In bnwiki, some articles are being suggested after their first appearance.
For example:
(i) In ফ্রেড বারাট article, the word "ইনিংস" is suggested at its 4th appearance
(ii) In সৌদিয়া article, the word "মধ্যপ্রাচ্য" is suggested at its 2nd appearance
(iii) In স্ট্যাচু অব লিবার্টি article, the word "তামা" is suggested at its 2nd appearance
(iv) In সুপারহিরো article, the word "কমিক বই" is suggested at its 3rd appearance
(v) In অ্যান্থনি বেবিংটন article, the word "যুক্তরাজ্য" is suggested at its 2nd appearance
Screenshots of the first two examples (I marked the first appearances in red):
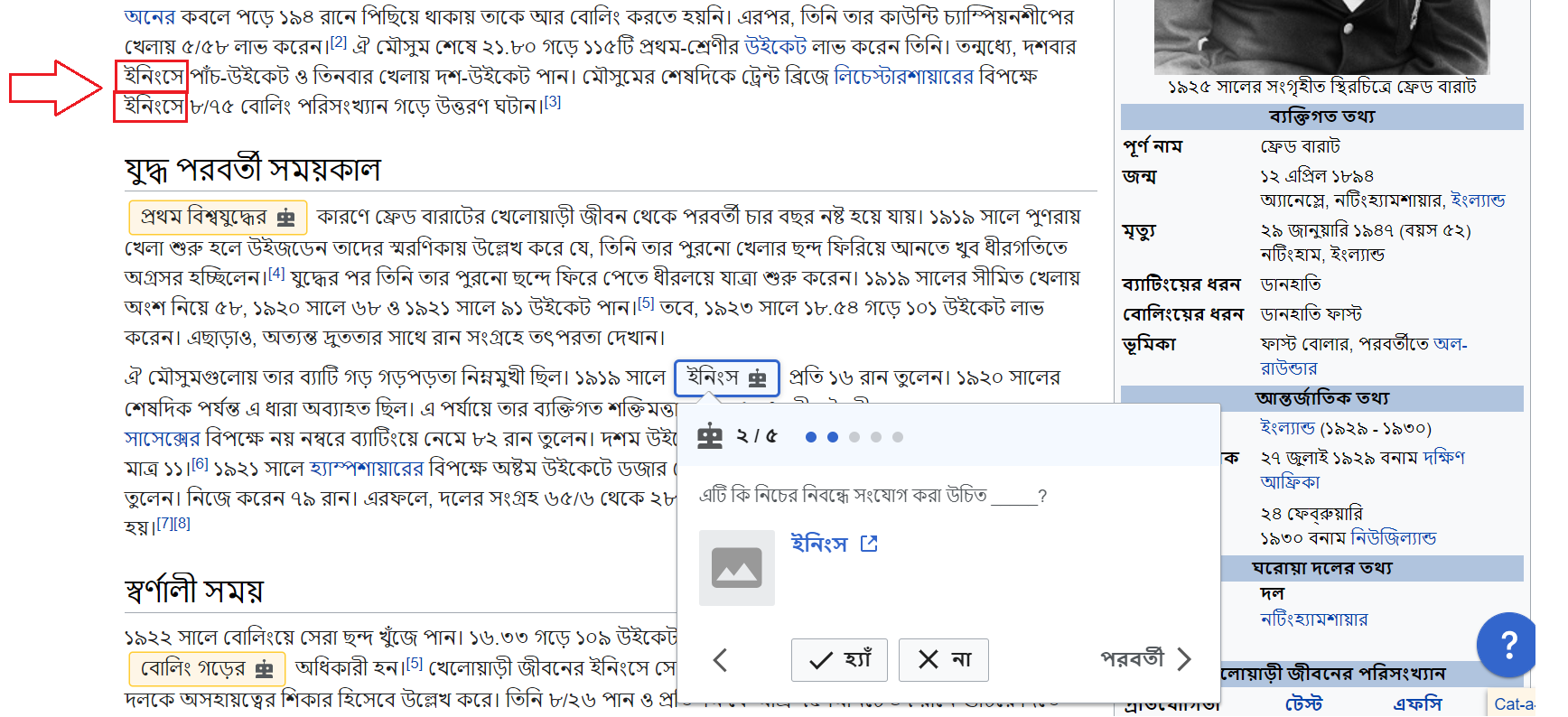
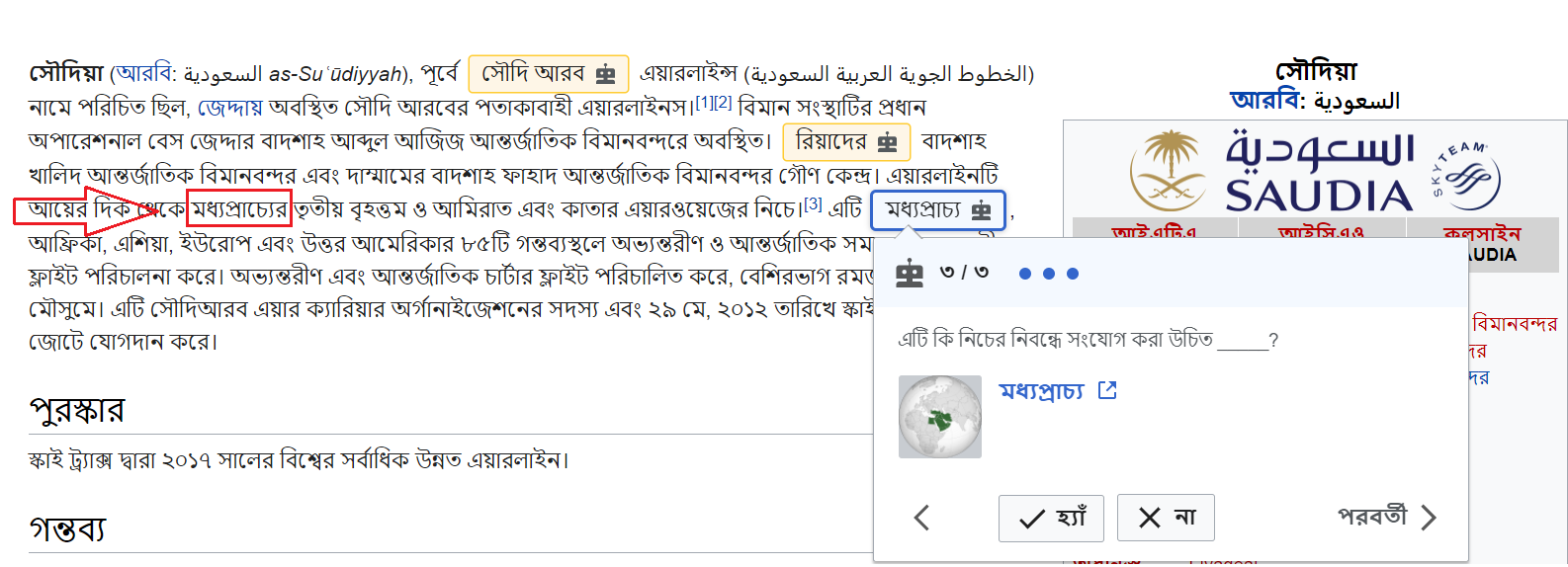
An observation: in each of the cases, the words of the article contain some additional alphabets in those first appearances. In the case of example (iii), the first appearance was "তামার", and the article "তামা" was not suggested then.