I've been looking into the high First Visual change we sometimes have on both Kobiton and Bitbar. This is an example of FirstVisualChange on Obama, looking at the max value:

They all have a really long download time of the HTML:
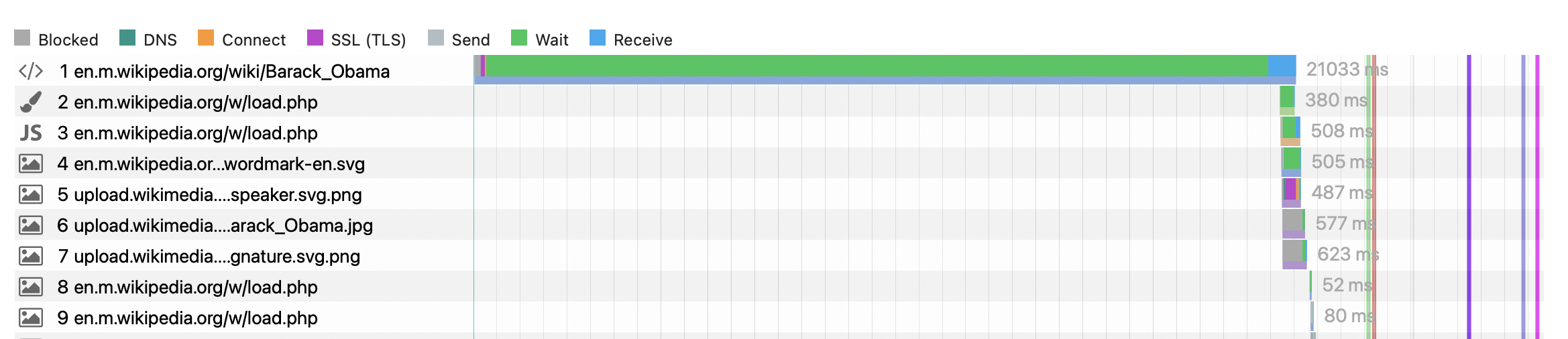
All except the first one has one of the following cache headers:
cp1089 miss, cp1075 miss x-cache-status:miss
x-cachecp1089 hit, cp1075 miss x-cache-status: hit-local
x-cachecp1079 miss, cp1075 pass x-cache-status:pass
@Gilles I understand pass/miss pass on it to the backend but what do hit-local means?
Many of them (but not all) is the first hit, so a pre-cache request would solve that for the synthetic testing. Let me dig into the rest of the URLs we test and I wonder how often this happens for real users too?