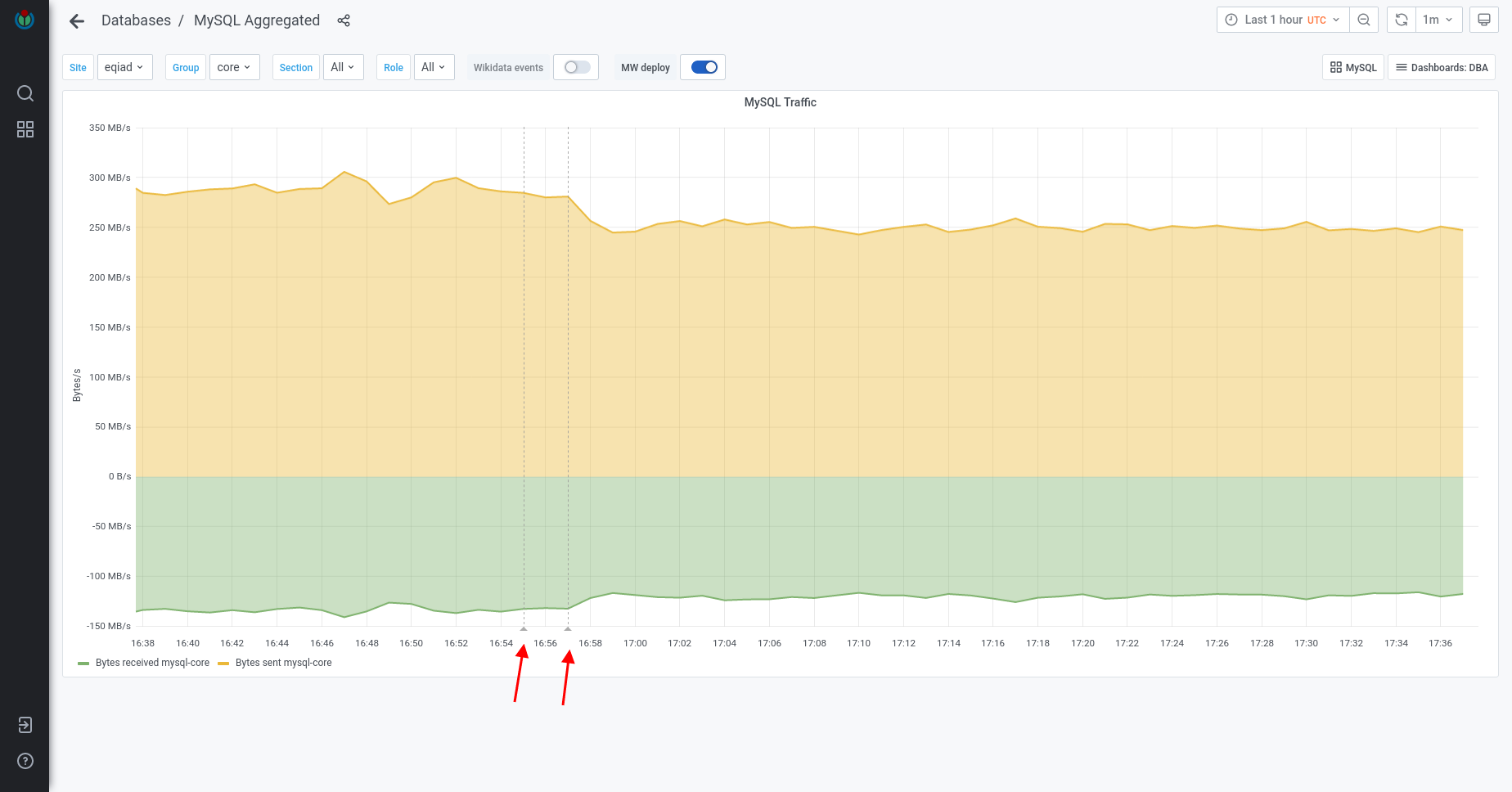
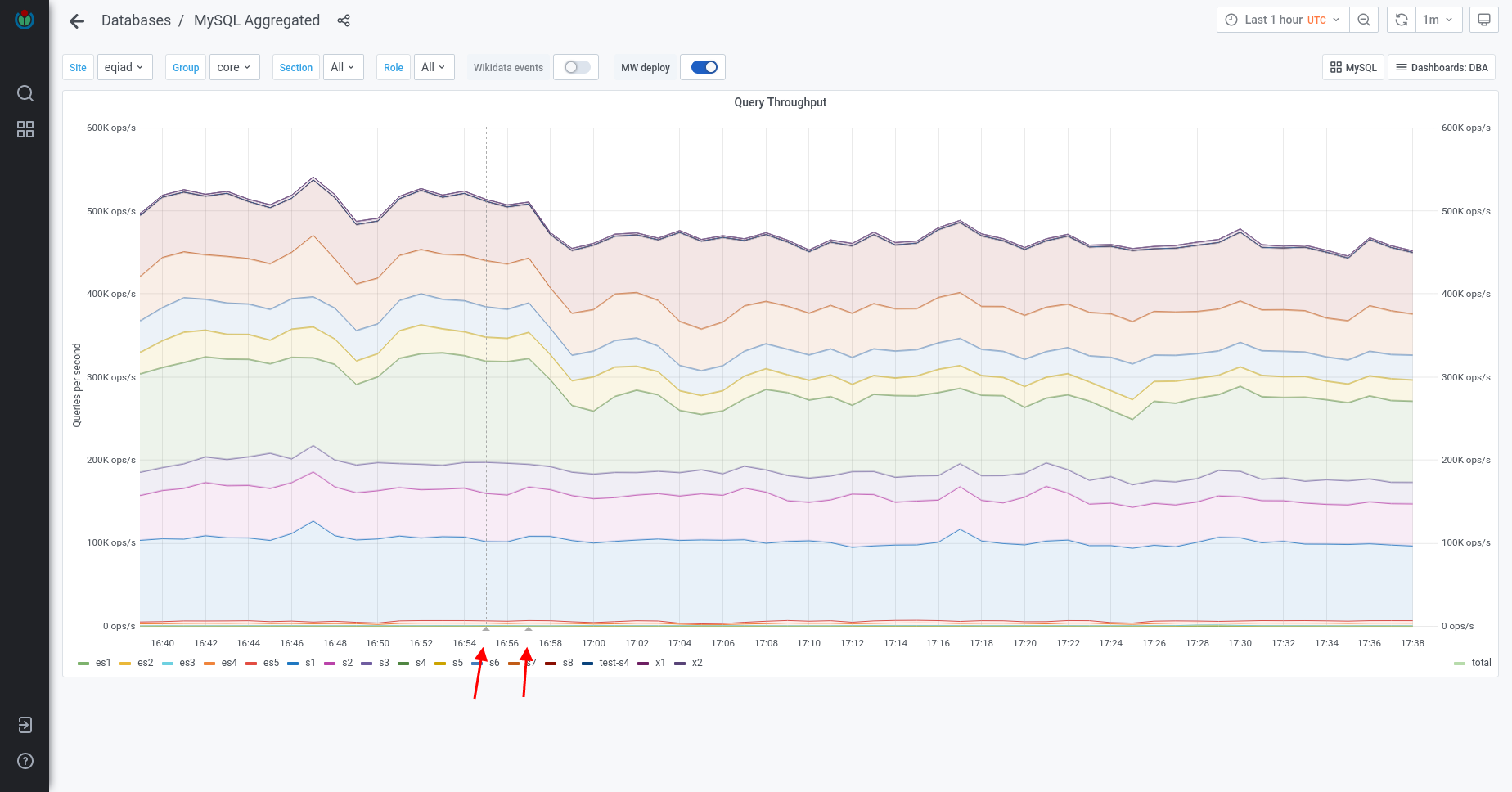
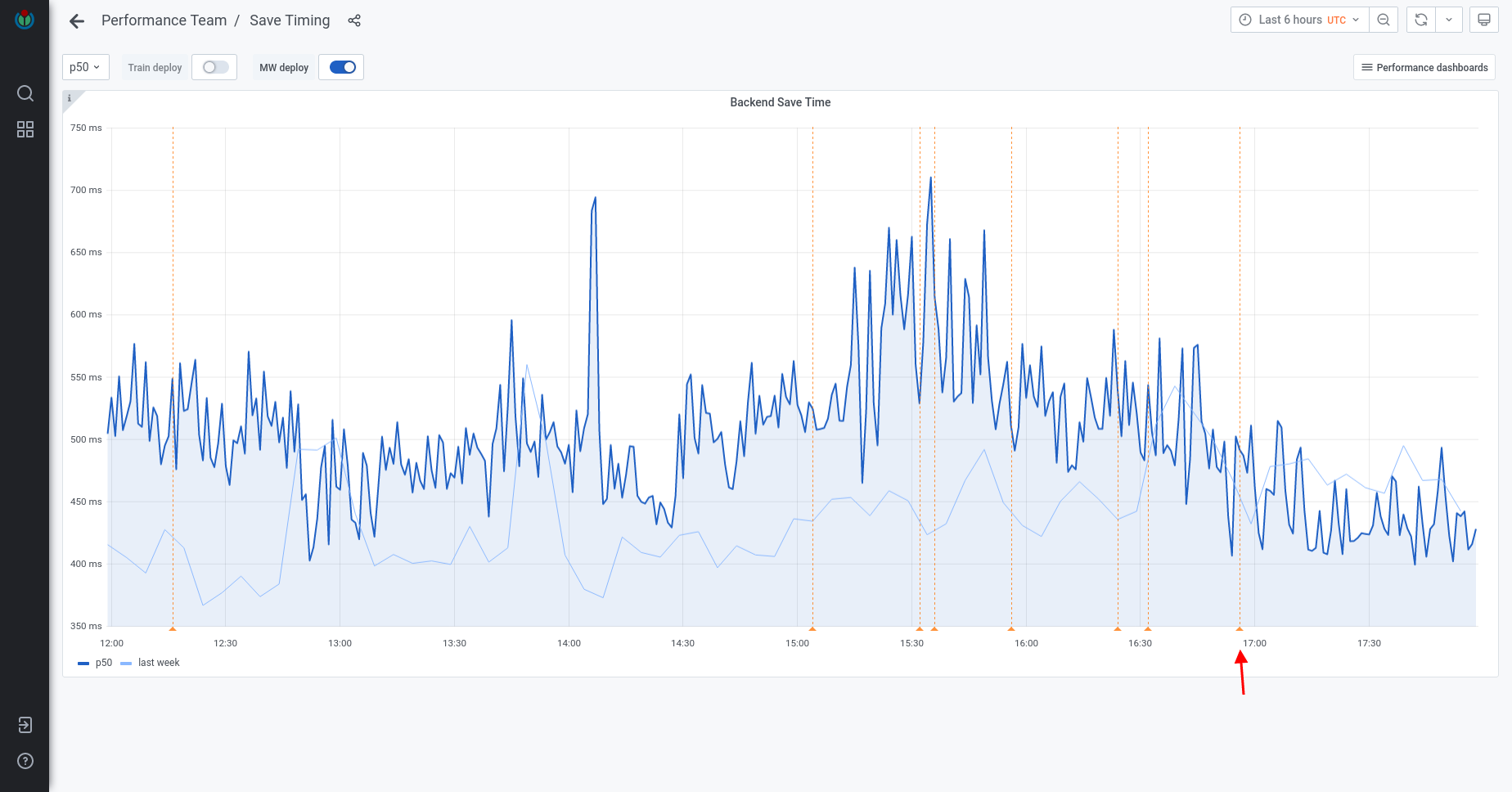
Parsing article of Alan Turing in English Wikipedia currently causes 325 queries list of them of which 207 are from MediaWiki\Revision\RevisionStore::loadSlotRecords. The function that calls this function (RevisionStore::newRevisionSlots) even has this note:
// XXX: do we need the same kind of caching here
It seems we indeed do need some caching for this, probably two layers, one WAN (long TTL) and one APCu (short TTL)