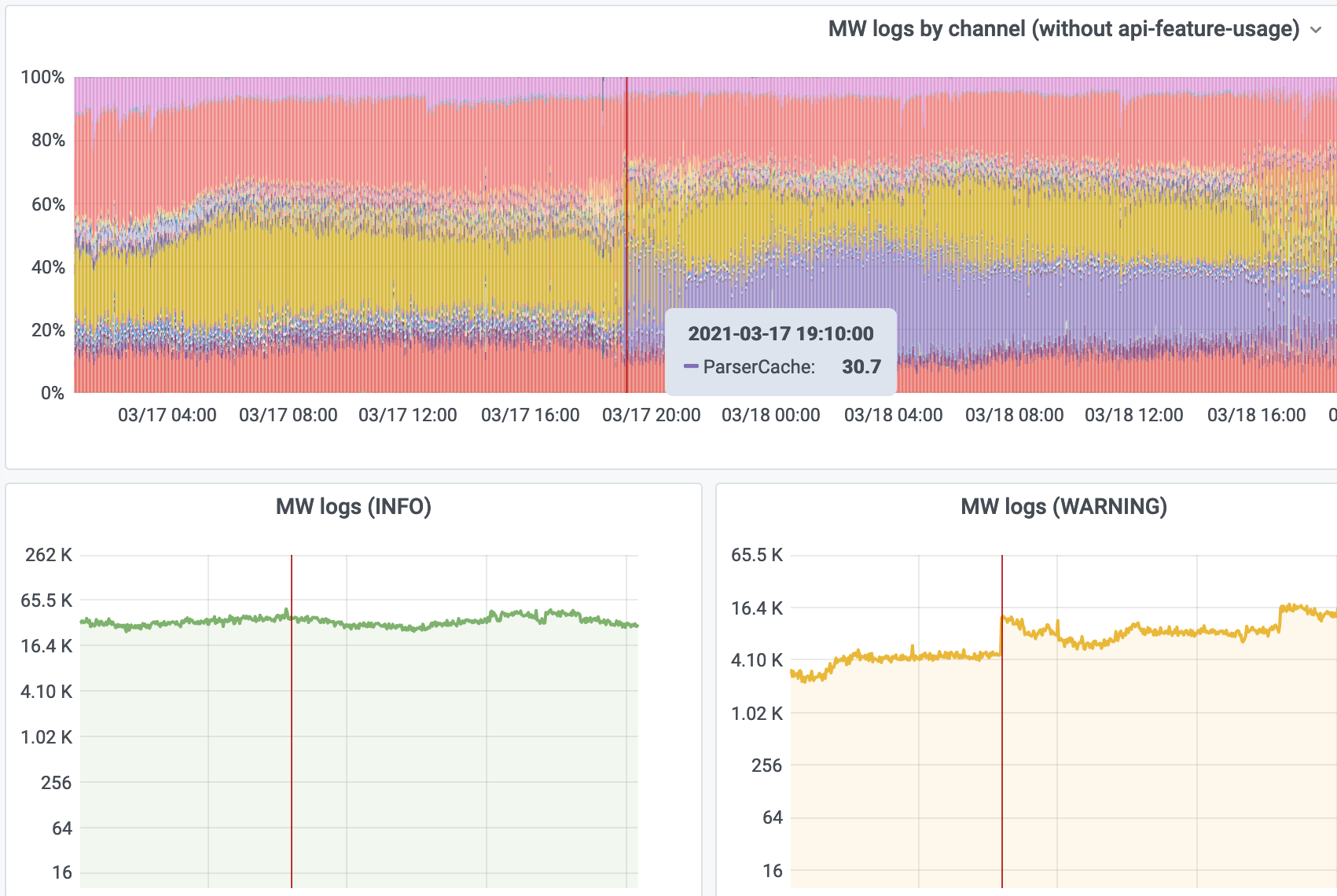
You can dig in on Logstash: mediawiki where there's 300,000 entries per hour.
The vast majority (295,000/hour) are idoptions keys, and happen predominently on regular page views, across all wikis:
Duplicate get(): "<some wiki>:pcache:idoptions:<some id>" fetched 2 times"
The second most common (2,500/hour) are idhash keys with canonical and responsiveimages=0 set.
Duplicate get(): "<some wiki>:pcache:idhash:<some id>-0!canonical!<sometimes a language>!responsiveimages=0" fetched 2 times
These seem to mostly happen on User_talk and File_talk pages for some reason. For example:
Duplicate get(): "commonswiki:pcache:idhash:41461911-0!canonical!responsiveimages=0" fetched 2 times
url: https://commons.wikimedia.org/wiki/File_talk:Cruiser_Mk2.jpg
(page ID 41461911)
Comment Actions
I think I know the reason for idoptions.
During a normal page view, we reuse the cached parse metadata to construct the PoolCounter work key. That's needed cause we want the PoolCounter work key to differentiate by parser options just like ParserCache does, and the used options are stored in parser cache.
Then, when we actually do the pool work, it looks up the cache entry in the parser cache - that internally looks up metadata first.
So we basically always fetch from the metadata twice.
Comment Actions
IIRC, by extension, this also explains why the parser output itself (idhash keys) also need to be fetched twice. A ParserCache miss will trigger a PoolCounter-protected parse, and once one of the threads has completed the work, waiting threads will re-fetch the parser output from the cache via getCachedWork(), which should, if everything went well, now be a hit rather than a miss.
Comment Actions
It looks like CachedBagOStuff caches a cache-miss. Which, if I understand correctly, seems like it would break this PoolCounter logic as it would mean we can no longer do the "wait for lock and then fetch again" thing that this is supposed to do, right?
And this aspect of CachedBagOStuff appears to be intentional, because:
- BagOStuff uses false to mean absence. In general, consumers use null, 0, or [] etc if they need to persist a bottom value.
- CachedBagOStuff::get unconditionally calls Hash->set() after calling Backend->get(), so it will be calling set() for false.
- CachedBagOStuff::get explicitly checks hashKey() and makes sure to short-circut and not check with the backend a second time,
Can you confirm that PoolWork is still working correctly for this use case?
The metadata seems like we can avoid a second fetch since the same business logic is responsible for both fetches and should be able to hold on to it and pass it in or something like that. Or alternatively, maybe the PoolWork side of things doesn't need to know about this at all and can perhaps let the ParserCache side of things worry about it e.g. by acknowleding the use case of "I call for this and if you tell me it's not there, trust that I will ask for it again". Or maybe we can make sure to use the wrapped one only for parser options and not the rest, if that would work correctly still as a way to declaratively remember it in the common case without any ad-hoc logic. But it might be easier to just enhance the code that performs the options fetch to have its own HashBag(maxKeys:2) object to consult.
Comment Actions
Change 677299 had a related patch set uploaded (by Ppchelko; author: Ppchelko):
[mediawiki/core@master] ParserCache: only use in-process caching for metadata
Comment Actions
@Krinkle you're totally right, caching negatives is wrong in this case. The above patch implements in-process caching for metadata only.
Comment Actions
Change 677299 merged by jenkins-bot:
[mediawiki/core@master] ParserCache: only use in-process caching for metadata