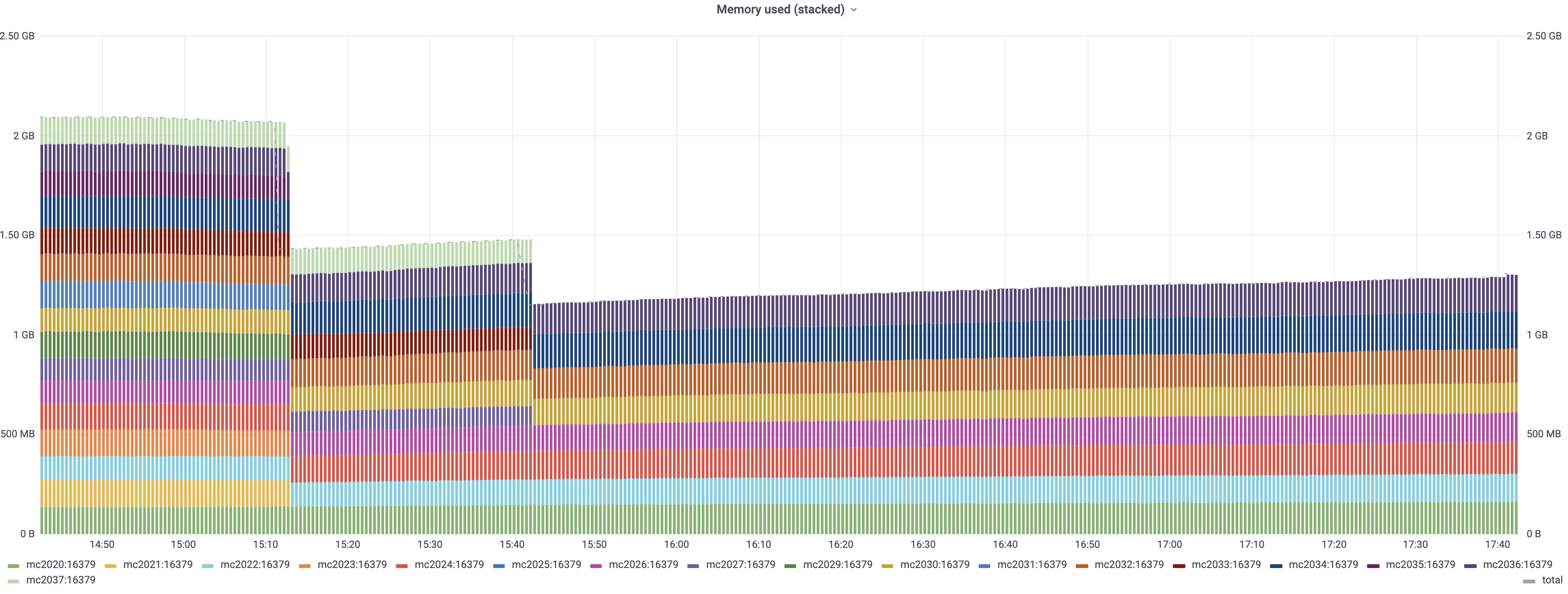
The redis_sessions cluster currently hosts ~2.5GB of data, sharded across 18 servers, per DC which is an overkill. Let's reduce the number of shards to a more sensible number, eg 8.
Requirements:
- 2 shards per row (if possible)
- mediawiki rdb servers in InitialiseSettings.php
- mc1030 C4
- mc1022 A6
- mc1034 D4
- mc2030 C5
- mc2022 A8
- mc2034 D4
How?
We will remove one server pair (eqiad-codfw) first, and then the rest of them in one go.
Notes
The following memcached servers should be reimaged:
- mc2019
- mc2021
- mc2023
- mc2025
- mc2027
- mc2037
- mc2029
- mc2031
- mc2033
- mc2035
- mc1037
- mc1038