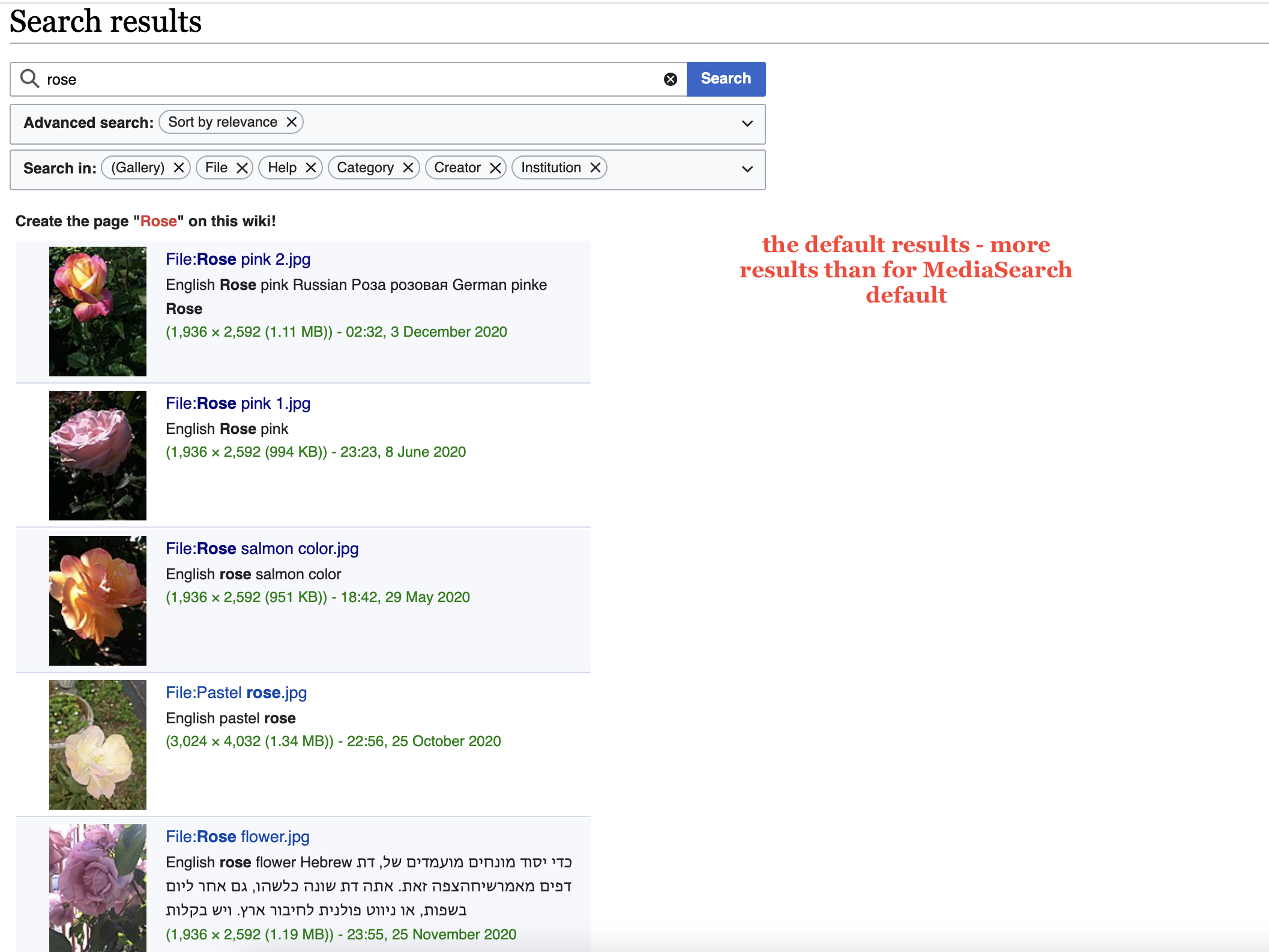
MediaSearch returns fewer results from the File namespace than Special:Search does
Note: Special:Search with only the File namespace selected triggers the MediaSearch backend, so in order to see this you'll have to select the File namespace and at least one other
Example from production:
- MediaSearch for cat that plays returns 398 results
- Special:Search for cat that plays returns 141710 results (searching File and Institution namespaces - searching Institution on its own returns zero results)
