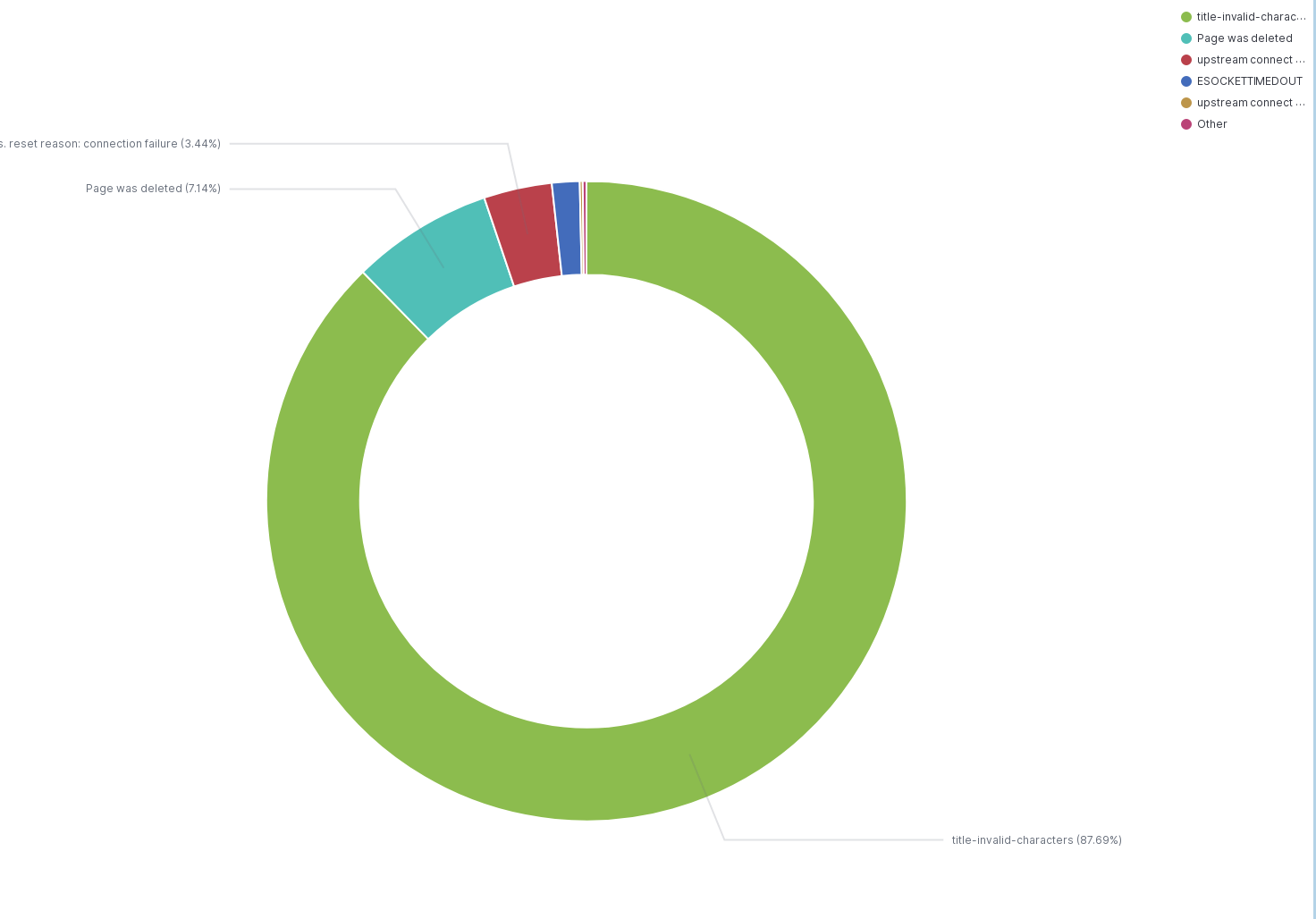
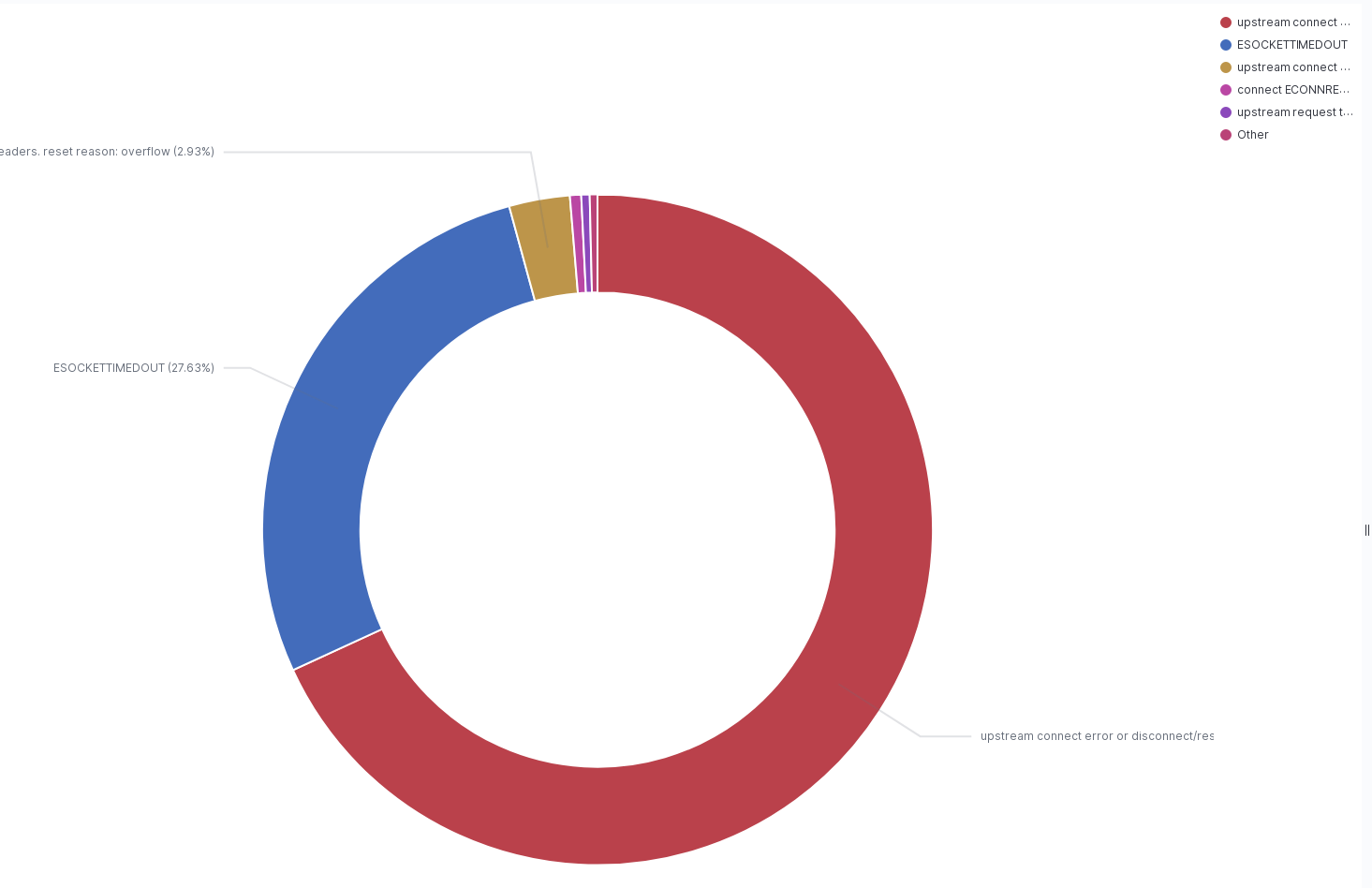
Icinga is reporting failures like:
19:32 +<icinga-wm> PROBLEM - wikifeeds codfw on wikifeeds.svc.codfw.wmnet is CRITICAL: /{domain}/v1/page/featured/{year}/{month}/{day}
(retrieve title of the featured article for April 29, 2016) is CRITICAL: Test retrieve title of the featured article for
April 29, 2016 returned the unexpected status 504 (expecting: 200):
/{domain}/v1/media/image/featured/{year}/{month}/{day} (retrieve featured image data for April 29, 2016) is CRITICAL:
Test retrieve featu
19:32 +<icinga-wm> e data for April 29, 2016 returned the unexpected status 504 (expecting: 200):
/{domain}/v1/page/most-read/{year}/{month}/{day} (retrieve the most-read articles for January 1, 2016 (with
aggregated=true)) is CRITICAL: Test retrieve the most-read articles for January 1, 2016 (with aggregated=true) returned
the unexpected status 504 (expecting: 200) https://wikitech.wikimedia.org/wiki/WikifeedsI spent some time with @hnowlan trying to debug but we didn't find a root cause. Here's what we discovered:
- wikifeeds pods in codfw are in evicted state (not all of them), tracked in T290444. This has been happening for a while, and it doesn't match afaics with the alerts.
- the wikifeeds tls-proxy container for several pods show a lot of HTTP 503s for various Restbase endpoints.
- the wikifeeds dashboard doesn't look like anything is happening, and stuff like https://en.wikipedia.org/api/rest_v1/#/Feed appear to work.
- from the dashboard it seems that the wikifeeds pods are throttled (CPU). The throttling has been happening for a while, it doesn't match with the alert.
- Hugh was able to find a way to repro the 50x errors, but only intermittently:
elukey@deploy2002:~$ curl https://wikifeeds.discovery.wmnet:4101/en.wikipedia.org/v1/page/random/title
{"status":503,"type":"internal_error","detail":"upstream connect error or disconnect/reset before headers. reset reason: connection failure","method":"GET","uri":"/en.wikipedia.org/v1/page/random/title"}elukey@deploy2002Last deployment-chart change for wikifeeds: https://gerrit.wikimedia.org/r/c/operations/deployment-charts/+/715452
Here is a sample error in the Restbase Logstash showing the UA being WikipediaApp (seeing the error for both Android and iOS)