NOTE: a full validation experience will not be part of Iteration 1. This is for a future iteration. For the minimal version, see T293161: Add an image: minimal caption validation.
Placeholder task for validation rules on the caption entered by the user. These rules may include:
- Minimum and maximum length.
- Not allowing the filename to be included.
- Not allowing same caption as previous image done by the user.
- Checking that it is in the content language for the article.
This task will also include the user experience for displaying the warning message.
Mockup as of 2021-10-08:
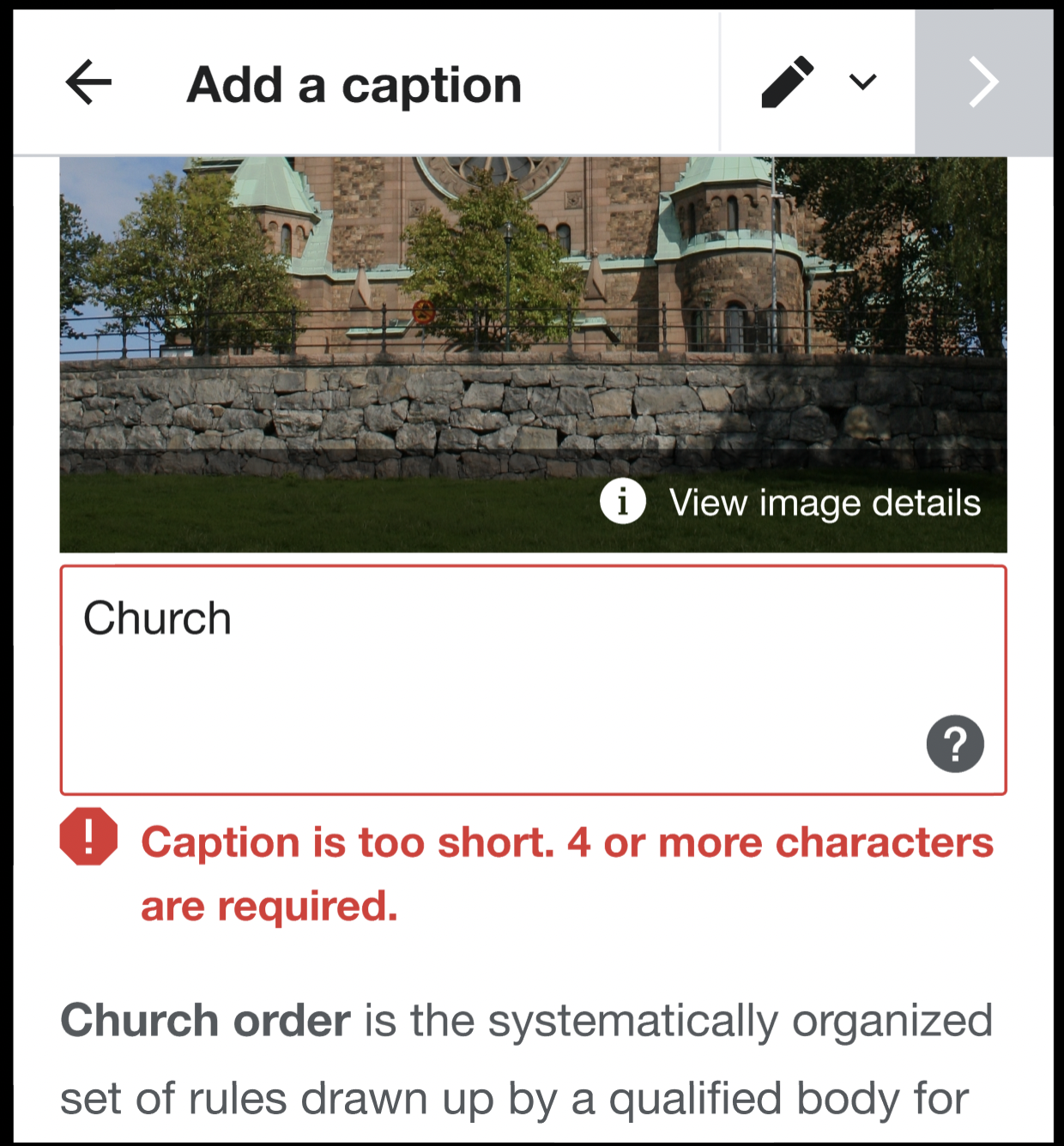
Figma: https://www.figma.com/file/ULhJr1isDstRbGE5vjYDsr/Add-images-structured-task?node-id=3050%3A9628