Example from betalabs:
- On betalabs in a private browser window without logging in, type in the search text field a search word : rose (https://commons.wikimedia.beta.wmflabs.org/w/index.php?search=rose&title=Special:MediaSearch&type=image). Only two results will be displayed:
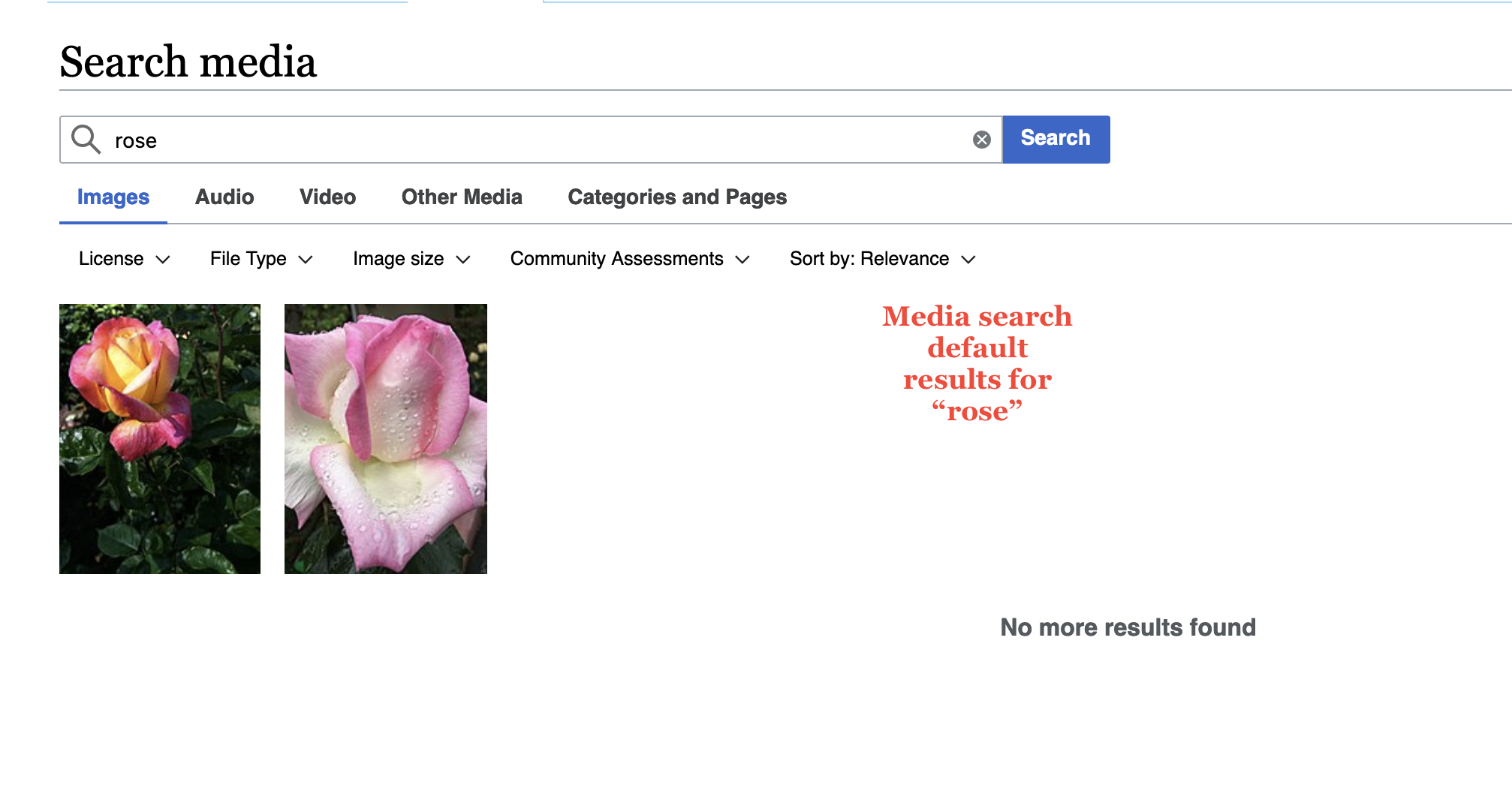
- Click on "Switch to a Special:Search" - Special:Search will display more results than Special:MediaSearch