I'm establishing this ticket as a place to centralize discussion and updates on creating prototypes for model cards, datasheets, etc.
Development is happening on gitlab in the algo-accountability repo: https://gitlab.wikimedia.org/htriedman/algo-accountability. In addition, we're meeting on a weekly basis (Thursdays 5:45-6:30 PM UTC) to share updates on the project — you can comment on this phab ticket if you'd like an invitation to that meeting.
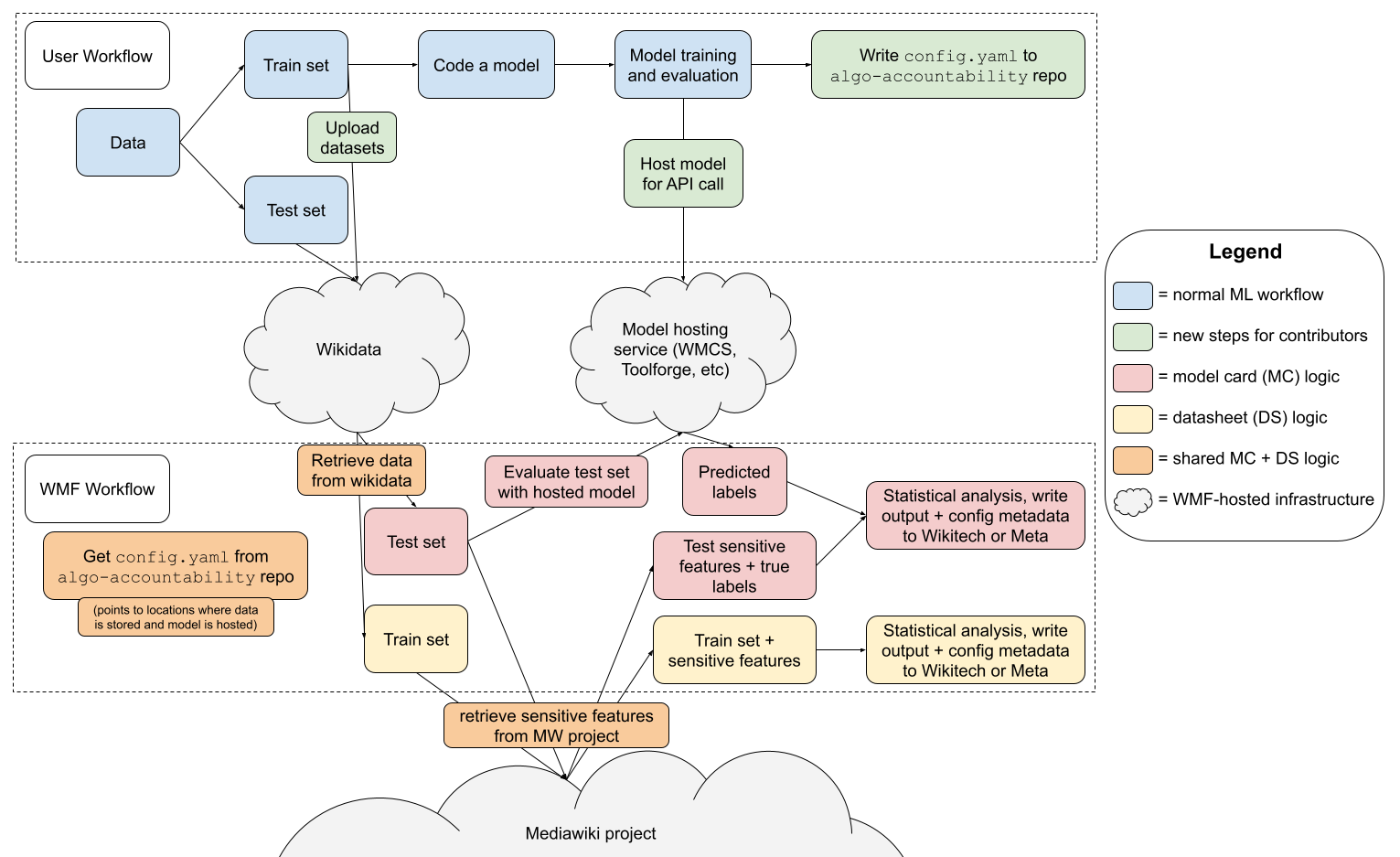
At the moment, we're focused on getting to a baseline prototype for on-wiki model cards using ORES models. The focus is on minimizing technical debt, providing clear information for the community to evaluate models on, and providing a relatively simple UX for contributors (internal or external) to submit their models.