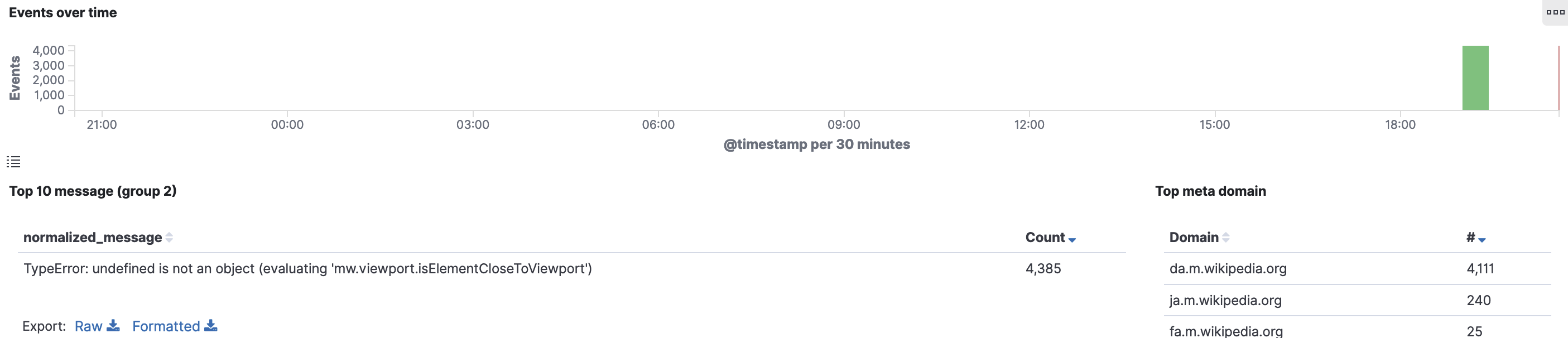
Following this week's train a sudden error spike mostly observed on da.m.wikipedia.org but also on other wikis e.g. Japanese Wikipedia. It seems to be limited to iOS (Safari and Chrome)
It quickly resolved itself. This week's train removed the mediawiki.viewport library from the code path, so this would suggest that old RelatedArticles code was loaded with the old list of module dependencies. This might point to a ResourceLoader issue.
Error
- mwversion: undefined
- reqId: undefined
- Find reqId in Logstash
- Find normalized_message in Logstash
normalized_message
TypeError: Cannot read properties of undefined (reading 'isElementCloseToViewport')
exception.trace